प्रेस्टो बड़े डेटा प्रोसेसिंग के लिए एक ओपन-सोर्स, समानांतर वितरित, SQL इंजन है। इसे फेसबुक द्वारा ग्राउंड-अप से विकसित किया गया था। पहली आंतरिक रिलीज़ 2013 में हुई और उनकी बड़ी डेटा समस्याओं के लिए काफी क्रांतिकारी समाधान था।
सैकड़ों भू-स्थित सर्वर और डेटा के पेटाबाइट के साथ, फेसबुक ने अपने Hadoop क्लस्टर के लिए एक वैकल्पिक मंच की तलाश शुरू कर दी। उनकी आधारभूत संरचना टीम संगठन में व्यापक रूप से ज्ञात प्रोग्रामिंग भाषा का उपयोग करके एनालिटिक्स बैच नौकरियों को चलाने और पाइपलाइन विकास को सरल बनाने के लिए आवश्यक समय को कम करना चाहती थी।
प्रेस्टो फाउंडेशन के अनुसार, "फेसबुक अपने 300PB डेटा वेयरहाउस सहित कई आंतरिक डेटा स्टोर के खिलाफ इंटरैक्टिव प्रश्नों के लिए प्रेस्टो का उपयोग करता है। फेसबुक के 1,000 से अधिक कर्मचारी प्रतिदिन प्रेस्टो का उपयोग 30,000 से अधिक प्रश्नों को चलाने के लिए करते हैं जो कुल मिलाकर प्रति दिन एक पेटाबाइट से अधिक स्कैन करते हैं।"
जबकि फेसबुक के पास एक असाधारण डेटा वेयरहाउस वातावरण है, वही चुनौतियां बड़े डेटा से निपटने वाले कई संगठनों में मौजूद हैं।
इस ब्लॉग में, हम इस बात पर एक नज़र डालेंगे कि टार फ़ाइल से डॉकर सर्वर का उपयोग करके एक बुनियादी प्रेस्टो वातावरण कैसे स्थापित किया जाए। डेटा स्रोत के रूप में, हम MySQL डेटा स्रोत पर ध्यान केंद्रित करेंगे, लेकिन यह कोई अन्य लोकप्रिय RDBMS हो सकता है।
प्रेस्टो को बड़े डेटा परिवेश में चलाना
शुरू करने से पहले, आइए इसके मुख्य वास्तुकला सिद्धांतों पर एक त्वरित नज़र डालें। प्रेस्टो उन टूल का एक विकल्प है जो मैपरेडस जॉब की पाइपलाइनों का उपयोग करके एचडीएफएस को क्वेरी करता है - जैसे कि हाइव। हाइव प्रेस्टो के विपरीत MapReduce का उपयोग नहीं करता है। प्रेस्टो उच्च-स्तरीय ऑपरेटरों और इन-मेमोरी प्रोसेसिंग के साथ एक विशेष-उद्देश्य क्वेरी निष्पादन इंजन के साथ चलता है।
हाइव प्रेस्टो के विपरीत डेटा को सभी चरणों के माध्यम से एक साथ डेटा खंड को एक साथ चलाने पर स्ट्रीम कर सकता है। इसे एकल या वितरित विषम डेटा स्रोतों के विरुद्ध तदर्थ विश्लेषणात्मक प्रश्नों को चलाने के लिए डिज़ाइन किया गया है। यह एक Hadoop प्लेटफॉर्म से रिलेशनल डेटाबेस या फ्लैट फाइलों जैसे अन्य डेटा स्टोर को क्वेरी करने के लिए पहुंच सकता है।
प्रेस्टो मानक एएनएसआई एसक्यूएल का उपयोग करता है जिसमें एग्रीगेशन, जॉइन या विश्लेषणात्मक विंडो फ़ंक्शन शामिल हैं। जावा में लिखे गए MapReduce की तुलना में SQL सर्वविदित है और इसका उपयोग करना बहुत आसान है।
डॉकर में Presto परिनियोजित करना
मूल प्रेस्टो कॉन्फ़िगरेशन को पूर्व-कॉन्फ़िगर डॉकर छवि या प्रेस्टो सर्वर टैरबॉल के साथ तैनात किया जा सकता है।
डॉकर सर्वर और प्रेस्टो सीएलआई कंटेनरों को इसके साथ आसानी से तैनात किया जा सकता है:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliआप दो प्रेस्टो सर्वर संस्करणों के बीच चयन कर सकते हैं। स्टारबर्स्ट से सामुदायिक संस्करण और एंटरप्राइज़ संस्करण। चूंकि हम इसे गैर-उत्पादन सैंडबॉक्स वातावरण में चलाने जा रहे हैं, इसलिए हम इस लेख में अपाचे संस्करण का उपयोग करेंगे।
पूर्व-आवश्यकताएं
प्रेस्टो पूरी तरह से जावा में लागू किया गया है और आपके सिस्टम पर जेवीएम स्थापित करने की आवश्यकता है। यह OpenJDK और Oracle Java दोनों पर चलता है। न्यूनतम संस्करण जावा 8u151 या जावा 11 है।
जावा JDK डाउनलोड करने के लिए https://openjdk.java.net/ या https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
पर जाएं।आप इसके साथ अपने जावा संस्करण की जांच कर सकते हैं
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)प्रेस्टो इंस्टॉलेशन
प्रेस्टो को स्थापित करने के लिए हम सर्वर टार और प्रेस्टो सीएलआई जार एक्जीक्यूटेबल डाउनलोड करने जा रहे हैं।
टारबॉल में एक एकल शीर्ष-स्तरीय निर्देशिका होगी, Presto-server-0.223, जिसे हम संस्थापन निर्देशिका कहेंगे।
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoइसके अतिरिक्त, प्रेस्टो को लॉग आदि को संग्रहीत करने के लिए एक डेटा निर्देशिका की आवश्यकता होती है।
स्थापना निर्देशिका के बाहर डेटा निर्देशिका बनाने की अनुशंसा की जाती है।
$ mkdir -p ~/data/presto/यह स्थान वह स्थान है जब हम अपनी समस्या निवारण शुरू करते हैं।
प्रेस्टो को कॉन्फ़िगर करना
अपना पहला उदाहरण शुरू करने से पहले हमें कॉन्फ़िगरेशन फ़ाइलों का एक समूह बनाना होगा। स्थापना निर्देशिका के अंदर एक आदि/निर्देशिका के निर्माण के साथ प्रारंभ करें। इस स्थान में निम्न कॉन्फ़िगरेशन फ़ाइलें होंगी:
आदि/
- नोड गुण - नोड पर्यावरण विन्यास
- JVM कॉन्फिग (jvm.config) - जावा वर्चुअल मशीन कॉन्फिग
- कॉन्फ़िगरेशन गुण (config.properties) - प्रेस्टो सर्वर के लिए कॉन्फ़िगरेशन
- कैटलॉग गुण - कनेक्टर्स के लिए कॉन्फ़िगरेशन (डेटा स्रोत)
- लॉग गुण - लॉगर कॉन्फ़िगरेशन
नीचे आप प्रेस्टो सैंडबॉक्स चलाने के लिए कुछ बुनियादी विन्यास पा सकते हैं। अधिक जानकारी के लिए दस्तावेज़ीकरण पर जाएँ।
vi आदि/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi आदि/नोड.गुण
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoमूल आदि/संरचना इस प्रकार दिख सकती है:

अगला कदम MySQL कनेक्टर को सेट करना है।
हम 3 नोड्स MariaDB क्लस्टर में से एक से कनेक्ट करने जा रहे हैं।
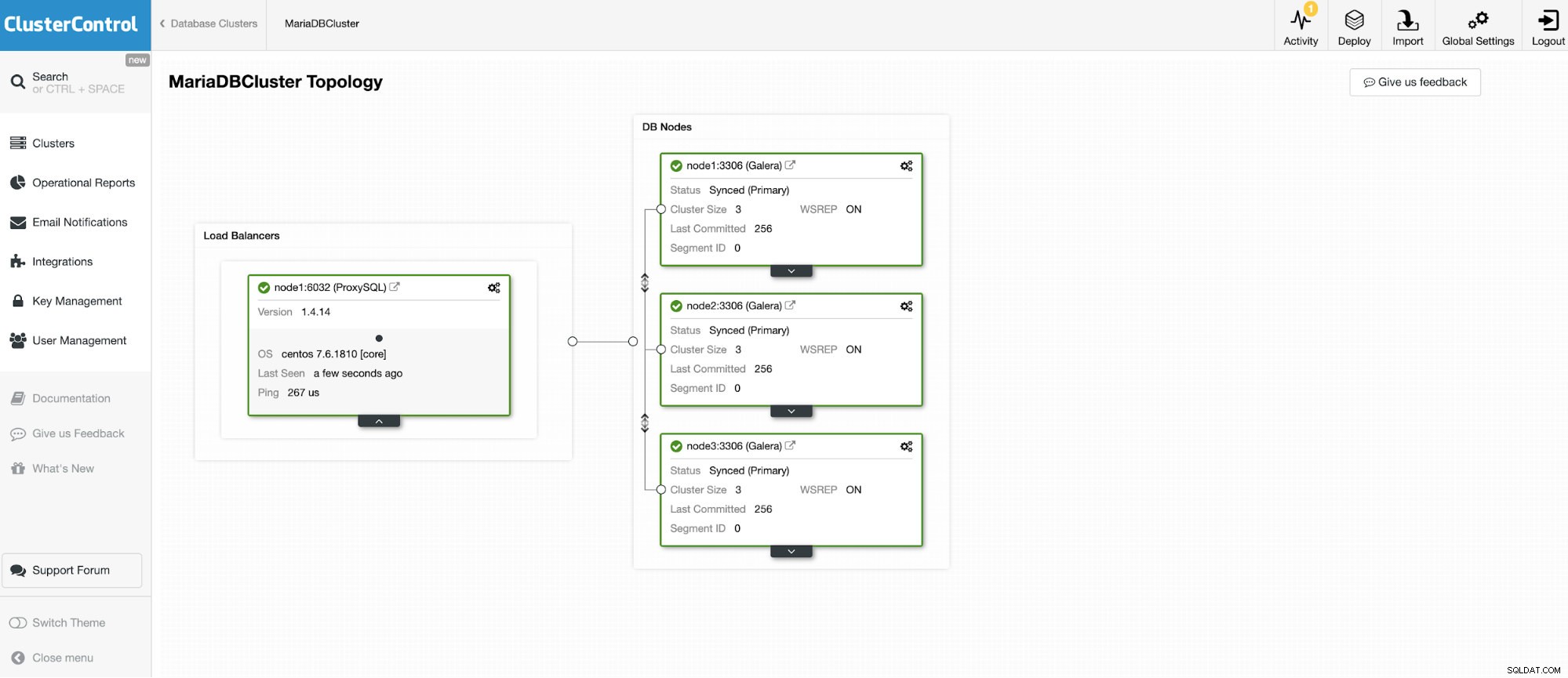
और एक अन्य स्टैंडअलोन उदाहरण Oracle MySQL 5.7 चला रहा है।
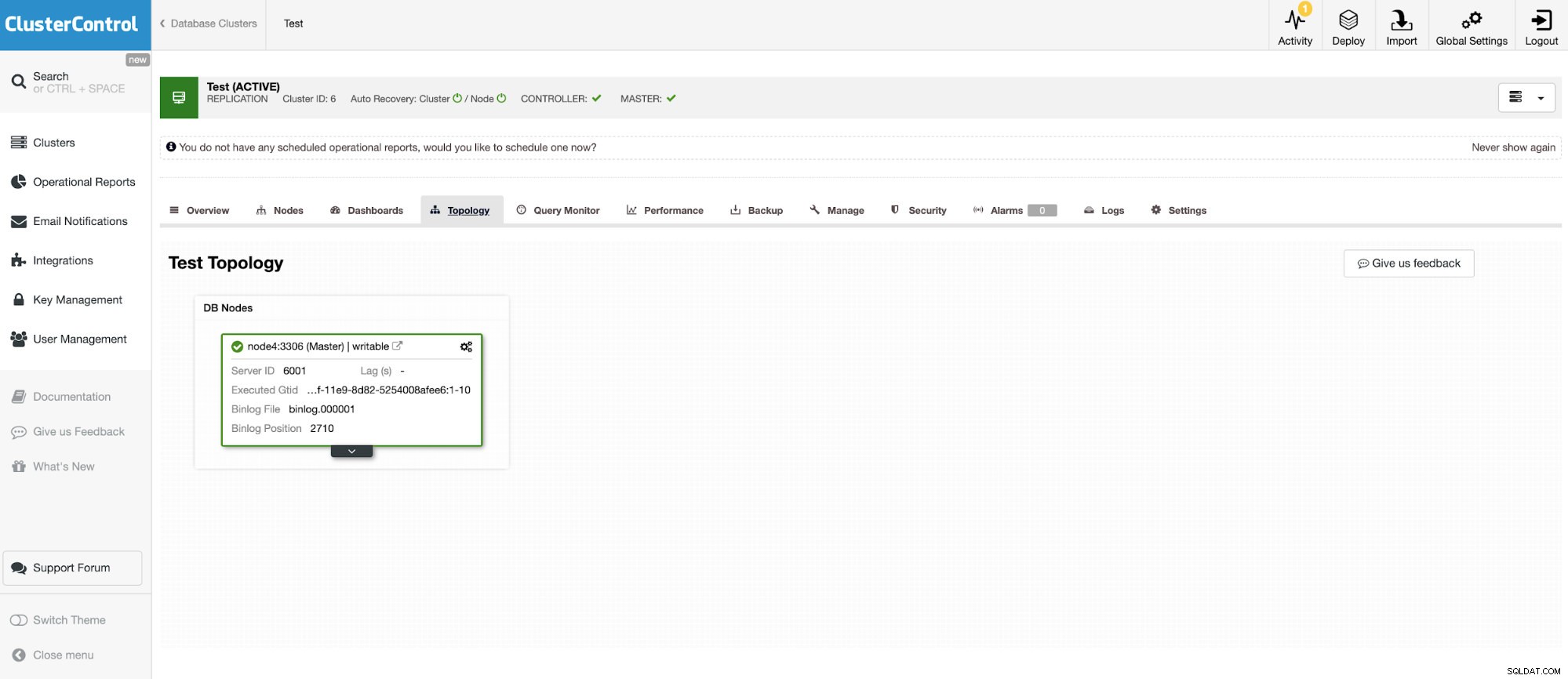
MySQL कनेक्टर बाहरी MySQL डेटाबेस में क्वेरी करने और टेबल बनाने की अनुमति देता है। इसका उपयोग Oracle से MariaDB और MySQL जैसे विभिन्न सिस्टमों के बीच डेटा को जोड़ने के लिए किया जा सकता है।
प्रेस्टो प्लग करने योग्य कनेक्टर्स का उपयोग करता है और कॉन्फ़िगरेशन बहुत आसान है। MySQL कनेक्टर को कॉन्फ़िगर करने के लिए, आदि/कैटलॉग नामक कैटलॉग गुण फ़ाइल बनाएं, उदाहरण के लिए, mysql.properties, MySQL कनेक्टर को mysql कैटलॉग के रूप में माउंट करने के लिए। अन्य सर्वर से कनेक्शन का प्रतिनिधित्व करने वाली प्रत्येक फाइल। इस मामले में, हमारे पास दो फ़ाइलें हैं:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretप्रेस्टो चल रहा है
जब सब कुछ सेट हो जाए तो प्रेस्टो इंस्टेंस शुरू करने का समय आ गया है। प्रेस्टो शुरू करने के लिए प्रीसो इंस्टॉलेशन के तहत बिन डायरेक्टरी में जाएं और निम्नलिखित को चलाएं:
$ bin/launcher start
Started as 18363प्रेस्टो चलाने को रोकने के लिए
$ bin/launcher stopअब जब सर्वर चालू है और चल रहा है तो हम प्रेस्टो से सीएलआई से जुड़ सकते हैं और MySQL डेटाबेस को क्वेरी कर सकते हैं।
प्रेस्टो कंसोल रन शुरू करने के लिए:
./presto --server localhost:8080 --catalog mysql --schema employeesअब हम CLI के माध्यम से अपने डेटाबेस को क्वेरी कर सकते हैं।
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
दोनों डेटाबेस मारियाडीबी क्लस्टर और माईएसक्यूएल को कर्मचारी डेटाबेस के साथ फीड किया गया है।
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlक्वेरी की स्थिति Presto वेब कंसोल में भी दिखाई देती है:https://localhost:8080/ui/#
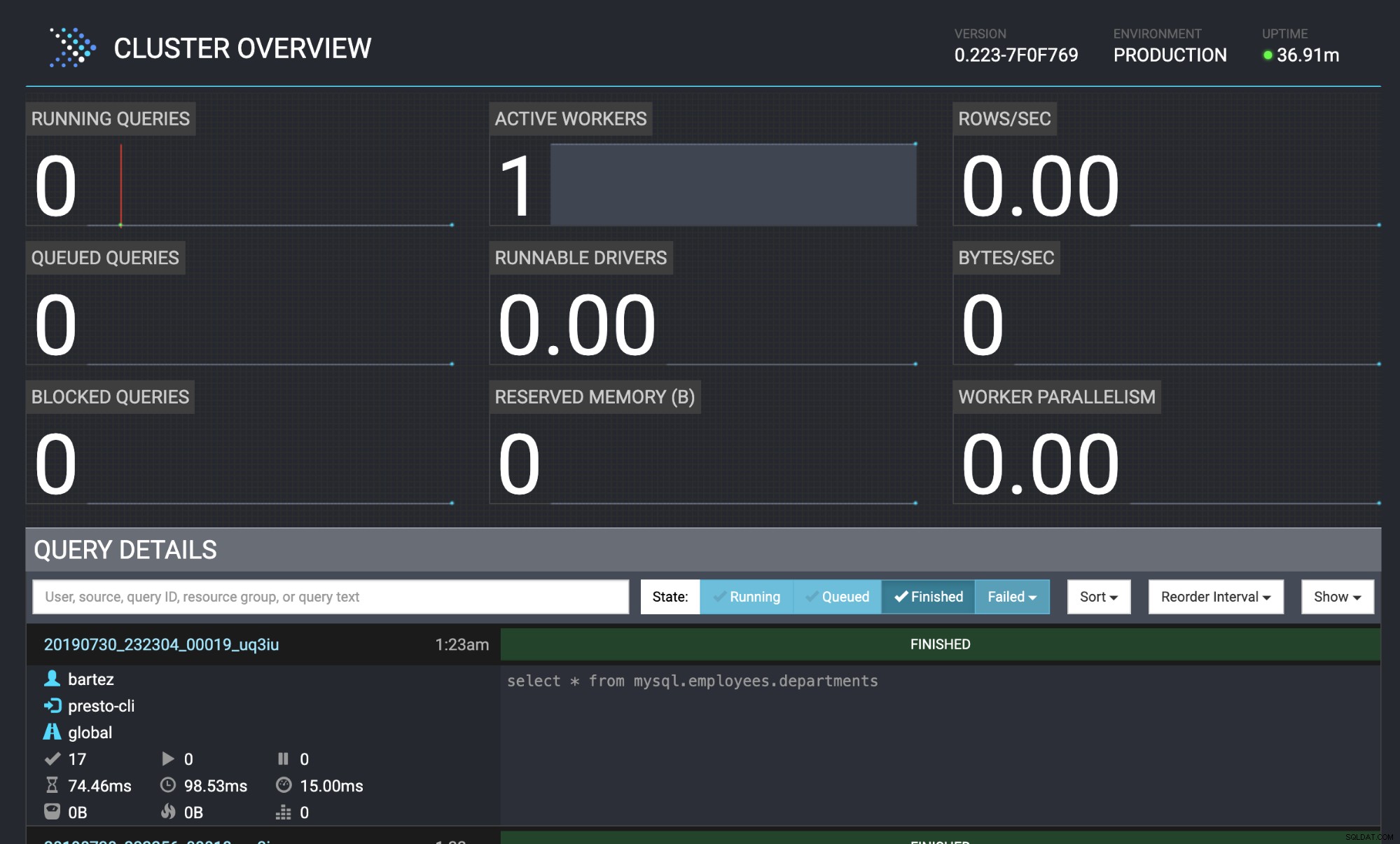 प्रेस्टो क्लस्टर ओवरव्यू
प्रेस्टो क्लस्टर ओवरव्यू निष्कर्ष
कई प्रसिद्ध कंपनियां (जैसे एयरबीएनबी, नेटफ्लिक्स, ट्विटर) कम विलंबता प्रदर्शन के लिए प्रेस्टो को अपना रही हैं। इसमें कोई संदेह नहीं है कि यह बहुत ही दिलचस्प सॉफ्टवेयर है जो भारी ईटीएल डेटा वेयरहाउस प्रक्रियाओं को चलाने की आवश्यकता को समाप्त कर सकता है। इस ब्लॉग में, हमने अभी MySQL कनेक्टर पर एक संक्षिप्त नज़र डाली है, लेकिन आप इसका उपयोग HDFS, ऑब्जेक्ट स्टोर, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB, और कई अन्य से डेटा का विश्लेषण करने के लिए कर सकते हैं।