हमने हाल ही में कई ब्लॉग लिखे हैं जिसमें बताया गया है कि विभिन्न क्लाउड प्रदाता डेटाबेस विफलता को कैसे संभालते हैं। हमने Amazon Aurora, Amazon RDS और ClusterControl में फ़ेलओवर प्रदर्शन की तुलना की, Amazon RDS में फ़ेलओवर व्यवहार का परीक्षण किया, और Google क्लाउड प्लेटफ़ॉर्म पर भी। हालांकि ये सेवाएं फ़ेलओवर के मामले में बढ़िया विकल्प प्रदान करती हैं, हो सकता है कि वे प्रत्येक एप्लिकेशन के लिए सही न हों।
इस ब्लॉग पोस्ट में हम मैन्युअल रूप से या क्लस्टर कंट्रोल जैसे डेटाबेस प्रबंधन प्लेटफॉर्म का उपयोग करके पर्यावरण को डिजाइन करने की तुलना में डीबीएएएस समाधानों का उपयोग करने के पेशेवरों और विपक्षों का विश्लेषण करने में थोड़ा समय व्यतीत करेंगे।
प्रबंधित समाधानों के साथ उच्च उपलब्धता डेटाबेस लागू करना
मौजूदा समाधानों का उपयोग करने का प्राथमिक कारण उपयोग में आसानी है। आप केवल कुछ ही क्लिक में स्वचालित विफलता के साथ अत्यधिक उपलब्ध समाधान परिनियोजित कर सकते हैं। विभिन्न उपकरणों को एक साथ संयोजित करने, डेटाबेस को हाथ से प्रबंधित करने, उपकरणों को तैनात करने, स्क्रिप्ट लिखने, निगरानी को डिजाइन करने, या किसी अन्य डेटाबेस प्रबंधन संचालन की कोई आवश्यकता नहीं है। सब कुछ पहले से ही है। यह सीखने की अवस्था को गंभीरता से कम कर सकता है और डेटाबेस के लिए अत्यधिक उपलब्ध वातावरण स्थापित करने के लिए कम अनुभव की आवश्यकता होती है; मूल रूप से सभी को ऐसे सेटअप परिनियोजित करने की अनुमति देता है।
इन समाधानों के साथ अधिकांश मामलों में, विफलता प्रक्रिया को उचित समय के भीतर निष्पादित किया जाता है। यह अमेज़ॅन ऑरोरा की तरह तेज़ या Google क्लाउड प्लेटफ़ॉर्म SQL नोड्स की तरह कुछ धीमा हो सकता है। अधिकांश मामलों के लिए, इस प्रकार के परिणाम स्वीकार्य हैं।
नीचे की रेखा। यदि आप 30 - 60 सेकंड का डाउनटाइम स्वीकार कर सकते हैं, तो आपको किसी भी डीबीएएएस प्लेटफॉर्म का उपयोग करना ठीक होना चाहिए।
HA के लिए प्रबंधित समाधान का उपयोग करने का नकारात्मक पहलू
जबकि DBaaS समाधान उपयोग में आसान होते हैं, उनमें कुछ गंभीर कमियां भी होती हैं। शुरुआत के लिए, विचार करने के लिए हमेशा एक विक्रेता लॉक-इन घटक होता है। एक बार जब आप Amazon Web Services में क्लस्टर परिनियोजित करते हैं तो उस प्रदाता से बाहर माइग्रेट करना काफी मुश्किल होता है। भौतिक बैकअप के माध्यम से पूर्ण डेटासेट डाउनलोड करने के लिए कोई आसान तरीका नहीं है। अधिकांश प्रदाताओं के साथ, केवल मैन्युअल रूप से निष्पादित तार्किक बैकअप उपलब्ध हैं। निश्चित रूप से, इसे प्राप्त करने के लिए हमेशा विकल्प होते हैं, लेकिन यह आमतौर पर एक जटिल, समय लेने वाली प्रक्रिया है, जिसके लिए अभी भी कुछ डाउनटाइम की आवश्यकता हो सकती है।
अमेज़ॅन आरडीएस जैसे प्रदाता का उपयोग करना भी सीमाओं के साथ आता है। कुछ क्रियाएं आसानी से नहीं की जा सकतीं जो पूरी तरह से उपयोगकर्ता-नियंत्रित तरीके (जैसे एडब्ल्यूएस ईसी 2) में तैनात वातावरण पर पूरा करना बहुत आसान होगा। इनमें से कुछ सीमाएं पहले से ही अन्य ब्लॉगों में शामिल की गई हैं, लेकिन संक्षेप में यह है कि कोई भी DBaaS सेवा आपको नियमित MySQL GTID- आधारित प्रतिकृति के समान लचीलापन नहीं देती है। आप किसी भी गुलाम को बढ़ावा दे सकते हैं, आप किसी भी अन्य नोड से हर नोड को फिर से गुलाम बना सकते हैं ... लगभग हर क्रिया संभव है। RDS जैसे टूल के साथ आप डिज़ाइन-प्रेरित सीमाओं का सामना करते हैं जिन्हें आप बायपास नहीं कर सकते।
समस्या प्रदर्शन विवरण को समझने की क्षमता के साथ भी है। जब आप अपना स्वयं का अत्यधिक उपलब्ध सेटअप डिज़ाइन करते हैं, तो आप संभावित प्रदर्शन समस्याओं के बारे में जानकार हो जाते हैं जो दिखाई दे सकते हैं। दूसरी ओर, आरडीएस और इसी तरह के वातावरण बहुत अधिक "ब्लैक बॉक्स" हैं। हां, हमने सीखा है कि अमेज़ॅन आरडीएस मास्टर की छाया प्रति बनाने के लिए डीआरबीडी का उपयोग करता है, हम जानते हैं कि अरोड़ा बहुत तेजी से विफलताओं को लागू करने के लिए साझा, प्रतिकृति भंडारण का उपयोग करता है। यह सिर्फ एक सामान्य ज्ञान है। हम यह नहीं बता सकते कि उन समाधानों के प्रदर्शन प्रभाव क्या हैं जो हम आकस्मिक रूप से नोटिस कर सकते हैं। उनसे जुड़े सामान्य मुद्दे क्या हैं? वे समाधान कितने स्थिर हैं? समाधान के पीछे केवल डेवलपर्स ही निश्चित रूप से जानते हैं।
DBaaS समाधान का विकल्प क्या है?
आपको आश्चर्य हो सकता है, क्या DBaaS का कोई विकल्प है? आखिरकार, प्रबंधित सेवा को चलाना इतना सुविधाजनक है जहाँ आप UI के माध्यम से अधिकांश विशिष्ट क्रियाओं तक पहुँच प्राप्त कर सकते हैं। आप बैकअप बना सकते हैं और पुनर्स्थापित कर सकते हैं, फ़ेलओवर आपके लिए स्वचालित रूप से नियंत्रित किया जाता है। पर्यावरण उपयोग में आसान है जो उन कंपनियों के लिए सम्मोहक हो सकता है जिनके पास डेटाबेस से निपटने के लिए समर्पित और अनुभवी कर्मचारी नहीं हैं।
ClusterControl क्लाउड-आधारित DBaaS सेवाओं के लिए एक बढ़िया विकल्प प्रदान करता है। यह आपको एक ग्राफिकल यूजर इंटरफेस प्रदान करता है, जिसका उपयोग ओपन सोर्स डेटाबेस को तैनात करने, प्रबंधित करने और मॉनिटर करने के लिए किया जा सकता है।
कुछ क्लिक में आप स्वचालित विफलता (अधिकांश DBaaS प्रस्तावों की तुलना में तेज़), बैकअप प्रबंधन, उन्नत निगरानी और बाहरी उपकरणों के साथ एकीकरण जैसी अन्य सुविधाओं के साथ आसानी से अत्यधिक उपलब्ध डेटाबेस क्लस्टर को तैनात कर सकते हैं। (जैसे स्लैक या पेजरड्यूटी) या अपग्रेड प्रबंधन। यह सब वेंडर लॉक-इन से पूरी तरह परहेज करते हुए।
ClusterControl परवाह नहीं करता है कि आपके डेटाबेस कहाँ स्थित हैं, जब तक कि यह SSH का उपयोग करके उनसे कनेक्ट हो सकता है। आपके पास क्लाउड, ऑन-प्रिमाइसेस या एकाधिक क्लाउड प्रदाताओं के मिश्रित वातावरण में सेटअप हो सकते हैं। जब तक कनेक्टिविटी है, तब तक ClusterControl पर्यावरण का प्रबंधन करने में सक्षम होगा। अपने इच्छित समाधानों का उपयोग करना (और न कि जिन्हें आप परिचित नहीं हैं और जिनके बारे में आप नहीं जानते हैं) आपको किसी भी समय पर्यावरण पर पूर्ण नियंत्रण रखने की अनुमति देता है।
ClusterControl के साथ आपने जो भी सेटअप परिनियोजित किया है, आप उसे अधिक पारंपरिक, मैन्युअल या स्क्रिप्टेड तरीके से आसानी से प्रबंधित कर सकते हैं। ClusterControl आपको कमांड लाइन इंटरफ़ेस भी प्रदान करता है, जो आपको ClusterControl द्वारा निष्पादित कार्यों को अपनी शेल स्क्रिप्ट में शामिल करने देगा। आपके पास वह सारा नियंत्रण है जो आप चाहते हैं - कुछ भी ब्लैक बॉक्स नहीं है, पर्यावरण के हर टुकड़े को ओपन सोर्स सॉल्यूशंस का उपयोग करके बनाया जाएगा और क्लस्टरकंट्रोल द्वारा तैनात किया जाएगा।
आइए एक नजर डालते हैं कि आप कितनी आसानी से ClusterControl का उपयोग करके MySQL प्रतिकृति क्लस्टर को तैनात कर सकते हैं। मान लें कि आपके पास ClusterControl होस्ट से SSH के माध्यम से सुलभ एक उदाहरण और अन्य सभी नोड्स पर स्थापित ClusterControl के साथ तैयार किया गया वातावरण है।
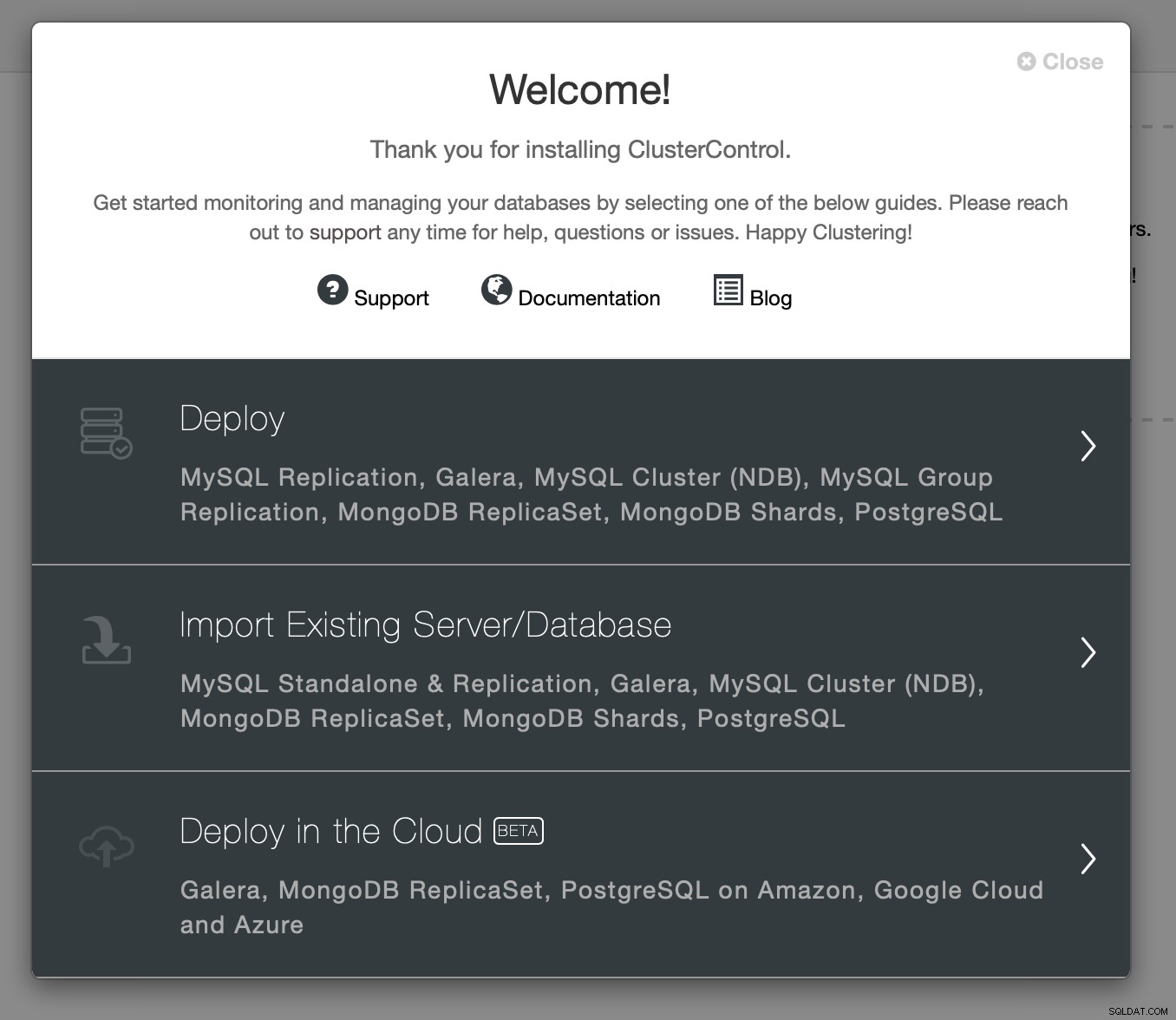
हम "तैनाती" विज़ार्ड चुनने के साथ शुरुआत करेंगे।
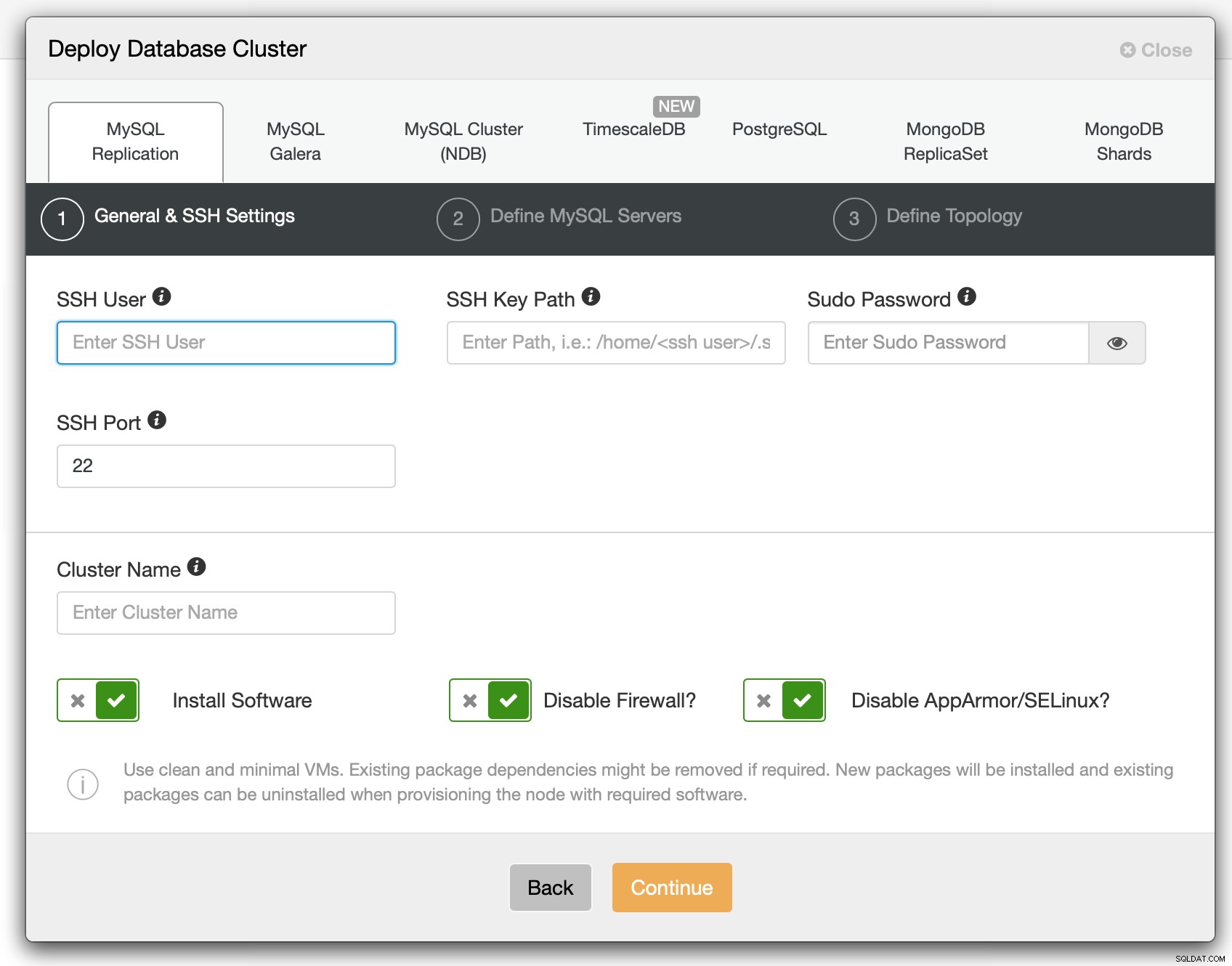
पहले चरण में हमें यह परिभाषित करना होगा कि ClusterControl को नोड्स से कैसे कनेक्ट होना चाहिए जिस पर डेटाबेस तैनात किए जाने हैं। रूट एक्सेस या sudo (पासवर्ड के साथ या बिना) दोनों समर्थित हैं।
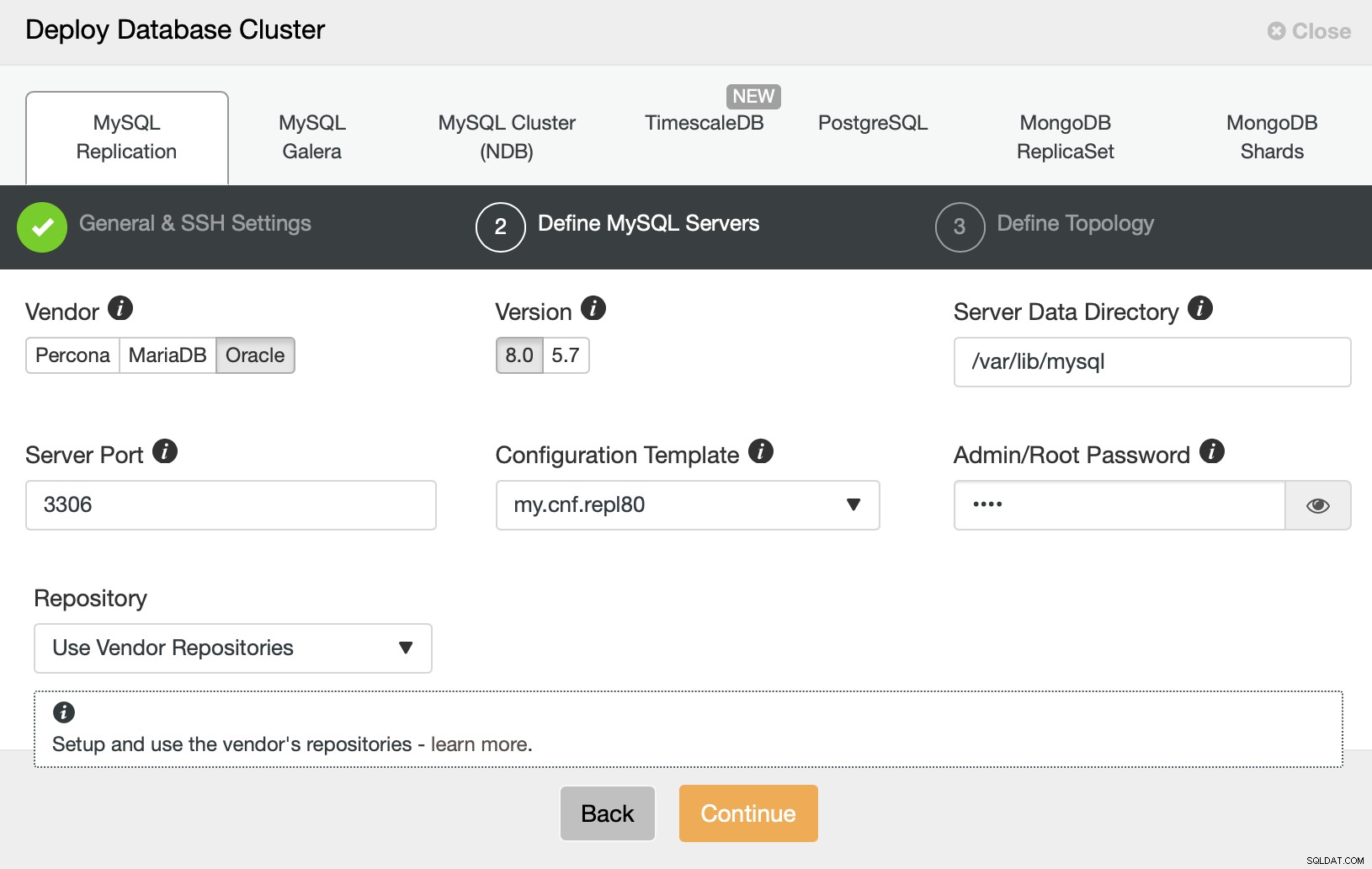
फिर, हम एक विक्रेता, संस्करण चुनना चाहते हैं और इसके लिए पासवर्ड पास करना चाहते हैं हमारे MySQL डेटाबेस में व्यवस्थापकीय उपयोगकर्ता।
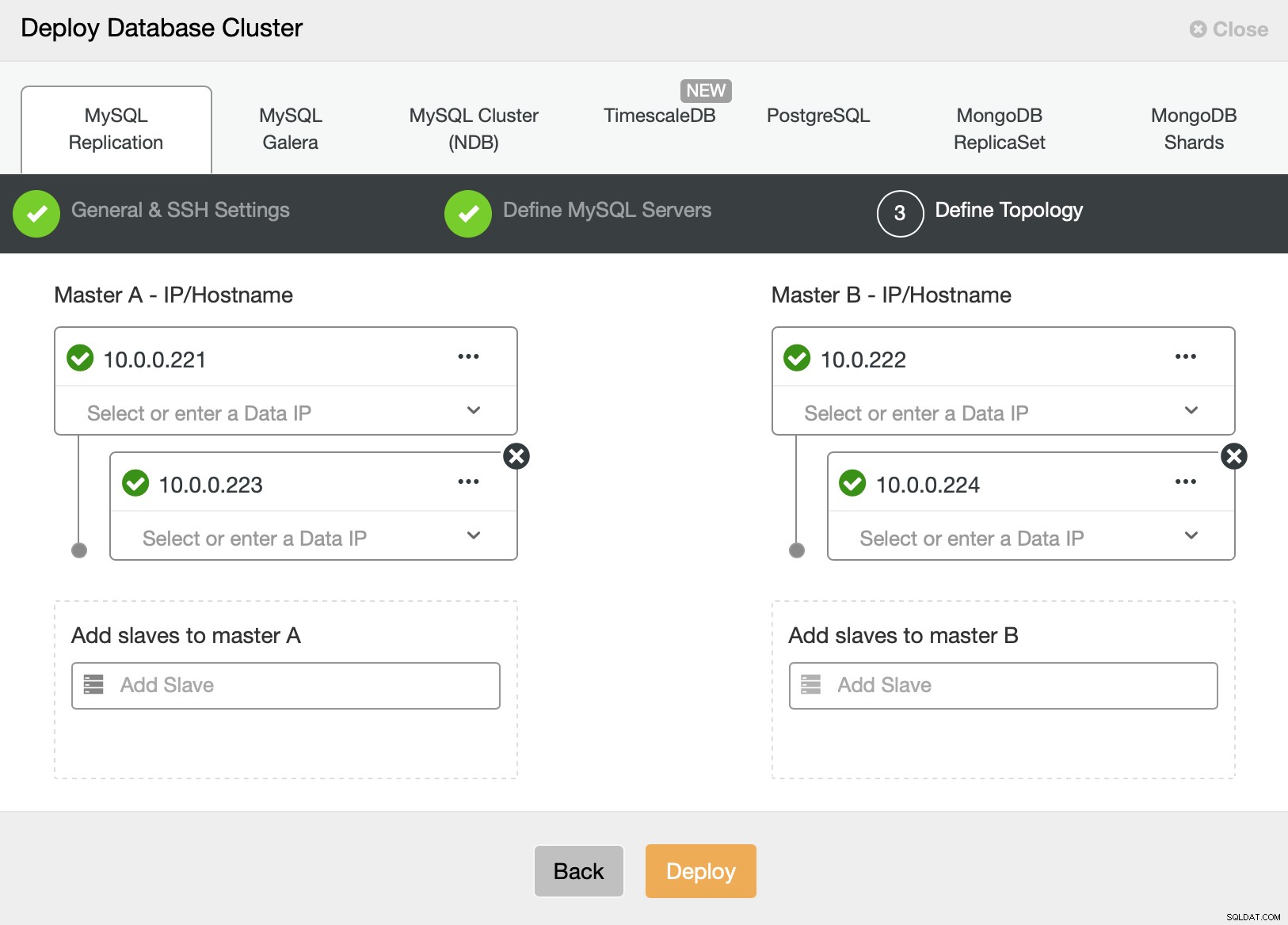
आखिरकार, हम अपने नए क्लस्टर के लिए टोपोलॉजी को परिभाषित करना चाहते हैं। जैसा कि आप देख सकते हैं, यह पहले से ही काफी जटिल सेटअप है, इसके विपरीत जिसे आप AWS RDS या GCP SQL नोड का उपयोग करके परिनियोजित कर सकते हैं।
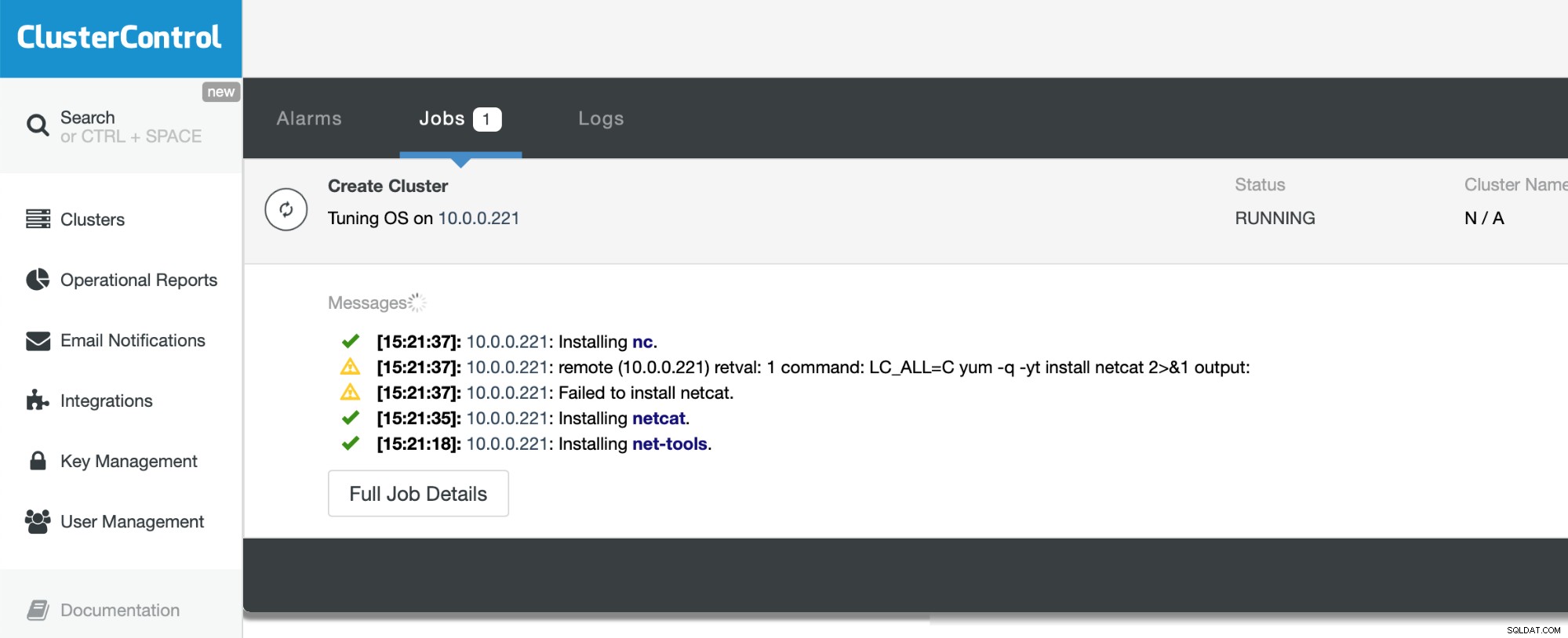
अब हमें बस इतना करना है कि प्रक्रिया पूरी होने का इंतजार करना है। ClusterControl अपने द्वारा परिनियोजित किए जा रहे परिवेश को समझने और डेटाबेस सहित पैकेजों के आवश्यक सेट को स्थापित करने की पूरी कोशिश करेगा।

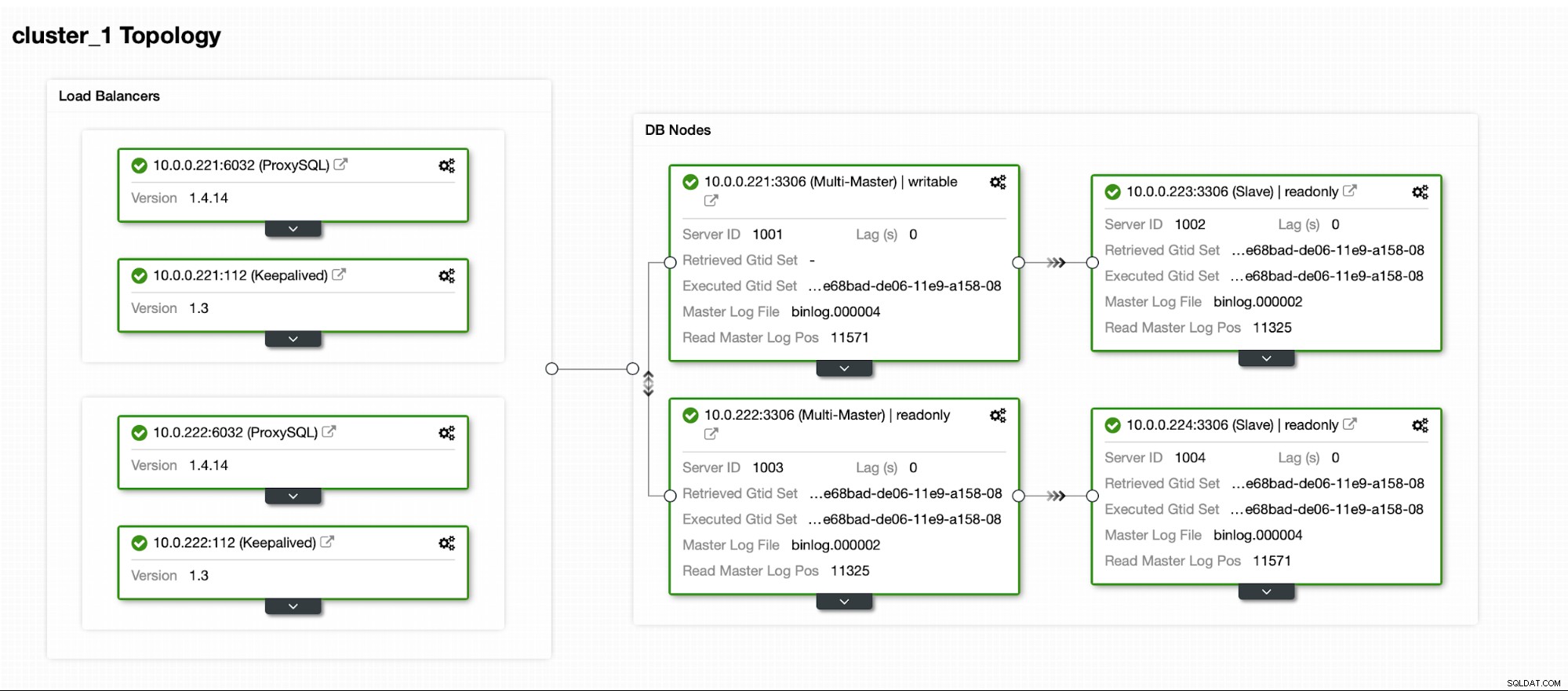
क्लस्टर के चालू होने के बाद, आप परिनियोजन के साथ आगे बढ़ सकते हैं प्रॉक्सी परत (जो आपके आवेदन को डेटाबेस परत में प्रवेश के एकल बिंदु के साथ प्रदान करेगी)। यह कमोबेश DBaaS के साथ पर्दे के पीछे होता है, जहां आपके पास डेटाबेस क्लस्टर से जुड़ने के लिए समापन बिंदु भी होते हैं। विशेष प्रतिकृतियों तक पहुँचने के लिए लेखन और एकाधिक समापन बिंदुओं के लिए एकल समापन बिंदु का उपयोग करना काफी सामान्य है।
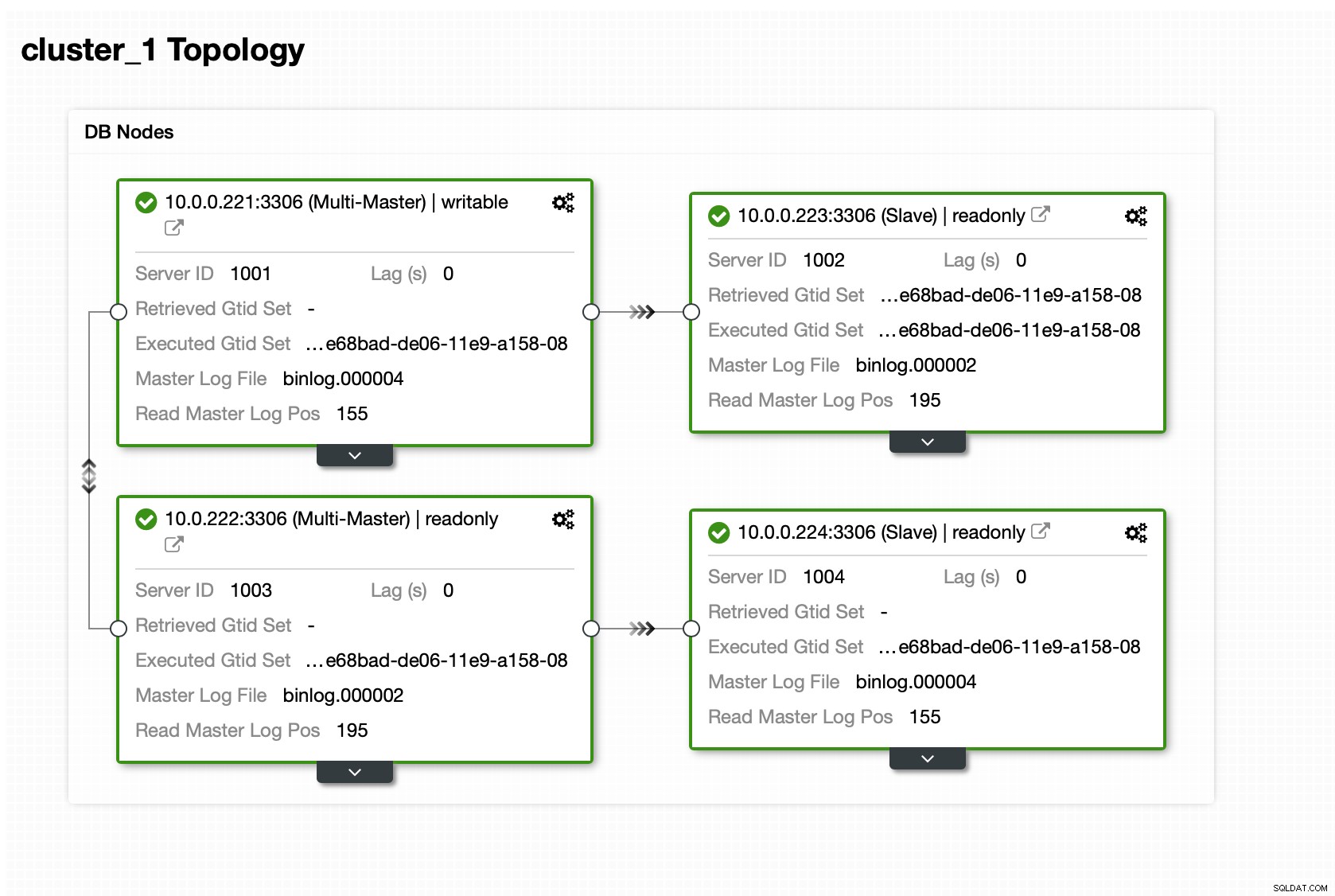
यहां हम ProxySQL का उपयोग करेंगे, जो हमारे लिए गंदा काम करेगा - यह टोपोलॉजी को समझेगा, केवल मास्टर को लिखता है और हमारे पास मौजूद सभी प्रतिकृतियों में शेष-पठन-योग्य प्रश्नों को लोड करता है।
ProxySQL को परिनियोजित करने के लिए हम मैनेज -> लोड बैलेंसर्स पर जाएंगे।
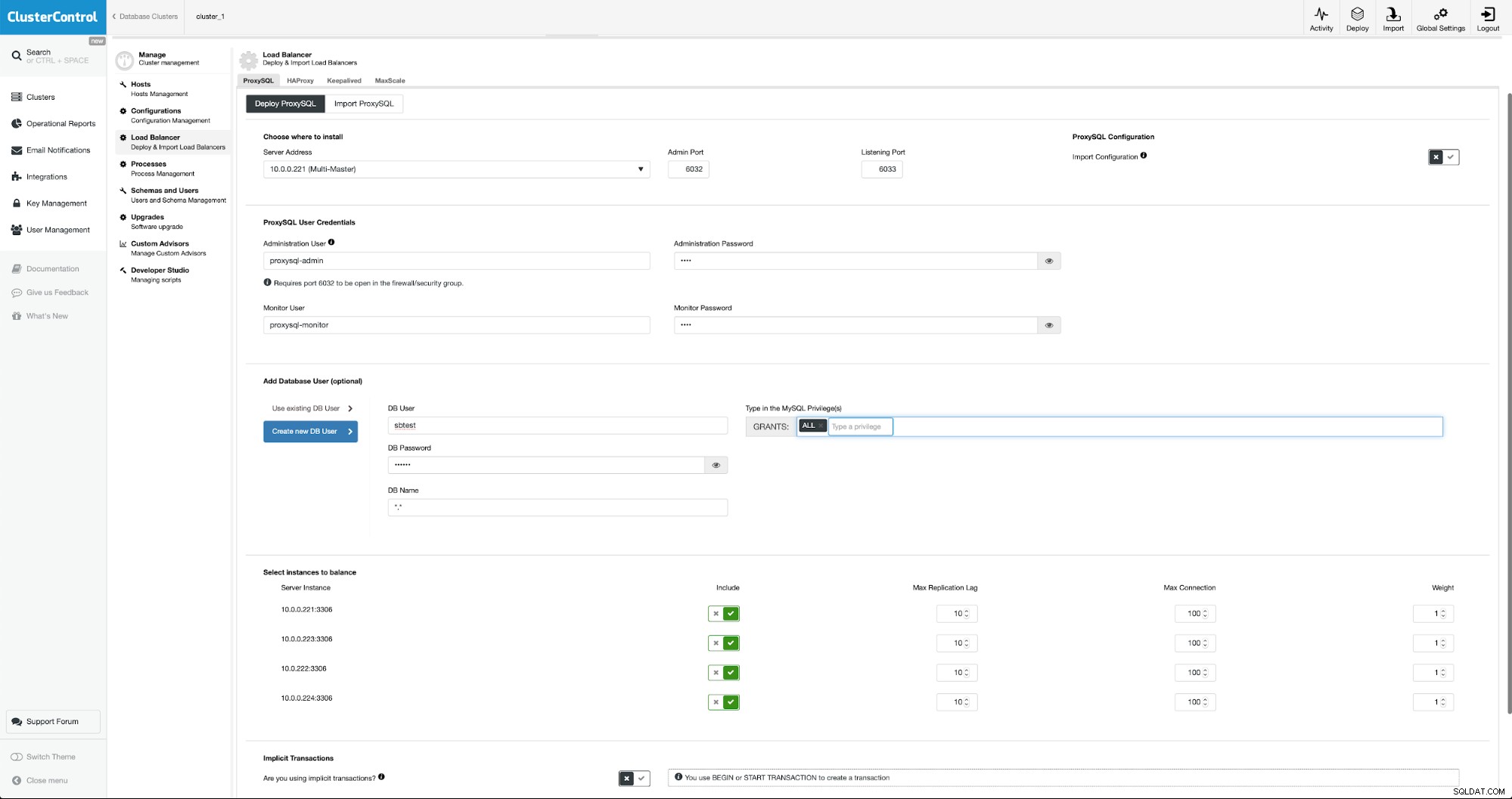
हमें सभी आवश्यक फ़ील्ड भरने होंगे:पर तैनात करने के लिए होस्ट, के लिए क्रेडेंशियल प्रशासनिक और निगरानी उपयोगकर्ता, हम मौजूदा उपयोगकर्ता को MySQL से ProxySQL में आयात कर सकते हैं या एक नया बना सकते हैं। ProxySQL के बारे में सभी विवरण हमारे ब्लॉग अनुभाग में कई ब्लॉगों में आसानी से मिल सकते हैं।
हम चाहते हैं कि उच्च उपलब्धता सुनिश्चित करने के लिए कम से कम दो ProxySQL नोड्स तैनात किए जाएं। फिर, एक बार जब वे तैनात हो जाते हैं, तो हम ProxySQL के शीर्ष पर Keepalived को तैनात करेंगे। यह सुनिश्चित करेगा कि वर्चुअल आईपी कॉन्फ़िगर किया जाएगा और प्रॉक्सीएसक्यूएल इंस्टेंस में से एक को इंगित करेगा, जब तक कि कम से कम एक स्वस्थ नोड होगा।
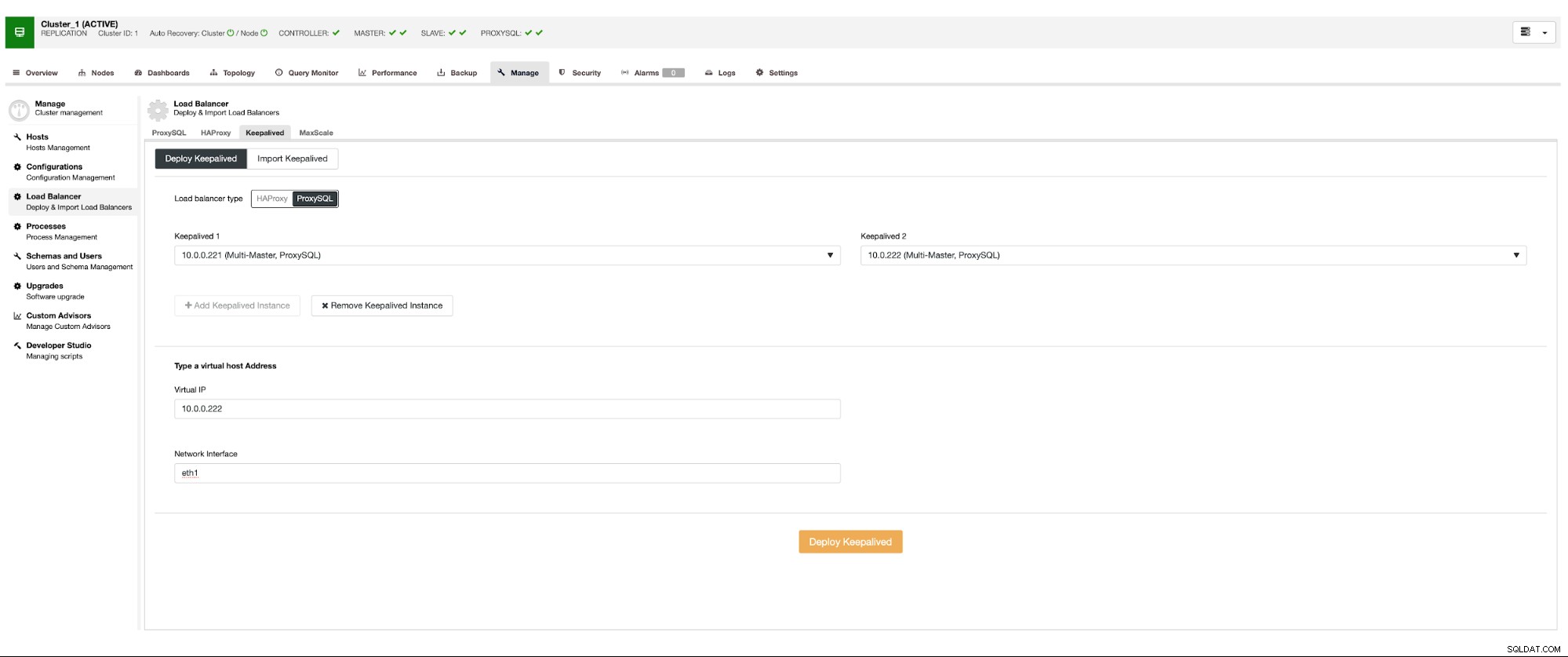
यदि आप क्लाउड वातावरण के साथ जाते हैं जहां रूटिंग काम करती है तो यहां एकमात्र संभावित समस्या है। इस तरह से कि आप आसानी से एक नेटवर्क इंटरफ़ेस नहीं ला सकते। ऐसे मामले में आपको Keepalived के कॉन्फ़िगरेशन को संशोधित करना होगा, 'notify_master' स्क्रिप्ट को पेश करना होगा और एक स्क्रिप्ट का उपयोग करना होगा, जो आवश्यक IP परिवर्तन करेगा - EC2 के मामले में इसे एक होस्ट से Elastic IP को अलग करना होगा और इसे संलग्न करना होगा। अन्य मेजबान।
ClusterControl द्वारा परिनियोजित सेटअपों में व्यापक रूप से परीक्षण किए गए ओपन सोर्स सॉफ़्टवेयर का उपयोग करके ऐसा करने के तरीके के बारे में बहुत सारे निर्देश हैं। आप आसानी से अतिरिक्त जानकारी, टिप्स और कैसे-कैसे प्राप्त कर सकते हैं जो आपके विशेष परिवेश के लिए प्रासंगिक हैं।
निष्कर्ष
हमें उम्मीद है कि आपको यह ब्लॉग पोस्ट जानकारीपूर्ण लगी होगी। यदि आप ClusterControl का परीक्षण करना चाहते हैं, तो यह 30 दिन के उद्यम परीक्षण के साथ आता है जहाँ आपके पास सभी सुविधाएँ उपलब्ध हैं। आप इसे मुफ्त में डाउनलोड कर सकते हैं और परीक्षण कर सकते हैं कि यह आपके वातावरण में फिट बैठता है या नहीं।