IRI कार्यक्षेत्र एक डेटाबेस में कई तालिकाओं में काम करने के लिए कई सुविधाएँ प्रदान करता है। इसमें निम्न के लिए विज़ार्ड शामिल हैं: प्रोफ़ाइल डेटाबेस; स्तंभों को वर्गीकृत करें; सबसेट, मास्क और माइग्रेट डेटा; परीक्षण डेटा उत्पन्न करें; आदि
IRI वर्कबेंच में उपकरण यह चुनने में मदद कर सकते हैं कि उन विजार्ड्स के लिए कौन सी तालिकाएँ उपलब्ध हैं, साथ ही किसी विशेष संबंध आरेख में, या पैटर्न या संवेदनशील मूल्यों के संग्रह के लिए तालिकाओं को स्कैन करने में। डेटाबेस में बहुत अधिक तालिकाओं के साथ, सभी डेटा और मेटाडेटा की कल्पना करना, चयन करना और स्कैन करना भारी पड़ सकता है। इस डेटा अधिभार समस्या का एक समाधान उन तालिकाओं को फ़िल्टर करना है जो किसी एक विशेष समय पर दिखाई देती हैं।
फ़िल्टर 
एक बार में टेबल के छोटे सेट के साथ काम करना आसान होता है। आम तौर पर, एक समय में कुछ सौ संबंधित टेबल उचित मात्रा में होते हैं। सौभाग्य से, IRI कार्यक्षेत्र के भीतर एक फ़िल्टर का उपयोग करके दिखाई गई तालिकाओं की सूची को सीमित करने के लिए एक तंत्र है।
फ़िल्टर की गई तालिकाएँ डेटा स्रोत एक्सप्लोरर की सूची से बाहर हैं, जो डेटाबेस संरचना में मुख्य दृश्य है। वे विजार्ड्स में चयन सूचियों में भी प्रकट नहीं होते हैं, और स्कीमा-वाइड डेटा स्कैन के दौरान छोड़ दिए जाते हैं, जिससे हार्ड-टू-फाइंड डेटा के वर्गीकरण में तेजी आती है। डेटा की एक प्रबंधनीय मात्रा के साथ तालिकाओं की संख्या को कुछ तार्किक सेट तक कम करना, उपयोगकर्ता के लिए कार्य पर ध्यान केंद्रित करना आसान बनाता है। किसी विशेष कार्य से संबंधित केवल उन तालिकाओं को दिखाने के लिए एकाधिक कनेक्शन प्रोफ़ाइल बनाई जा सकती हैं।
टेबल नाम से सरल फ़िल्टरिंग, एक्लिप्स डेटा टूल्स प्लेटफ़ॉर्म (DTP) प्रोजेक्ट की एक अंतर्निहित विशेषता है, जिसका उपयोग IRI वर्कबेंच में डेटाबेस एक्सेस के लिए किया जाता है। हालांकि, इसका उपयोग केवल उन तालिका नामों को निर्दिष्ट करने के लिए किया जा सकता है जो कुछ वर्ण स्ट्रिंग्स के साथ प्रारंभ, समाहित या समाप्त करते हैं या नहीं करते हैं। ऐसे समय होते हैं जब अधिक परिष्कृत दृष्टिकोण की आवश्यकता होती है।
डीटीपी प्रति स्कीमा के आधार पर या तो समावेश या बहिष्करण के लिए तालिका नामों की एक सूची का चयन करने की अनुमति देता है। इसमें सभी तालिका नामों को एक विज़ार्ड पृष्ठ में लोड करना शामिल है, और फिर सभी तालिका नामों को शामिल करने या बाहर करने के लिए चेकमार्क चयन लागू करना शामिल है। यह छोटी संख्या में तालिकाओं के लिए अच्छी तरह से काम करता है, लेकिन जब तालिकाओं की सूची हजारों, या दसियों-हजारों में बढ़ जाती है तो जल्दी से अप्रबंधनीय हो जाता है।
एक अपेक्षाकृत आसान काम है जो उपयोगकर्ता द्वारा प्रदान की गई बाहरी सूची के आधार पर नाम से तालिका चयन की अनुमति देता है। यह सूची किसी बाहरी उपकरण द्वारा, या SQL क्वेरी के परिणाम के रूप में उत्पन्न की जा सकती है। उदाहरण के तौर पर, यह पोस्ट चरण-दर-चरण दिखाएगा कि इसे कैसे पूरा किया जा सकता है।
तालिका सूची तैयार करें
तालिका सूची बनाने के लिए कई अलग-अलग क्वेरी विधियों का उपयोग किया जा सकता है। एक उपयोगी तरीका उन सभी तालिकाओं को फ़िल्टर करना है जिनमें डेटा की शून्य पंक्तियाँ हैं। हालांकि, इस विशेष उदाहरण में, तालिका नामों से मिलान के आधार पर फ़िल्टर में शामिल करने के लिए तालिकाओं की सूची निकालने के लिए SQL क्वेरी का उपयोग किया जाएगा। उदाहरण का अनुसरण करना आसान बनाने के लिए, चयनित तालिकाओं की सूची संक्षिप्त होगी। वही तकनीक बहुत लंबी सूची के आधार पर तालिकाओं को फ़िल्टर करने के लिए काम करेगी।
इस उदाहरण में रुचि की तालिकाओं के दो प्रारूप हैं, वे या तो अक्षर D से शुरू होते हैं, उसके बाद किसी भी वर्ण, और फिर एक अंडरस्कोर, या वे "IRI_" स्ट्रिंग से शुरू होते हैं। किसी भी पैटर्न के बाद किसी भी संख्या में अतिरिक्त वर्ण हो सकते हैं।
अंडरस्कोर को जानबूझकर रुचि के चरित्र के रूप में चुना गया था, क्योंकि संरचित क्वेरी भाषा (एसक्यूएल) में अंडरस्कोर एकल वाइल्डकार्ड वर्ण का प्रतिनिधित्व करता है। इसलिए, DTP फ़िल्टर एक्सप्रेशन या SQL स्टेटमेंट में अंडरस्कोर का उपयोग करना सीधा नहीं है।
यह उदाहरण ओरेकल डेटाबेस पर आधारित है, और यह दिखाएगा कि अंडरस्कोर कैरेक्टर से कैसे बचा जाए ताकि इसे क्वेरी के क्लॉज में शाब्दिक रूप से इस्तेमाल किया जा सके। क्वेरी जो उपरोक्त मानदंडों से मेल खाने वाली तालिका सूची तैयार करेगी:
SELECT TABLE_NAME
FROM ALL_TABLES
WHERE (
TABLE_NAME LIKE 'D_\_%' ESCAPE '\' OR
TABLE_NAME LIKE 'IRI\_%' ESCAPE '\'
)
AND OWNER LIKE 'SCOTT'
; अंडरस्कोर वर्ण से बचने के लिए बैकस्लैश के उपयोग पर ध्यान दें, जहां कभी भी इसकी शाब्दिक व्याख्या की जानी चाहिए। इस क्वेरी को SQL स्क्रैपबुक से निष्पादित किया जा सकता है आईआरआई कार्यक्षेत्र के भीतर फ़ाइल। परिणाम SQL परिणाम . में प्रदर्शित होंगे खिड़की देखें। SQL स्क्रैपबुक फ़ाइल संपादक में कर्सर के साथ, संदर्भ मेनू के लिए राइट क्लिक करें, और सभी निष्पादित करें चुनें ।
क्वेरी को किसी अन्य स्कीमा (स्वामी) के लिए भी अलग से चलाने की आवश्यकता होगी, जिसे फ़िल्टर की गई तालिका सूची की आवश्यकता होती है। विभिन्न स्कीमाओं के लिए क्वेरी परिणाम अलग रखे जाएंगे, और समान रूप से संसाधित किए जाएंगे।
परिणाम परिणाम 1 . पर देखे जा सकेंगे SQL परिणाम . में टैब दृश्य। उस दृश्य के संदर्भ मेनू से, निर्यात> वर्तमान परिणाम select चुनें . अगले संवाद में, परिणाम को CSV स्वरूपित फ़ाइल के रूप में कार्यक्षेत्र में प्रोजेक्ट फ़ोल्डर में निर्यात करें।

तालिका सूची से कनेक्शन प्रोफ़ाइल आयात फ़ाइल
एक्लिप्स डीटीपी एक विशेष रूप से परिभाषित एक्सएमएल फ़ाइल से एक या एक से अधिक डेटाबेस कनेक्शन प्रोफाइल आयात और निर्यात करने के लिए एक तंत्र प्रदान करता है। यहां प्रक्रिया यह होगी कि पहले आयात फ़ाइल में सम्मिलित करने के लिए CSV फ़ाइल तैयार की जाए, फिर उस कनेक्शन प्रोफ़ाइल को निर्यात किया जाए जिसे फ़िल्टर किया जाएगा, और अंत में फ़िल्टर स्थिति के रूप में तालिका नामों की सूची के साथ निर्यात फ़ाइल को संशोधित करना होगा।
आईआरआई वर्कबेंच टेक्स्ट एडिटर में सीएसवी डेटा फ़ाइल खोलें। CSV फ़ाइल को ठीक उसी रूप में स्वरूपित नहीं किया जाएगा जैसा इसकी आवश्यकता है। सबसे पहले, कॉलम हेडिंग वाली पहली पंक्ति को हटा दें। इसके बाद, तालिका नामों को दोहरे उद्धरण चिह्नों के बजाय एकल उद्धरण चिह्नों द्वारा तैयार किया जाना चाहिए, और प्रत्येक नाम को अल्पविराम से अलग करना चाहिए।
ढूंढें/बदलें लाने के लिए Ctrl+F दबाएं संवाद। F . के लिए निम्न पैटर्न दर्ज करें इंड: ^”(.*)”$ और आर ई इसके साथ स्थान: '\1', और नियमित ई . चुनें x दबाव विकल्प। बदलें . दबाएं ए मैं बटन और फिर फाइल को सेव करें। तालिका सूची फ़ाइल अब आयात फ़ाइल में उपयोग के लिए तैयार है।

अगला चरण तालिका नाम फ़िल्टर लागू किए बिना डेटाबेस कनेक्शन प्रोफ़ाइल का निर्यात तैयार करना है। कनेक्शन प्रोफ़ाइल निर्यात बटन डेटा स्रोत एक्सप्लोरर . पर है टूलबार देखें। यह एक टोकरी की तरह दिखता है जिसमें एक तीर ऊपर और दाईं ओर इशारा करता है। उस कनेक्शन प्रोफ़ाइल के आगे एक चेकमार्क रखें जिसे फ़िल्टर की आवश्यकता है, और प्रोजेक्ट कार्यक्षेत्र में .xml एक्सटेंशन के साथ फ़ाइल नाम निर्दिष्ट करें। यह भी सुनिश्चित करें कि फ़ाइल सामग्री एन्क्रिप्ट करें . को अनचेक करें फ़ाइल को सहेजने से पहले बॉक्स।

IRI कार्यक्षेत्र में XML निर्यात फ़ाइल खोलें। स्रोत . पर क्लिक करें XML संपादक विंडो के नीचे टैब। XML को कई पंक्तियों में प्रारूपित करने के लिए, इसे संपादित करना आसान बनाने के लिए Shift+Ctrl+F दबाएं. ऊपर के पास, प्रोफ़ाइल . के ठीक अंदर टैग, विशेषताओं वाली एक पंक्ति है id और नाम .
https://www.guidgen.com/ जैसी वेबसाइट पर जाएं और id में मान को बदलने के लिए एक नया GUID बनाएं गुण। नाम संपादित करें "फ़िल्टर" शब्द जोड़ने के लिए विशेषता, या कोई अन्य संकेतक जो नए कनेक्शन प्रोफ़ाइल की पहचान करेगा।
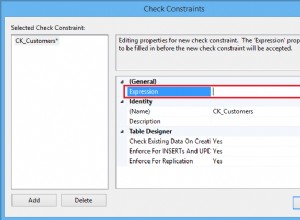
उदाहरण कनेक्शन प्रोफ़ाइल के पहले और बाद का दृश्य नीचे दिया गया है:
पहले:

इसके बाद:

इसके बाद, वह पंक्ति खोजें जिसमें:
<org.eclipse.datatools.connectivity.sqm.filterSettings />
अगर टैग के अंदर पहले से ही अतिरिक्त तत्व हैं, तो इसका मतलब है कि कनेक्शन प्रोफ़ाइल में स्कीमा पर पहले से ही फ़िल्टर लागू हैं। उन्हें जगह पर छोड़ा जा सकता है, और अतिरिक्त स्कीमा के लिए नए टेबल फ़िल्टर डाले जा सकते हैं।
अन्यथा, कनेक्शन प्रोफ़ाइल गुणों को फिर से निर्यात करने से पहले उन्हें निकालने के लिए संपादित किया जा सकता है। ऊपर की लाइन को निम्नलिखित से बदला जाना चाहिए:
<org.eclipse.datatools.connectivity.sqm.filterSettings> <property name="::SCOTT::DatatoolsTableFilterPredicate" value="IN()" /> </org.eclipse.datatools.connectivity.sqm.filterSettings>
तालिकाओं की सूची के साथ संपादित CSV डेटा फ़ाइल पर वापस जाएं। सभी टेक्स्ट का चयन करें, और इसे क्लिपबोर्ड पर कॉपी करें। एक्सएमएल फ़ाइल पर वापस लौटें, और क्लिपबोर्ड सामग्री को सीधे ऊपर के पाठ में कोष्ठकों के बीच चिपकाएँ। ध्यान दें कि यदि स्कीमा (स्वामी) का नाम संपत्ति . में है टैग, इसे फ़िल्टर किए जा रहे स्कीमा के नाम से मेल खाने के लिए बदला जाना चाहिए।
यदि तालिका सूचियों के साथ अतिरिक्त स्कीमा हैं, तो अतिरिक्त संपत्ति जोड़ने के लिए चरणों को दोहराएं टैग। यदि किसी तालिका सूची को शामिल करने के बजाय बाहर रखा जाना चाहिए, तो कीवर्ड डालें नहीं IN . शब्द के सामने . इस सरल उदाहरण में परिणामी एक्सएमएल नीचे दिखाया गया है। अधिक जटिल डेटाबेस में, तालिका नामों की हज़ारों पंक्तियाँ हो सकती हैं। जब सभी संपादन पूर्ण हो जाएं, तो फ़ाइल> इस रूप में सहेजें… . चुनें और फ़ाइल को एक नए नाम से सहेजें।

फ़िल्टर की गई कनेक्शन प्रोफ़ाइल आयात करें
नई बनाई गई फ़िल्टर की गई कनेक्शन प्रोफ़ाइल XML फ़ाइल को आयात किया जा सकता है, निर्यात की गई प्रोफ़ाइल की एक नई प्रतिलिपि बनाकर, फ़िल्टरिंग लागू करके। कनेक्शन प्रोफ़ाइल आयात बटन डेटा स्रोत एक्सप्लोरर . पर है टूलबार देखें, निर्यात बटन के ठीक बाईं ओर। यह एक टोकरी की तरह दिखता है जिसमें एक तीर नीचे और दाईं ओर इशारा करता है। उस XML फ़ाइल को ब्राउज़ करें जिसे तालिका सूची के साथ संशोधित किया गया था। यदि समान नाम वाली कोई प्रोफ़ाइल पहले से मौजूद है, तो उसे अधिलेखित करने के लिए बॉक्स को चेक करें।

अंत में, कनेक्शन प्रोफ़ाइल खोलना, और फ़िल्टर किए गए स्कीमा पर नेविगेट करने से केवल वे तालिकाएँ प्राप्त होती हैं जो सूची में दिखाई जा रही हैं: