यह इस ब्लॉग पोस्ट में, हम उत्पादन डेटाबेस सिस्टम में 6 अलग-अलग विफलता परिदृश्यों का विश्लेषण करेंगे, जिसमें एकल-सर्वर मुद्दों से लेकर बहु-डेटासेंटर विफलता योजनाओं तक शामिल हैं। हम आपको संबंधित परिदृश्य के लिए पुनर्प्राप्ति और विफलता प्रक्रियाओं के बारे में बताएंगे। उम्मीद है, इससे आपको अपने बुनियादी ढांचे को डिजाइन करते समय आपके सामने आने वाले जोखिमों और विचार करने योग्य बातों की अच्छी समझ मिल जाएगी।
डेटाबेस स्कीमा दूषित
आइए सिंगल नोड इंस्टॉलेशन से शुरू करें - सरलतम रूप में एक डेटाबेस सेटअप। लागू करने में आसान, न्यूनतम लागत पर। इस परिदृश्य में, आप एकल सर्वर पर एकाधिक अनुप्रयोग चलाते हैं जहाँ प्रत्येक डेटाबेस स्कीमा भिन्न अनुप्रयोग से संबंधित होता है। एकल स्कीमा की पुनर्प्राप्ति के लिए दृष्टिकोण कई कारकों पर निर्भर करेगा।
- क्या मेरे पास कोई बैकअप है?
- क्या मेरे पास बैकअप है और मैं इसे कितनी तेजी से पुनर्स्थापित कर सकता हूं?
- किस प्रकार का स्टोरेज इंजन उपयोग में है?
- क्या मेरे पास PITR-संगत (पॉइंट इन टाइम रिकवरी) बैकअप है?
डेटा भ्रष्टाचार को mysqlcheck द्वारा पहचाना जा सकता है।
mysqlcheck -uroot -p <DATABASE>DATABASE को डेटाबेस के नाम से बदलें, और TABLE को उस तालिका के नाम से बदलें जिसे आप जाँचना चाहते हैं:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck निर्दिष्ट डेटाबेस और तालिकाओं की जाँच करता है। यदि कोई तालिका चेक पास करती है, तो mysqlcheck तालिका के लिए ठीक प्रदर्शित करता है। नीचे के उदाहरण में, हम देख सकते हैं कि तालिका वेतन पुनर्प्राप्ति की आवश्यकता है।
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKबिना किसी अतिरिक्त DR सर्वर के एकल नोड स्थापना के लिए, प्राथमिक दृष्टिकोण बैकअप से डेटा को पुनर्स्थापित करना होगा। लेकिन यह केवल एक चीज नहीं है जिस पर आपको विचार करने की आवश्यकता है। एक ही उदाहरण के तहत कई डेटाबेस स्कीमा होने से एक समस्या होती है जब आपको डेटा को पुनर्स्थापित करने के लिए अपने सर्वर को नीचे लाना पड़ता है। एक और सवाल यह है कि क्या आप अपने सभी डेटाबेस को अंतिम बैकअप में रोलबैक कर सकते हैं। ज्यादातर मामलों में, यह संभव नहीं होगा।
यहाँ कुछ अपवाद हैं। अंतिम बैकअप से एकल तालिका या डेटाबेस को पुनर्स्थापित करना संभव है जब बिंदु समय पुनर्प्राप्ति की आवश्यकता नहीं होती है। ऐसी प्रक्रिया अधिक जटिल है। यदि आपके पास mysqldump है, तो आप इससे अपना डेटाबेस निकाल सकते हैं। यदि आप xtradbackup या mariabackup के साथ बाइनरी बैकअप चलाते हैं और आपने प्रति फ़ाइल तालिका सक्षम की है, तो यह संभव है।
यह जांचने का तरीका यहां दिया गया है कि क्या आपके पास प्रति फ़ाइल तालिका विकल्प सक्षम है।
mysql> SET GLOBAL innodb_file_per_table=1; innodb_file_per_table सक्षम होने पर, आप InnoDB तालिकाओं को tbl_name .ibd फ़ाइल में संग्रहीत कर सकते हैं। MyISAM स्टोरेज इंजन के विपरीत, इंडेक्स और डेटा के लिए अलग tbl_name .MYD और tbl_name .MYI फाइलों के साथ, InnoDB डेटा और इंडेक्स को एक .ibd फ़ाइल में एक साथ स्टोर करता है। अपने स्टोरेज इंजन की जांच करने के लिए आपको चलाने की जरूरत है:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';या सीधे कंसोल से:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: xtradbackup से तालिकाओं को पुनर्स्थापित करने के लिए, आपको एक निर्यात प्रक्रिया से गुजरना होगा। इसे पुनर्स्थापित करने से पहले बैकअप तैयार करने की आवश्यकता है। निर्यात तैयारी के चरण में किया जाता है। एक बार पूर्ण बैकअप बन जाने के बाद, अतिरिक्त ध्वज --export के साथ मानक तैयारी प्रक्रिया चलाएँ:
innobackupex --apply-log --export /u01/backupयह अतिरिक्त निर्यात फ़ाइलें बनाएगा जिनका उपयोग आप बाद में आयात चरण में करेंगे। किसी अन्य सर्वर पर एक तालिका आयात करने के लिए, पहले उसी संरचना के साथ एक नई तालिका बनाएं जो उस सर्वर पर आयात की जाएगी:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;टेबलस्पेस को त्यागें:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;फिर mytable.ibd और mytable.exp फ़ाइलों को डेटाबेस के होम में कॉपी करें, और इसके टेबलस्पेस को आयात करें:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;हालांकि इसे अधिक नियंत्रित तरीके से करने के लिए, अन्य उदाहरण/सर्वर में डेटाबेस बैकअप को पुनर्स्थापित करने की सिफारिश की जाएगी और जो आवश्यक है उसे मुख्य सिस्टम पर कॉपी करें। ऐसा करने के लिए, आपको MySQL इंस्टेंस की स्थापना को चलाने की आवश्यकता है। यह या तो एक ही मशीन पर किया जा सकता है - लेकिन इस तरह से कॉन्फ़िगर करने के लिए अधिक प्रयास की आवश्यकता होती है कि दोनों उदाहरण एक ही मशीन पर चल सकें - उदाहरण के लिए, इसके लिए अलग संचार सेटिंग्स की आवश्यकता होगी।
आप ClusterControl का उपयोग करके टास्क रिस्टोर और इंस्टॉलेशन दोनों को जोड़ सकते हैं।
ClusterControl आपको उपलब्ध बैकअप के माध्यम से ऑन-प्रिमाइसेस या क्लाउड में चलेगा, आपको पुनर्स्थापना या सटीक लॉग स्थिति के लिए सटीक समय चुनने देता है, और यदि आवश्यक हो तो एक नया डेटाबेस इंस्टेंस स्थापित करता है।
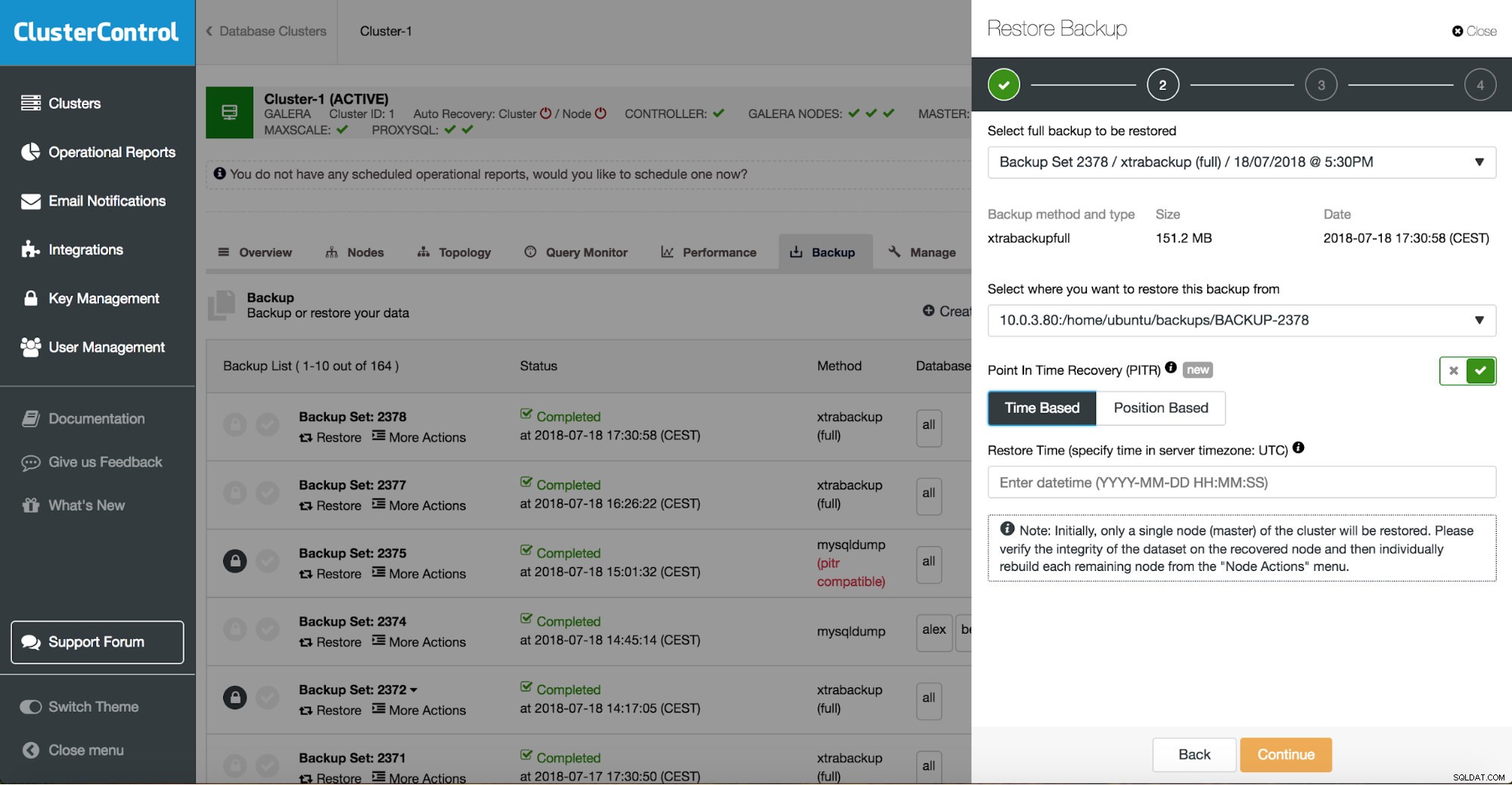 क्लस्टरकंट्रोल पॉइंट इन टाइम रिकवरी
क्लस्टरकंट्रोल पॉइंट इन टाइम रिकवरी 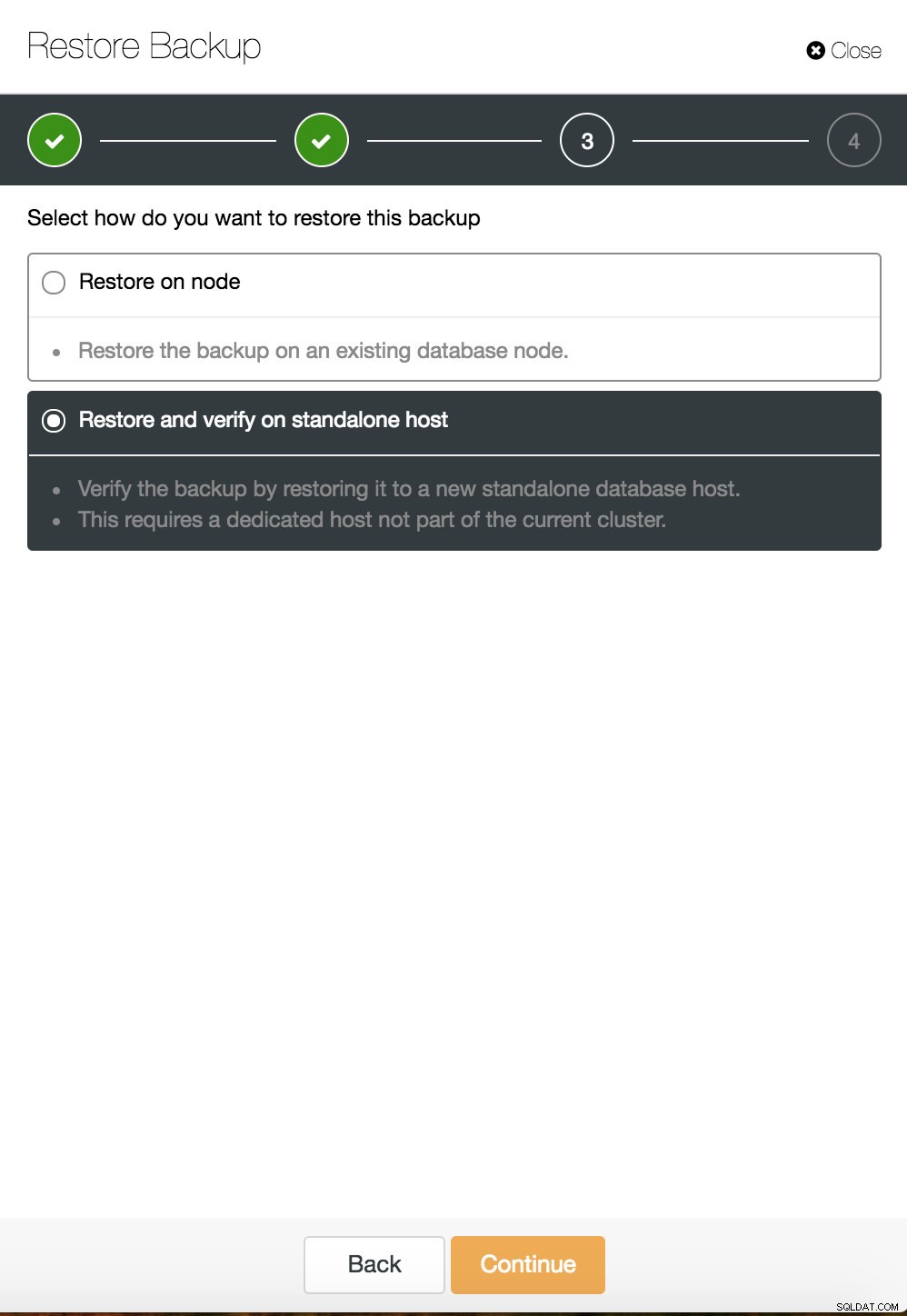 ClusterControl एक स्टैंडअलोन होस्ट पर पुनर्स्थापित और सत्यापित करें
ClusterControl एक स्टैंडअलोन होस्ट पर पुनर्स्थापित और सत्यापित करें 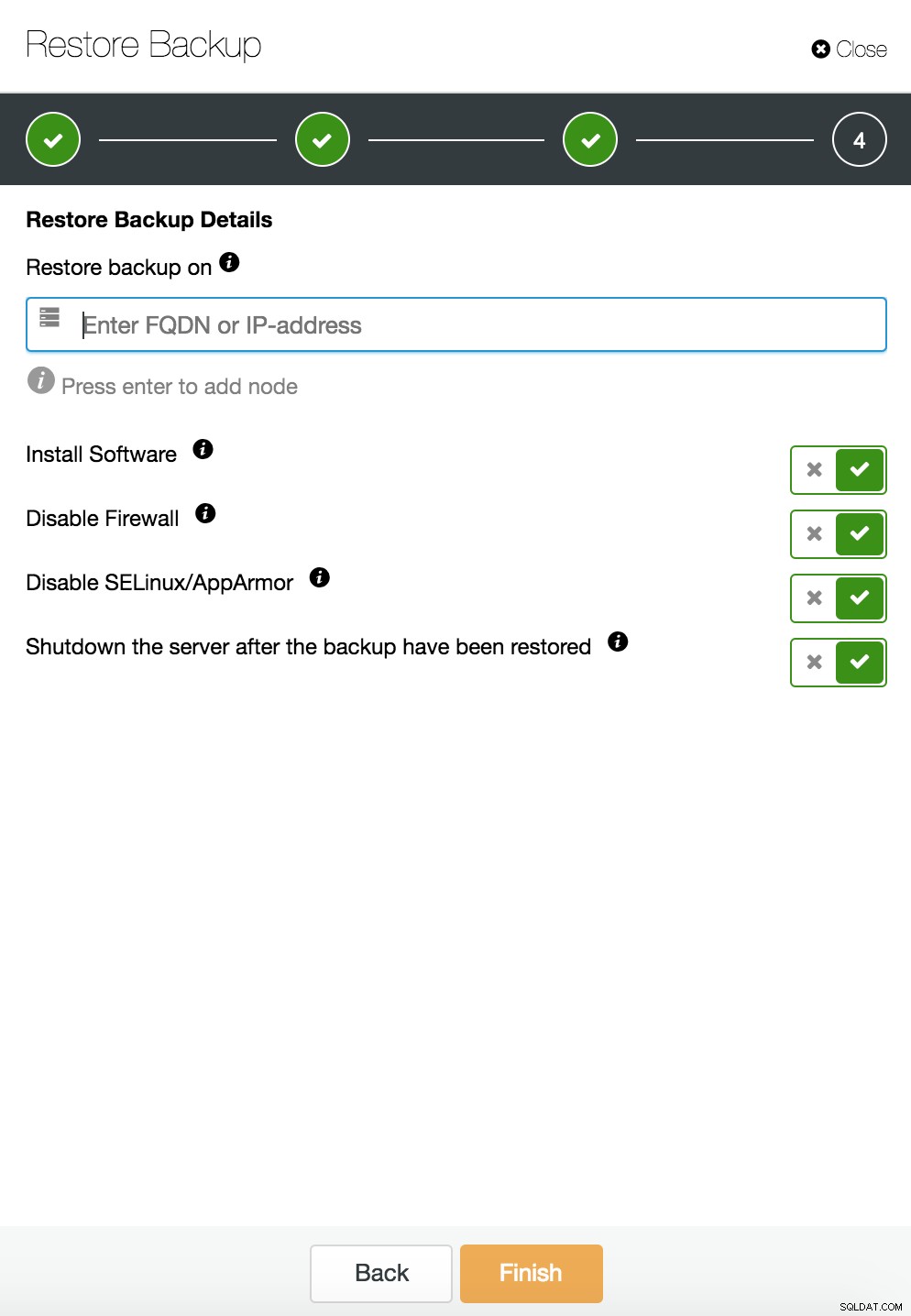 CusterControl एक स्टैंडअलोन होस्ट पर पुनर्स्थापित और सत्यापित करें। स्थापना विकल्प।
CusterControl एक स्टैंडअलोन होस्ट पर पुनर्स्थापित और सत्यापित करें। स्थापना विकल्प। आप ब्लॉग में डेटा पुनर्प्राप्ति के बारे में अधिक जानकारी प्राप्त कर सकते हैं मेरा MySQL डेटाबेस दूषित है... मैं अब क्या करूँ?
समर्पित सर्वर पर डेटाबेस इंस्टेंस दूषित
अंतर्निहित प्लेटफ़ॉर्म में दोष अक्सर डेटाबेस भ्रष्टाचार का कारण होते हैं। आपका MySQL इंस्टेंस डेटा को स्टोर करने और पुनर्प्राप्त करने के लिए कई चीजों पर निर्भर करता है - डिस्क सबसिस्टम, कंट्रोलर, संचार चैनल, ड्राइवर और फर्मवेयर। क्रैश आपके डेटा के कुछ हिस्सों, mysql बायनेरिज़ या यहां तक कि बैकअप फ़ाइलों को भी प्रभावित कर सकता है जिन्हें आप सिस्टम पर स्टोर करते हैं। विभिन्न अनुप्रयोगों को अलग करने के लिए, आप उन्हें समर्पित सर्वर पर रख सकते हैं।
यदि आप उन्हें वहन कर सकते हैं तो अलग-अलग सिस्टम पर अलग-अलग एप्लिकेशन स्कीमा एक अच्छा विचार है। कोई कह सकता है कि यह संसाधनों की बर्बादी है, लेकिन एक मौका है कि उनमें से केवल एक के नीचे जाने पर व्यवसाय का प्रभाव कम होगा। लेकिन फिर भी, आपको अपने डेटाबेस को डेटा हानि से बचाने की आवश्यकता है। उसी सर्वर पर बैकअप स्टोर करना कोई बुरा विचार नहीं है जब तक कि आपके पास कहीं और कॉपी हो। इन दिनों, टेप बैकअप के लिए क्लाउड स्टोरेज एक उत्कृष्ट विकल्प है।
ClusterControl आपको अपने बैकअप की एक प्रति क्लाउड में रखने में सक्षम बनाता है। यह शीर्ष 3 क्लाउड प्रदाताओं - Amazon AWS, Google Cloud, और Microsoft Azure पर अपलोड करने का समर्थन करता है।
जब आपके पास अपना पूरा बैकअप बहाल हो जाता है, तो आप इसे निश्चित समय पर पुनर्स्थापित करना चाह सकते हैं। पॉइंट-इन-टाइम पुनर्प्राप्ति सर्वर को पूर्ण बैकअप लेने के समय की तुलना में अधिक हाल के समय तक अद्यतित रखेगी। ऐसा करने के लिए, आपको अपने बाइनरी लॉग सक्षम करने होंगे। आप निम्न के साथ उपलब्ध बाइनरी लॉग की जांच कर सकते हैं:
mysql> SHOW BINARY LOGS;और वर्तमान लॉग फ़ाइल के साथ:
SHOW MASTER STATUS;फिर आप एसक्यूएल फ़ाइल में बाइनरी लॉग पास करके वृद्धिशील डेटा कैप्चर कर सकते हैं। गुम संचालन को फिर से निष्पादित किया जा सकता है।
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outClusterControl में भी ऐसा ही किया जा सकता है।
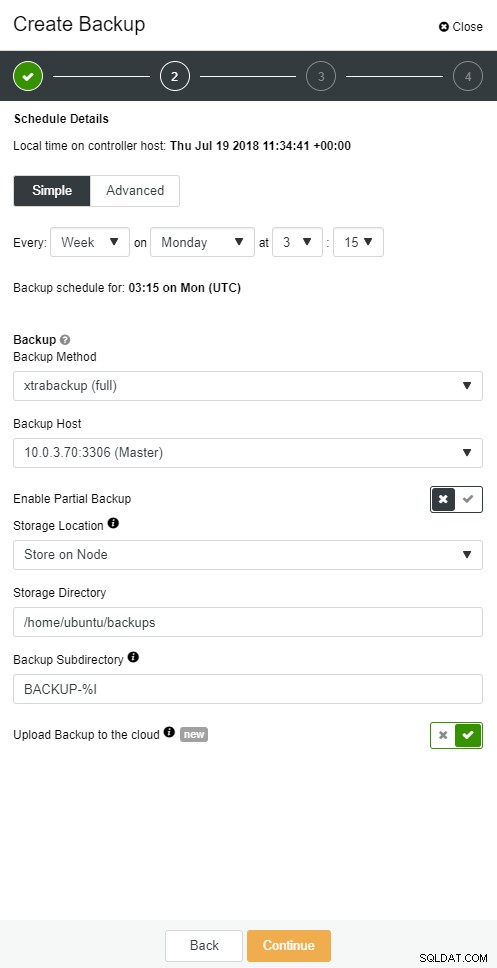 ClusterControl क्लाउड बैकअप
ClusterControl क्लाउड बैकअप 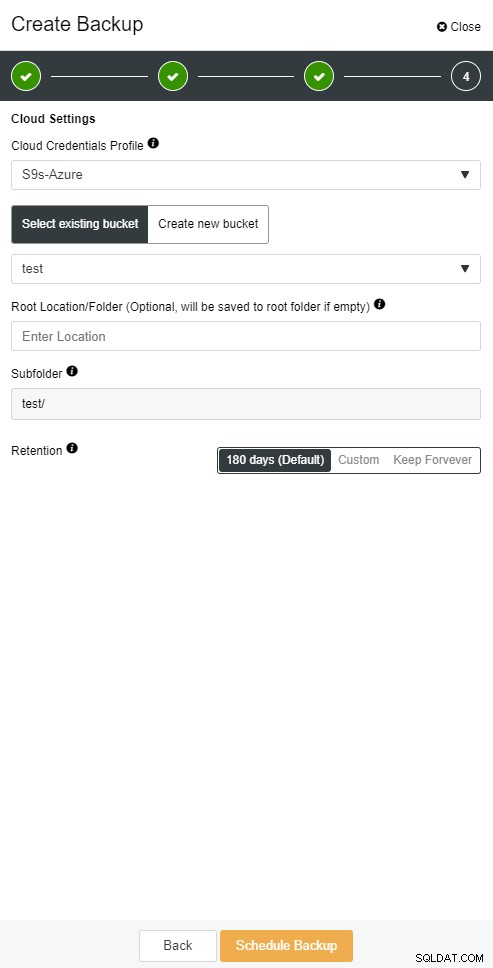 ClusterControl क्लाउड बैकअप
ClusterControl क्लाउड बैकअप डेटाबेस गुलाम नीचे चला जाता है
ठीक है, तो आपका डेटाबेस एक समर्पित सर्वर पर चल रहा है। आपने पूर्ण और वृद्धिशील बैकअप के संयोजन के साथ एक परिष्कृत बैकअप शेड्यूल बनाया है, उन्हें क्लाउड पर अपलोड करें और तेजी से पुनर्प्राप्ति के लिए स्थानीय डिस्क पर नवीनतम बैकअप संग्रहीत करें। आपकी अलग-अलग बैकअप अवधारण नीतियां हैं - स्थानीय डिस्क ड्राइवरों पर संग्रहीत बैकअप के लिए कम और आपके क्लाउड बैकअप के लिए विस्तारित।
ऐसा लगता है कि आप आपदा परिदृश्य के लिए पूरी तरह तैयार हैं। लेकिन जब पुनर्स्थापना समय की बात आती है, तो हो सकता है कि यह आपकी व्यावसायिक आवश्यकताओं को पूरा न करे।
आपको एक त्वरित फ़ेलओवर फ़ंक्शन की आवश्यकता है। एक सर्वर जो मास्टर से बाइनरी लॉग्स को लागू करने के लिए ऊपर और चल रहा होगा जहां लिखता है। मास्टर/स्लेव प्रतिकृति विफलता परिदृश्य में एक नया अध्याय प्रारंभ करता है। यदि आप मास्टर डाउन हो जाते हैं तो यह आपके एप्लिकेशन को वापस जीवन में लाने का एक तेज़ तरीका है।
लेकिन विफलता परिदृश्य में विचार करने के लिए कुछ चीजें हैं। एक विलंबित प्रतिकृति दास को सेटअप करना है, ताकि आप मास्टर सर्वर पर ट्रिगर किए गए मोटे फिंगर कमांड पर प्रतिक्रिया कर सकें। एक दास सर्वर कम से कम एक निर्दिष्ट समय तक मास्टर से पीछे रह सकता है। डिफ़ॉल्ट विलंब 0 सेकंड है। देरी को N सेकंड पर सेट करने के लिए MASTER_DELAY विकल्प का उपयोग करें MASTER TO बदलें:
CHANGE MASTER TO MASTER_DELAY = N;दूसरा स्वचालित विफलता को सक्षम करना है। बाजार में कई स्वचालित विफलता समाधान हैं। आप MHA, MRM, mysqlfailover या GUI Orchestrator और ClusterControl जैसे कमांड लाइन टूल्स के साथ ऑटोमैटिक फेलओवर सेट कर सकते हैं। जब इसे सही तरीके से सेट किया जाता है, तो यह आपके आउटेज को काफी कम कर सकता है।
ClusterControl MySQL, PostgreSQL और MongoDB प्रतिकृति के साथ-साथ मल्टी-मास्टर क्लस्टर समाधान Galera और NDB के लिए स्वचालित विफलता का समर्थन करता है।
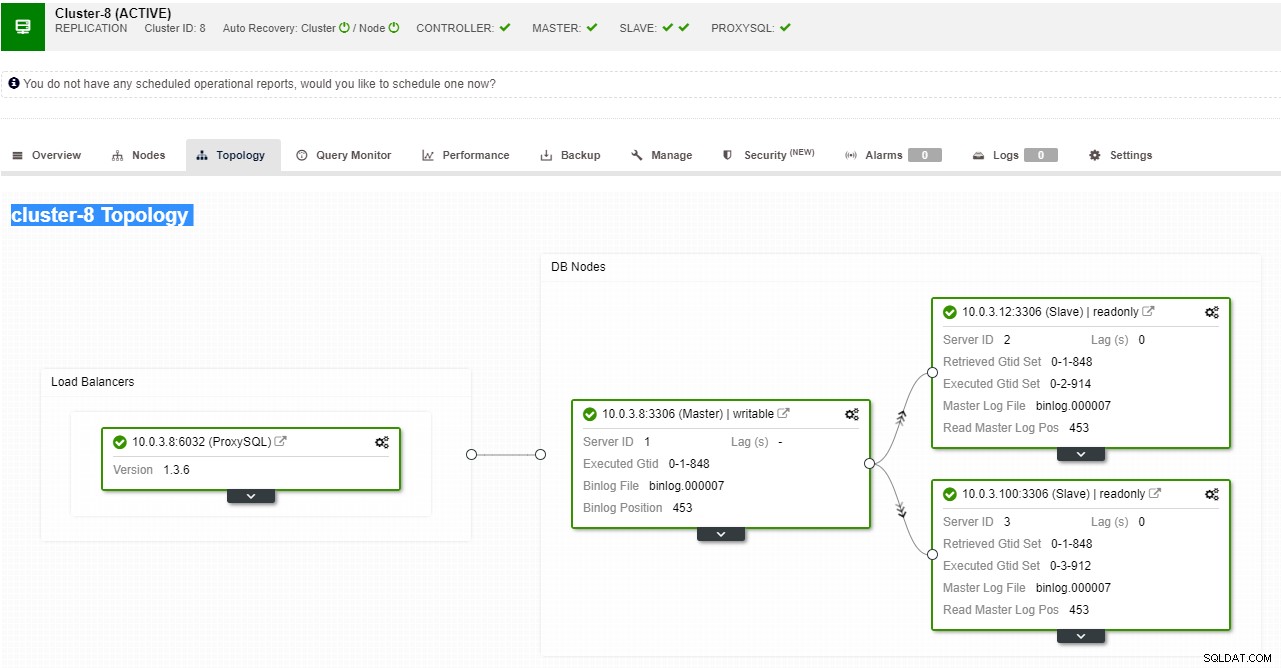 ClusterControl प्रतिकृति टोपोलॉजी दृश्य
ClusterControl प्रतिकृति टोपोलॉजी दृश्य जब कोई स्लेव नोड क्रैश हो जाता है और सर्वर गंभीर रूप से पिछड़ जाता है, तो आप अपने स्लेव सर्वर का पुनर्निर्माण करना चाह सकते हैं। स्लेव के पुनर्निर्माण की प्रक्रिया बैकअप से पुनर्स्थापित करने के समान है।
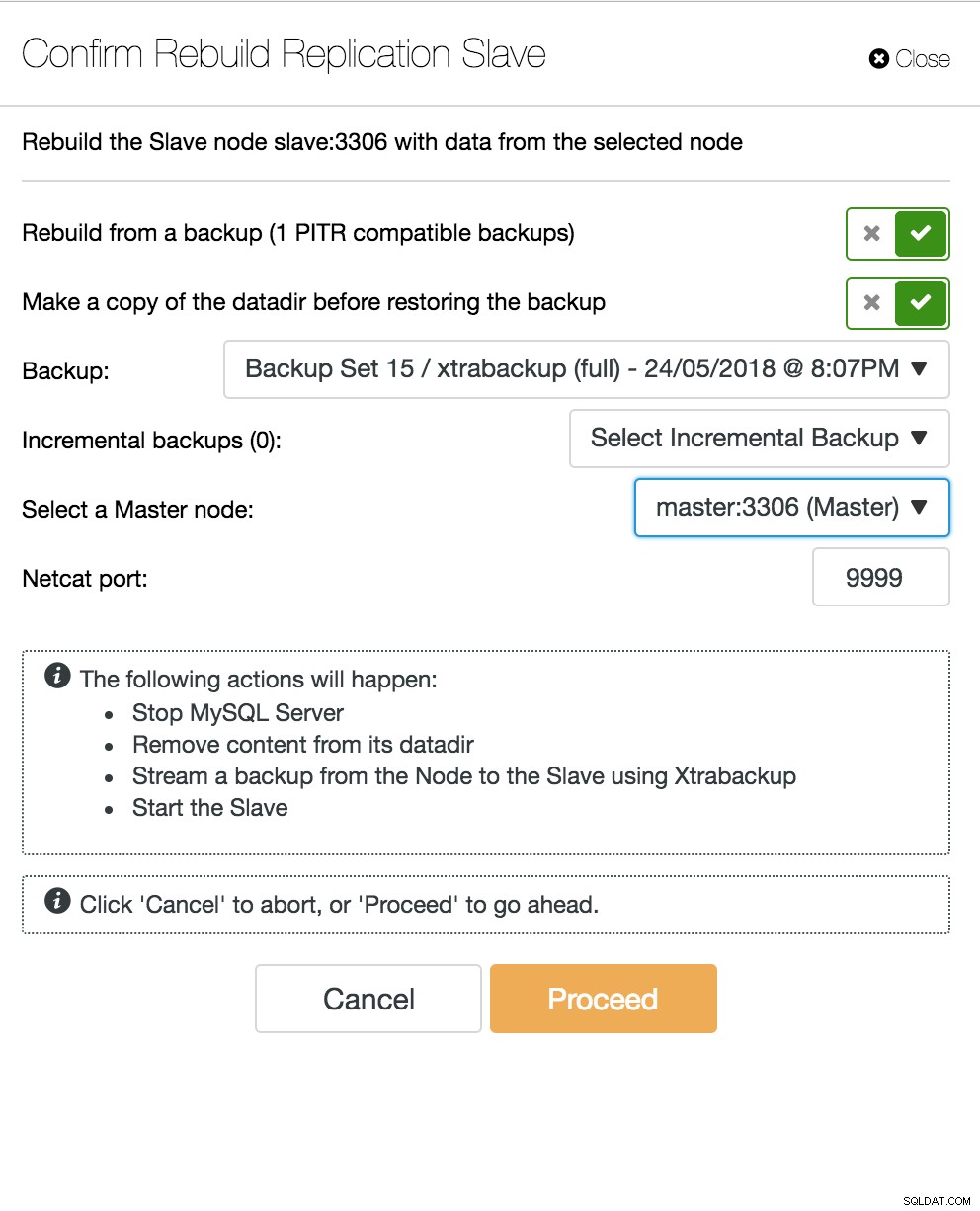 ClusterControl स्लेव का पुनर्निर्माण करें
ClusterControl स्लेव का पुनर्निर्माण करें डेटाबेस मल्टी-मास्टर सर्वर डाउन हो जाता है
अब जब आपके पास दास सर्वर एक DR नोड के रूप में कार्य कर रहा है, और आपकी विफलता प्रक्रिया अच्छी तरह से स्वचालित और परीक्षण की गई है, तो आपका DBA जीवन अधिक आरामदायक हो जाता है। यह सच है, लेकिन हल करने के लिए कुछ और पहेलियाँ हैं। कंप्यूटिंग शक्ति मुफ़्त नहीं है, और आपकी व्यावसायिक टीम आपसे अपने हार्डवेयर का बेहतर उपयोग करने के लिए कह सकती है, आप अपने स्लेव सर्वर को न केवल निष्क्रिय सर्वर के रूप में उपयोग करना चाह सकते हैं, बल्कि लेखन संचालन भी कर सकते हैं।
तब आप एक बहु-मास्टर प्रतिकृति समाधान की जाँच करना चाह सकते हैं। उच्च उपलब्धता MySQL और MariaDB के लिए गैलेरा क्लस्टर मुख्यधारा का विकल्प बन गया है। और यद्यपि इसे अब पारंपरिक MySQL मास्टर-स्लेव आर्किटेक्चर के विश्वसनीय प्रतिस्थापन के रूप में जाना जाता है, यह ड्रॉप-इन प्रतिस्थापन नहीं है।
गैलेरा क्लस्टर में साझा कुछ भी नहीं वास्तुकला है। साझा डिस्क के बजाय, गैलेरा समकालिक प्रतिकृति प्राप्त करने के लिए समूह संचार और लेनदेन आदेश के साथ प्रमाणन आधारित प्रतिकृति का उपयोग करता है। एक डेटाबेस क्लस्टर एक नोड के नुकसान से बचने में सक्षम होना चाहिए, हालांकि यह विभिन्न तरीकों से हासिल किया जाता है। गैलेरा के मामले में, महत्वपूर्ण पहलू नोड्स की संख्या है। गैलेरा को चालू रहने के लिए कोरम की आवश्यकता होती है। एक तीन नोड क्लस्टर एक नोड के क्रैश से बच सकता है। अपने क्लस्टर में अधिक नोड्स के साथ, आप अधिक विफलताओं से बच सकते हैं।
पुनर्प्राप्ति प्रक्रिया स्वचालित है, इसलिए आपको किसी भी विफलता संचालन को करने की आवश्यकता नहीं है। हालाँकि अच्छा अभ्यास यह होगा कि आप नोड्स को मारें और देखें कि आप उन्हें कितनी तेजी से वापस ला सकते हैं। इस ऑपरेशन को और अधिक कुशल बनाने के लिए, आप गैलेरा कैशे आकार को संशोधित कर सकते हैं। यदि गैलेरा कैशे आकार को ठीक से नियोजित नहीं किया गया है, तो आपके अगले बूटिंग नोड को कैश में केवल लापता राइट-सेट के बजाय एक पूर्ण बैकअप लेना होगा।
इंटेंट शुरू करने के रूप में विफलता परिदृश्य सरल है। गैलेरा कैश में डेटा के आधार पर, बूटिंग नोड एसएसटी (पूर्ण बैकअप से पुनर्स्थापित करें) या आईएसटी (लापता राइट-सेट लागू करें) को निष्पादित करेगा। हालांकि, यह अक्सर मानवीय हस्तक्षेप से जुड़ा होता है। यदि आप संपूर्ण विफलता प्रक्रिया को स्वचालित करना चाहते हैं, तो आप ClusterControl की स्वतः पुनर्प्राप्ति कार्यक्षमता (नोड और क्लस्टर स्तर) का उपयोग कर सकते हैं।
 ClusterControl क्लस्टर स्वतः पुनर्प्राप्ति
ClusterControl क्लस्टर स्वतः पुनर्प्राप्ति गैलेरा कैशे आकार का अनुमान लगाएं:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;फ़ेलओवर को और अधिक सुसंगत बनाने के लिए, आपको mycnf में gcache.recover=yes सक्षम करना चाहिए। यह विकल्प पुनः आरंभ करने पर गैलेरा-कैश को पुनर्जीवित करेगा। इसका मतलब है कि नोड एक डोनर के रूप में कार्य कर सकता है और सेवा अनुपलब्ध राइट-सेट (एसएसटी का उपयोग करने के बजाय आईएसटी की सुविधा प्रदान करता है)।
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3प्रॉक्सी SQL नोड नीचे चला जाता है
यदि आपके पास वर्चुअल आईपी सेटअप है, तो आपको केवल अपने एप्लिकेशन को वर्चुअल आईपी पते पर इंगित करना है और सब कुछ सही कनेक्शन के अनुसार होना चाहिए। आपके डेटाबेस इंस्टेंस को कई डेटासेंटर में फैलाना पर्याप्त नहीं है, फिर भी आपको उन तक पहुंचने के लिए अपने एप्लिकेशन की आवश्यकता होती है। मान लें कि आपने पठन प्रतिकृतियों की संख्या को बढ़ा दिया है, हो सकता है कि आप रखरखाव या उपलब्धता कारणों से उनमें से प्रत्येक के लिए वर्चुअल आईपी लागू करना चाहें। यह वर्चुअल आईपी का एक बोझिल पूल बन सकता है जिसे आपको प्रबंधित करना होगा। यदि उन प्रतिकृतियों में से एक को क्रैश का सामना करना पड़ता है, तो आपको अलग-अलग होस्ट को वर्चुअल आईपी को फिर से असाइन करने की आवश्यकता होती है, अन्यथा आपका एप्लिकेशन या तो एक होस्ट से कनेक्ट हो जाएगा जो कि नीचे है या सबसे खराब स्थिति में, पुराने डेटा के साथ एक लैगिंग सर्वर।
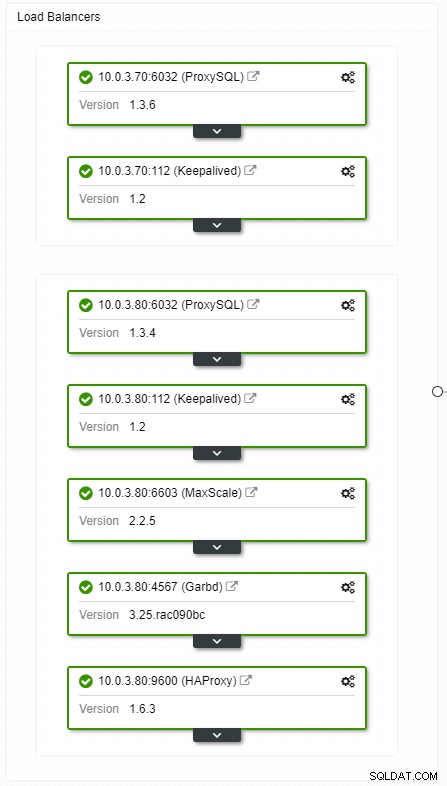 ClusterControl HA लोड बैलेंसर्स टोपोलॉजी व्यू
ClusterControl HA लोड बैलेंसर्स टोपोलॉजी व्यू क्रैश अक्सर नहीं होते हैं, लेकिन सर्वर के डाउन होने की तुलना में अधिक संभावित होते हैं। यदि किसी भी कारण से, एक दास नीचे चला जाता है, तो ProxySQL जैसा कुछ ओवरलोडिंग के जोखिम के साथ, सभी ट्रैफ़िक को मास्टर पर पुनर्निर्देशित करेगा। जब दास ठीक हो जाता है, तो यातायात को वापस उसके पास भेज दिया जाएगा। आमतौर पर, ऐसे डाउनटाइम में कुछ मिनटों से अधिक नहीं लगना चाहिए, इसलिए समग्र गंभीरता मध्यम है, भले ही संभावना भी मध्यम हो।
अपने लोड बैलेंसर घटकों को बेमानी बनाने के लिए, आप रख-रखाव का उपयोग कर सकते हैं।
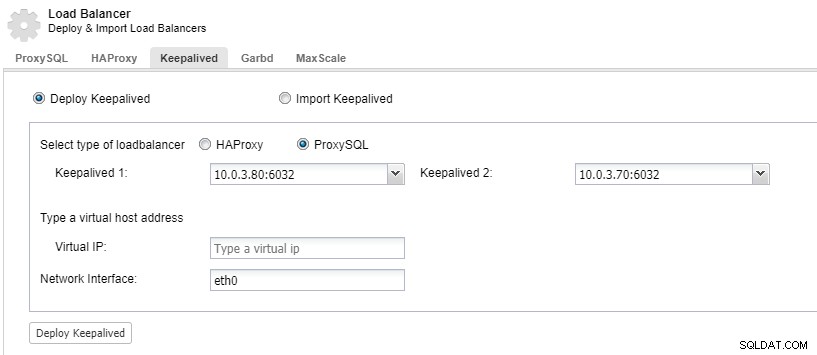 ClusterControl:ProxySQL लोड बैलेंसर के लिए कीपलाइव्ड डिप्लॉय करें
ClusterControl:ProxySQL लोड बैलेंसर के लिए कीपलाइव्ड डिप्लॉय करें डेटासेंटर नीचे चला जाता है
प्रतिकृति के साथ मुख्य समस्या यह है कि डेटासेंटर विफलता का पता लगाने और नए मास्टर की सेवा करने के लिए कोई बहुमत तंत्र नहीं है। संकल्पों में से एक ऑर्केस्ट्रेटर/बेड़ा का उपयोग करना है। ऑर्केस्ट्रेटर एक टोपोलॉजी पर्यवेक्षक है जो विफलताओं को नियंत्रित कर सकता है। जब बेड़ा के साथ प्रयोग किया जाता है, तो ऑर्केस्ट्रेटर कोरम-जागरूक हो जाएगा। ऑर्केस्ट्रेटर के उदाहरणों में से एक को नेता के रूप में चुना जाता है और पुनर्प्राप्ति कार्यों को निष्पादित करता है। ऑर्केस्ट्रेटर नोड के बीच संबंध लेन-देन संबंधी डेटाबेस से संबंधित नहीं है और विरल है।
ऑर्केस्ट्रेटर/राफ्ट अतिरिक्त उदाहरणों का उपयोग कर सकते हैं जो टोपोलॉजी की निगरानी करते हैं। नेटवर्क विभाजन के मामले में, विभाजित ऑर्केस्ट्रेटर इंस्टेंस कोई कार्रवाई नहीं करेगा। ऑर्केस्ट्रेटर क्लस्टर का वह हिस्सा जिसमें कोरम होता है, एक नए मास्टर का चुनाव करेगा और आवश्यक टोपोलॉजी परिवर्तन करेगा।
ClusterControl का उपयोग प्रबंधन, स्केलिंग और, जो सबसे महत्वपूर्ण है, नोड पुनर्प्राप्ति के लिए किया जाता है - ऑर्केस्ट्रेटर विफलताओं को संभालेगा, लेकिन यदि कोई दास दुर्घटनाग्रस्त हो जाता है, तो ClusterControl यह सुनिश्चित करेगा कि इसे पुनर्प्राप्त किया जाएगा। ऑर्केस्ट्रेटर और क्लस्टर कंट्रोल एक ही उपलब्धता क्षेत्र में स्थित होंगे, जो MySQL नोड्स से अलग होंगे, यह सुनिश्चित करने के लिए कि उनकी गतिविधि डेटा सेंटर में उपलब्धता क्षेत्रों के बीच नेटवर्क विभाजन से प्रभावित नहीं होगी।