यदि आपका आईटी इन्फ्रास्ट्रक्चर AWS पर चल रहा है, तो आपने शायद Amazon रिलेशनल डेटाबेस सर्विस (RDS) के बारे में सुना होगा, जो क्लाउड में रिलेशनल डेटाबेस को सेट करने, संचालित करने और स्केल करने का एक आसान तरीका है। यह हार्डवेयर प्रावधान, डेटाबेस सेटअप, पैचिंग और बैकअप जैसे समय लेने वाले प्रशासन कार्यों को स्वचालित करते हुए लागत प्रभावी और आकार बदलने योग्य क्षमता प्रदान करता है। RDS के लिए MySQL, MariaDB, PostgreSQL, Microsoft SQL Server और Oracle Server जैसे कई डेटाबेस इंजन ऑफ़रिंग हैं।
ClusterControl 1.7.3 RDS के समान कार्य करता है क्योंकि यह AWS प्लेटफॉर्म पर डेटाबेस क्लस्टर परिनियोजन, प्रबंधन, निगरानी और स्केलिंग का समर्थन करता है। यह Google क्लाउड प्लेटफ़ॉर्म और Microsoft Azure जैसे कई अन्य क्लाउड प्लेटफ़ॉर्म का भी समर्थन करता है। ClusterControl डेटाबेस टोपोलॉजी को समझता है और आपके डेटाबेस को नियंत्रित करने के लिए स्वचालित पुनर्प्राप्ति, टोपोलॉजी प्रबंधन और कई अन्य उन्नत सुविधाओं को करने में सक्षम है।
इस ब्लॉग पोस्ट में, हम Amazon Aurora, MySQL के लिए Amazon RDS, और ClusterControl द्वारा परिनियोजित और प्रबंधित एक MySQL प्रतिकृति सेटअप के लिए स्वचालित विफलता समय की तुलना करने जा रहे हैं। जिस प्रकार की विफलता हम करने जा रहे हैं, वह है गुलाम पदोन्नति की स्थिति में मास्टर नीचे चला जाता है। यह वह जगह है जहां सबसे अद्यतित दास डेटाबेस सेवा को फिर से शुरू करने के लिए क्लस्टर में मास्टर की भूमिका निभाता है।
हमारा विफलता परीक्षण
विफलता समय को मापने के लिए, हम एक सरल MySQL कनेक्ट-अपडेट परीक्षण चलाने जा रहे हैं, जिसमें SQL स्टेटमेंट स्थिति की गणना करने के लिए एक लूप है जो एकल डेटाबेस एंडपॉइंट से कनेक्ट होता है। स्क्रिप्ट इस तरह दिखती है:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
उपरोक्त बैश स्क्रिप्ट केवल एक MySQL होस्ट से जुड़ती है और बैश और MySQL क्लाइंट कमांड दोनों पर 1 सेकंड के टाइमआउट के साथ एक ही पंक्ति पर अपडेट करती है। टाइमआउट से संबंधित मापदंडों की आवश्यकता होती है, इसलिए हम डाउनटाइम को सेकंड में सही तरीके से माप सकते हैं क्योंकि MySQL क्लाइंट डिफ़ॉल्ट रूप से हमेशा MySQL प्रतीक्षा_टाइमआउट तक पहुंचने तक फिर से कनेक्ट होता है। हमने पहले से निम्न आदेश के साथ एक परीक्षण डेटासेट पॉप्युलेट किया है:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareस्क्रिप्ट रिपोर्ट करती है कि उपरोक्त क्वेरी सफल हुई (ठीक है) या विफल (विफल)। नमूना आउटपुट और नीचे दिखाए गए हैं।
MySQL के लिए Amazon RDS के साथ विफलता
हमारे परीक्षण में, हम निम्न विशिष्टताओं के साथ निम्नतम RDS पेशकश का उपयोग करते हैं:
- MySQL संस्करण:5.7.22
- vCPU:4
- रैम:16 जीबी
- भंडारण प्रकार:प्रावधानित IOPS (SSD)
- आईओपीएस:1000
- भंडारण:100Gib
- मल्टी-एजेड प्रतिकृति:हां
अमेज़ॅन आरडीएस आपके डीबी इंस्टेंस का प्रावधान करने के बाद, आप इंस्टेंस से कनेक्ट करने के लिए किसी भी मानक MySQL क्लाइंट एप्लिकेशन या उपयोगिता का उपयोग कर सकते हैं। कनेक्शन स्ट्रिंग में, आप होस्ट पैरामीटर के रूप में डीबी इंस्टेंस एंडपॉइंट से DNS पता निर्दिष्ट करते हैं, और पोर्ट पैरामीटर के रूप में डीबी इंस्टेंस एंडपॉइंट से पोर्ट नंबर निर्दिष्ट करते हैं।
अमेज़ॅन आरडीएस दस्तावेज़ीकरण पृष्ठ के अनुसार, आपके डीबी इंस्टेंस के नियोजित या अनियोजित आउटेज की स्थिति में, अमेज़ॅन आरडीएस स्वचालित रूप से किसी अन्य उपलब्धता क्षेत्र में एक स्टैंडबाय प्रतिकृति में बदल जाता है यदि आपने मल्टी-एजेड को सक्षम किया है। विफलता को पूरा करने में लगने वाला समय डेटाबेस गतिविधि और प्राथमिक डीबी इंस्टेंस अनुपलब्ध होने पर अन्य स्थितियों पर निर्भर करता है। विफलता का समय आमतौर पर 60-120 सेकंड होता है।
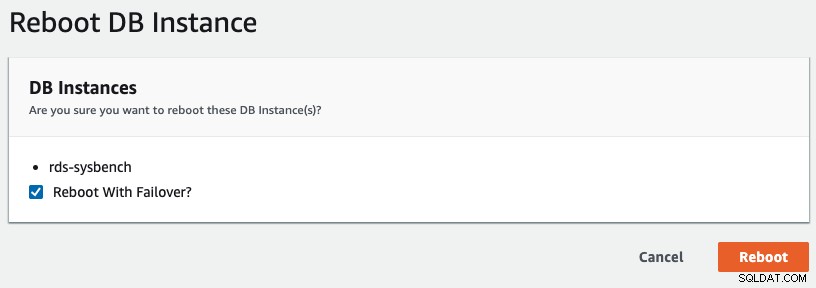
आरडीएस में मल्टी-एजेड फेलओवर शुरू करने के लिए, हमने "रीबूट विद फेलओवर" चेक के साथ एक रिबूट ऑपरेशन किया, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है:
हमारे आवेदन द्वारा निम्नलिखित को देखा जा रहा है:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...एप्लिकेशन पक्ष द्वारा देखा गया MySQL डाउनटाइम 03:41:09 से 03:41:36 तक शुरू हुआ था जो कुल मिलाकर लगभग 27 सेकंड है। RDS इवेंट से, हम देख सकते हैं कि मल्टी-एजेड फेलओवर वास्तविक डाउनटाइम के केवल 15 सेकंड बाद हुआ:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.एक बार जब नया डेटाबेस इंस्टेंस 03:41:33 के आसपास फिर से शुरू हुआ, तो MySQL सेवा लगभग 3 सेकंड बाद पहुंच योग्य थी।
MySQL के लिए Amazon Aurora के साथ विफलता
अमेज़ॅन ऑरोरा को आरडीएस के एक बेहतर संस्करण के रूप में माना जा सकता है, जिसमें कई उल्लेखनीय विशेषताएं हैं जैसे साझा भंडारण के साथ तेजी से प्रतिकृति, विफलता के दौरान कोई डेटा हानि नहीं, और भंडारण सीमा के 64TB तक। MySQL के लिए Amazon Aurora ओपन सोर्स MySQL संस्करण पर आधारित है, लेकिन अपने आप में ओपन सोर्स नहीं है; यह एक मालिकाना, बंद-स्रोत डेटाबेस है। यह MySQL प्रतिकृति (एक और केवल एक मास्टर, एकाधिक दासों के साथ) के साथ समान रूप से काम करता है और विफलता स्वचालित रूप से Amazon Aurora द्वारा नियंत्रित की जाती है।
Amazon Aurora FAQS के अनुसार, यदि आपके पास Amazon Aurora Replica है, उसी या किसी भिन्न उपलब्धता क्षेत्र में, विफल होने पर, Aurora आपके DB इंस्टेंस के लिए स्वस्थ प्रतिकृति को इंगित करने के लिए विहित नाम रिकॉर्ड (CNAME) को फ़्लिप करता है, जो अंदर है नया प्राथमिक बनने के लिए बारी को बढ़ावा दिया जाता है। स्टार्ट-टू-फिनिश, फेलओवर आमतौर पर 30 सेकंड के भीतर पूरा हो जाता है।
यदि आपके पास Amazon Aurora Replica (अर्थात एकल उदाहरण) नहीं है, तो Aurora पहले मूल उदाहरण के समान उपलब्धता क्षेत्र में एक नया DB इंस्टेंस बनाने का प्रयास करेगा। यदि ऐसा करने में असमर्थ है, तो Aurora एक भिन्न उपलब्धता क्षेत्र में एक नया DB इंस्टेंस बनाने का प्रयास करेगा। प्रारंभ से अंत तक, विफलता आमतौर पर 15 मिनट से कम समय में पूरी हो जाती है।
कनेक्शन खो जाने की स्थिति में आपके एप्लिकेशन को डेटाबेस कनेक्शन का पुनः प्रयास करना चाहिए।
Amazon Aurora आपके DB इंस्टेंस का प्रावधान करने के बाद, आपको दो एंडपॉइंट मिलेंगे, एक लेखक के लिए और एक पाठक के लिए। रीडर एंडपॉइंट डीबी क्लस्टर के लिए रीड-ओनली कनेक्शन के लिए लोड-बैलेंसिंग सपोर्ट प्रदान करता है। निम्नलिखित समापन बिंदु हमारे परीक्षण सेटअप से लिए गए हैं:
- लेखक - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- पाठक - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
हमारे परीक्षण में, हमने निम्नलिखित ऑरोरा स्पेक्स का उपयोग किया:
- उदाहरण प्रकार:db.r5.बड़ा
- MySQL संस्करण:5.7.12
- vCPU:2
- रैम:16 जीबी
- मल्टी-एजेड प्रतिकृति:हां
फ़ेलओवर ट्रिगर करने के लिए, बस राइटर इंस्टेंस चुनें -> क्रियाएँ -> फ़ेलओवर, जैसा कि निम्न स्क्रीनशॉट में दिखाया गया है:
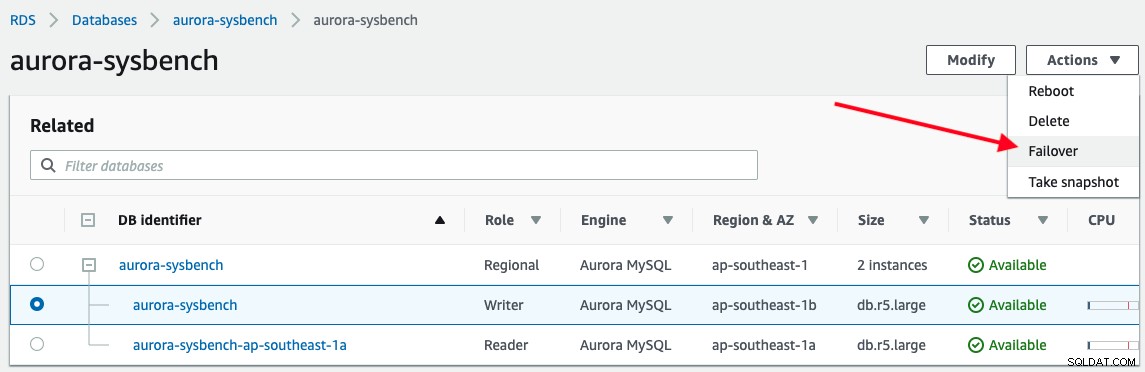
अरोड़ा राइटर एंडपॉइंट से कनेक्ट करते समय हमारे एप्लिकेशन द्वारा निम्नलिखित आउटपुट की सूचना दी जाती है :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...डेटाबेस डाउनटाइम 12:35:49 से 12:35:56 तक 7 सेकंड की कुल राशि के साथ शुरू किया गया था। यह काफी प्रभावशाली है।
Aurora प्रबंधन कंसोल से डेटाबेस इवेंट को देखते हुए, केवल ये दो इवेंट हुए:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedAurora को एक दास को स्वामी बनने के लिए बढ़ावा देने में, और स्वामी को एक दास बनने के लिए अवनत करने में अधिक समय नहीं लगता है। ध्यान दें कि सभी Aurora प्रतिकृतियां प्राथमिक आवृत्ति के साथ समान अंतर्निहित आयतन साझा करती हैं और इसका अर्थ है कि प्रतिकृति मिलीसेकंड में की जा सकती है क्योंकि प्राथमिक आवृत्ति द्वारा किए गए अद्यतन सभी Aurora प्रतिकृतियों के लिए तुरंत उपलब्ध होते हैं। इसलिए, इसमें न्यूनतम प्रतिकृति अंतराल है (अमेज़ॅन ने 100 मिलीसेकंड और उससे कम होने का दावा किया है)। इससे स्वास्थ्य जांच में लगने वाला समय काफी कम हो जाएगा और ठीक होने में लगने वाले समय में काफी सुधार होगा।
ClusterControl के साथ विफलता
इस उदाहरण में, हम एम5.एक्सलार्ज इंस्टेंस का उपयोग करते हुए अमेज़ॅन आरडीएस के साथ एक समान सेटअप की नकल करते हैं, बीच में एक प्रॉक्सीएसक्यूएल के साथ आरडीएस की तरह एकल एंडपॉइंट एक्सेस का उपयोग करके एप्लिकेशन से विफलता को स्वचालित करने के लिए। निम्नलिखित आरेख हमारी वास्तुकला को दर्शाता है:
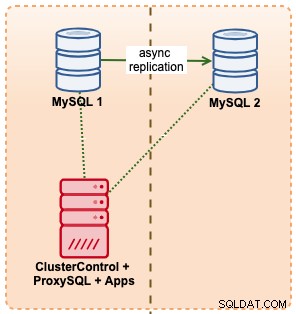
चूंकि हमारे पास डेटाबेस इंस्टेंस तक सीधी पहुंच है, इसलिए हम सक्रिय मास्टर पर केवल MySQL प्रक्रिया को मारकर एक स्वचालित विफलता को ट्रिगर करेंगे:
$ kill -9 $(pidof mysqld)उपरोक्त आदेश ने ClusterControl के अंदर एक स्वचालित पुनर्प्राप्ति को ट्रिगर किया:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.हमारे परीक्षण एप्लिकेशन के दृष्टिकोण से, ProxySQL होस्ट पोर्ट 6033 से कनेक्ट करते समय डाउनटाइम निम्नलिखित समय पर हुआ:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...रिकवरी जॉब इवेंट और हमारे एप्लिकेशन से आउटपुट दोनों को देखकर, MySQL डेटाबेस नोड क्लस्टर रिकवरी जॉब शुरू होने से 4 सेकंड पहले, 11:08:28 से 11:08:39 तक, 11 सेकंड के कुल MySQL डाउनटाइम के साथ नीचे था। . ClusterControl के बारे में सबसे प्रभावशाली चीजों में से एक है, आप पुनर्प्राप्ति प्रगति को ट्रैक कर सकते हैं कि विफलता के दौरान ClusterControl द्वारा क्या कार्रवाई की जा रही है और क्या किया जा रहा है। यह पारदर्शिता का एक ऐसा स्तर प्रदान करता है जिसे आप क्लाउड प्रदाताओं द्वारा किसी भी डेटाबेस पेशकश के साथ प्राप्त करने में सक्षम नहीं होंगे।
MySQL/MariaDB/PostgreSQL प्रतिकृति के लिए, ClusterControl आपको निम्न उन्नत कॉन्फ़िगरेशन और पैरामीटर के समर्थन से अपने डेटाबेस के विरुद्ध अधिक परिष्कृत करने की अनुमति देता है:
- मास्टर-मास्टर प्रतिकृति टोपोलॉजी प्रबंधन
- श्रृंखला प्रतिकृति टोपोलॉजी प्रबंधन
- टोपोलॉजी व्यूअर
- श्वेतसूची/ब्लैकलिस्ट दासों को मास्टर के रूप में पदोन्नत किया जाएगा
- गलत लेनदेन चेकर
- पूर्व/पोस्ट, सफलता/असफल विफलता/स्विचओवर ईवेंट बाहरी स्क्रिप्ट के साथ जुड़े हुए हैं
- त्रुटि पर स्लेव को स्वचालित रूप से फिर से बनाना
- मौजूदा बैकअप से स्लेव को स्केल आउट करें
विफलता समय सारांश
विफलता समय के संदर्भ में, MySQL के लिए Amazon RDS Aurora 7 सेकंड के साथ स्पष्ट विजेता है , उसके बाद ClusterControl 11 सेकंड और MySQL के लिए Amazon RDS 27 सेकंड . के साथ .
ध्यान दें कि यह सबसे तेज़ पुनर्प्राप्ति समय मापने के लिए एक ग्राहक और प्रति सेकंड एक लेनदेन के साथ एक साधारण परीक्षण है। बड़े लेन-देन या एक लंबी पुनर्प्राप्ति प्रक्रिया विफलता समय को बढ़ा सकती है, उदाहरण के लिए, लंबे समय तक चलने वाले लेनदेन में MySQL को बंद करते समय वापस आने में लंबा समय लग सकता है।