पिछली पोस्ट में, हमने चर्चा की थी कि आप श्वेतसूची और काली सूची का उपयोग करके ClusterControl में विफलता प्रक्रिया को कैसे नियंत्रित कर सकते हैं। इस पोस्ट में, हम इसी तरह की अवधारणा पर चर्चा करने जा रहे हैं। लेकिन इस बार हम ClusterControl द्वारा उपलब्ध कराए गए कई हुक के माध्यम से बाहरी स्क्रिप्ट और एप्लिकेशन के साथ एकीकरण पर ध्यान केंद्रित करेंगे।
बुनियादी ढांचे के वातावरण को अलग-अलग तरीकों से बनाया जा सकता है, क्योंकि कई बार पहेली के दिए गए टुकड़े के लिए चुनने के लिए कई विकल्प होते हैं। हम कैसे परिभाषित करते हैं कि किस डेटाबेस नोड को लिखना है? क्या आप वर्चुअल आईपी का उपयोग करते हैं? क्या आप किसी प्रकार की सेवा खोज का उपयोग करते हैं? हो सकता है कि आप डीएनएस प्रविष्टियों के साथ जाएं और जरूरत पड़ने पर ए रिकॉर्ड बदल दें? प्रॉक्सी परत के बारे में क्या? क्या आप लेखक पर निर्णय लेने के लिए अपने प्रॉक्सी के लिए 'read_only' मान पर भरोसा करते हैं, या हो सकता है कि आप प्रॉक्सी के कॉन्फ़िगरेशन में सीधे आवश्यक परिवर्तन करें? आपका वातावरण स्विचओवर को कैसे संभालता है? क्या आप बस आगे बढ़ सकते हैं और इसे निष्पादित कर सकते हैं, या हो सकता है कि आपको पहले से कुछ प्रारंभिक कार्रवाई करनी पड़े? उदाहरण के लिए, वास्तव में स्विच करने से पहले कुछ अन्य प्रक्रियाओं को रोकना?
फ़ेलओवर सॉफ़्टवेयर के लिए यह संभव नहीं है कि लोगों द्वारा बनाए जा सकने वाले सभी विभिन्न सेटअपों को कवर करने के लिए पूर्व-कॉन्फ़िगर किया जाए। फेलओवर प्रक्रिया में हुक करने के विभिन्न तरीके प्रदान करने का यह मुख्य कारण है। इस तरह आप इसे कस्टमाइज़ कर सकते हैं और अपने सेटअप की सभी सूक्ष्मताओं को संभालना संभव बना सकते हैं। इस ब्लॉग पोस्ट में, हम देखेंगे कि कैसे ClusterControl की विफलता प्रक्रिया को विभिन्न पूर्व और विफलता के बाद की स्क्रिप्ट का उपयोग करके अनुकूलित किया जा सकता है। हम कुछ उदाहरणों पर भी चर्चा करेंगे कि इस तरह के अनुकूलन के साथ क्या हासिल किया जा सकता है।
ClusterControl को एकीकृत करना
ClusterControl कई हुक प्रदान करता है जिनका उपयोग बाहरी स्क्रिप्ट में प्लग इन करने के लिए किया जा सकता है। नीचे आपको कुछ स्पष्टीकरण वाले लोगों की सूची मिलेगी।
- Replication_onfail_failover_script - जैसे ही यह पता चलता है कि एक विफलता की आवश्यकता है, यह स्क्रिप्ट निष्पादित हो जाती है। यदि स्क्रिप्ट गैर-शून्य लौटाती है, तो यह विफलता को निरस्त करने के लिए बाध्य करेगी। यदि स्क्रिप्ट परिभाषित है लेकिन नहीं मिली है, तो विफलता निरस्त कर दी जाएगी। स्क्रिप्ट के लिए चार तर्क दिए गए हैं:arg1='all server' arg2='oldmaster' arg3='candidate', arg4='slaves of Oldmaster' और इस तरह पास किया गया:'स्क्रिपनाम arg1 arg2 arg3 arg4'। स्क्रिप्ट नियंत्रक पर पहुंच योग्य होनी चाहिए और निष्पादन योग्य होनी चाहिए।
- Replication_pre_failover_script - यह स्क्रिप्ट फेलओवर होने से पहले निष्पादित होती है, लेकिन एक उम्मीदवार के चुने जाने के बाद और फेलओवर प्रक्रिया को जारी रखना संभव है। यदि स्क्रिप्ट गैर-शून्य लौटाती है तो यह विफलता को निरस्त करने के लिए बाध्य करेगी। यदि स्क्रिप्ट परिभाषित है लेकिन नहीं मिली है, तो विफलता निरस्त कर दी जाएगी। स्क्रिप्ट नियंत्रक पर पहुंच योग्य होनी चाहिए और निष्पादन योग्य होनी चाहिए।
- Replication_post_failover_script - यह स्क्रिप्ट फेलओवर होने के बाद निष्पादित होती है। यदि स्क्रिप्ट गैर-शून्य लौटाती है, तो कार्य लॉग में एक चेतावनी लिखी जाएगी। स्क्रिप्ट नियंत्रक पर पहुंच योग्य होनी चाहिए और निष्पादन योग्य होनी चाहिए।
- Replication_post_unsuccessful_failover_script - इस स्क्रिप्ट को फेलओवर प्रयास विफल होने के बाद निष्पादित किया जाता है। यदि स्क्रिप्ट गैर-शून्य लौटाती है, तो कार्य लॉग में एक चेतावनी लिखी जाएगी। स्क्रिप्ट नियंत्रक पर पहुंच योग्य होनी चाहिए और निष्पादन योग्य होनी चाहिए।
- Replication_failed_reslave_failover_script - इस स्क्रिप्ट को उसके बाद निष्पादित किया जाता है उसके बाद एक नए मास्टर को पदोन्नत किया गया है और यदि नए मास्टर को दासों की दासता विफल हो जाती है। यदि स्क्रिप्ट गैर-शून्य लौटाती है, तो कार्य लॉग में एक चेतावनी लिखी जाएगी। स्क्रिप्ट नियंत्रक पर पहुंच योग्य होनी चाहिए और निष्पादन योग्य होनी चाहिए।
- Replication_pre_switchover_script - स्विचओवर होने से पहले यह स्क्रिप्ट निष्पादित होती है। यदि स्क्रिप्ट गैर-शून्य लौटाती है, तो यह स्विचओवर को विफल होने के लिए बाध्य करेगी। यदि स्क्रिप्ट परिभाषित है लेकिन नहीं मिली है, तो स्विचओवर निरस्त कर दिया जाएगा। स्क्रिप्ट नियंत्रक पर पहुंच योग्य होनी चाहिए और निष्पादन योग्य होनी चाहिए।
- Replication_post_switchover_script - स्विचओवर होने के बाद यह स्क्रिप्ट निष्पादित होती है। यदि स्क्रिप्ट गैर-शून्य लौटाती है, तो कार्य लॉग में एक चेतावनी लिखी जाएगी। स्क्रिप्ट नियंत्रक पर पहुंच योग्य होनी चाहिए और निष्पादन योग्य होनी चाहिए।
जैसा कि आप देख सकते हैं, हुक ज्यादातर मामलों को कवर करते हैं जहां आप कुछ कार्रवाई करना चाहते हैं - स्विचओवर से पहले और बाद में, एक विफलता से पहले और बाद में, जब दास विफल हो गया हो या जब विफलता विफल हो गई हो। सभी लिपियों को चार तर्कों के साथ लागू किया जाता है (जो स्क्रिप्ट में नियंत्रित किया जा सकता है या नहीं, स्क्रिप्ट के लिए उन सभी का उपयोग करने की आवश्यकता नहीं है):सभी सर्वर, होस्टनाम (या आईपी - जैसा कि क्लस्टरकंट्रोल में परिभाषित किया गया है) मास्टर उम्मीदवार के पुराने मास्टर, होस्टनाम (या आईपी - जैसा कि क्लस्टरकंट्रोल में परिभाषित किया गया है) और चौथा, पुराने मास्टर की सभी प्रतिकृतियां। उन विकल्पों से अधिकांश मामलों को संभालना संभव हो जाता है।
उन सभी हुक को किसी दिए गए क्लस्टर के लिए कॉन्फ़िगरेशन फ़ाइल में परिभाषित किया जाना चाहिए (/etc/cmon.d/cmon_X.cnf जहां X क्लस्टर की आईडी है)। एक उदाहरण इस तरह दिख सकता है:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shबेशक, बुलाई गई स्क्रिप्ट को निष्पादन योग्य होना चाहिए, अन्यथा सीमोन उन्हें निष्पादित करने में सक्षम नहीं होगा। आइए अब एक क्षण लेते हैं और ClusterControl में विफलता प्रक्रिया से गुजरते हैं और देखते हैं कि बाहरी स्क्रिप्ट कब निष्पादित की जाती हैं।
ClusterControl में विफलता प्रक्रिया
हमने उपलब्ध सभी हुक को परिभाषित किया है:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shइसके बाद आपको सीमोन प्रोसेस को रीस्टार्ट करना होगा। एक बार यह हो जाने के बाद, हम विफलता का परीक्षण करने के लिए तैयार हैं। मूल टोपोलॉजी इस तरह दिखती है:
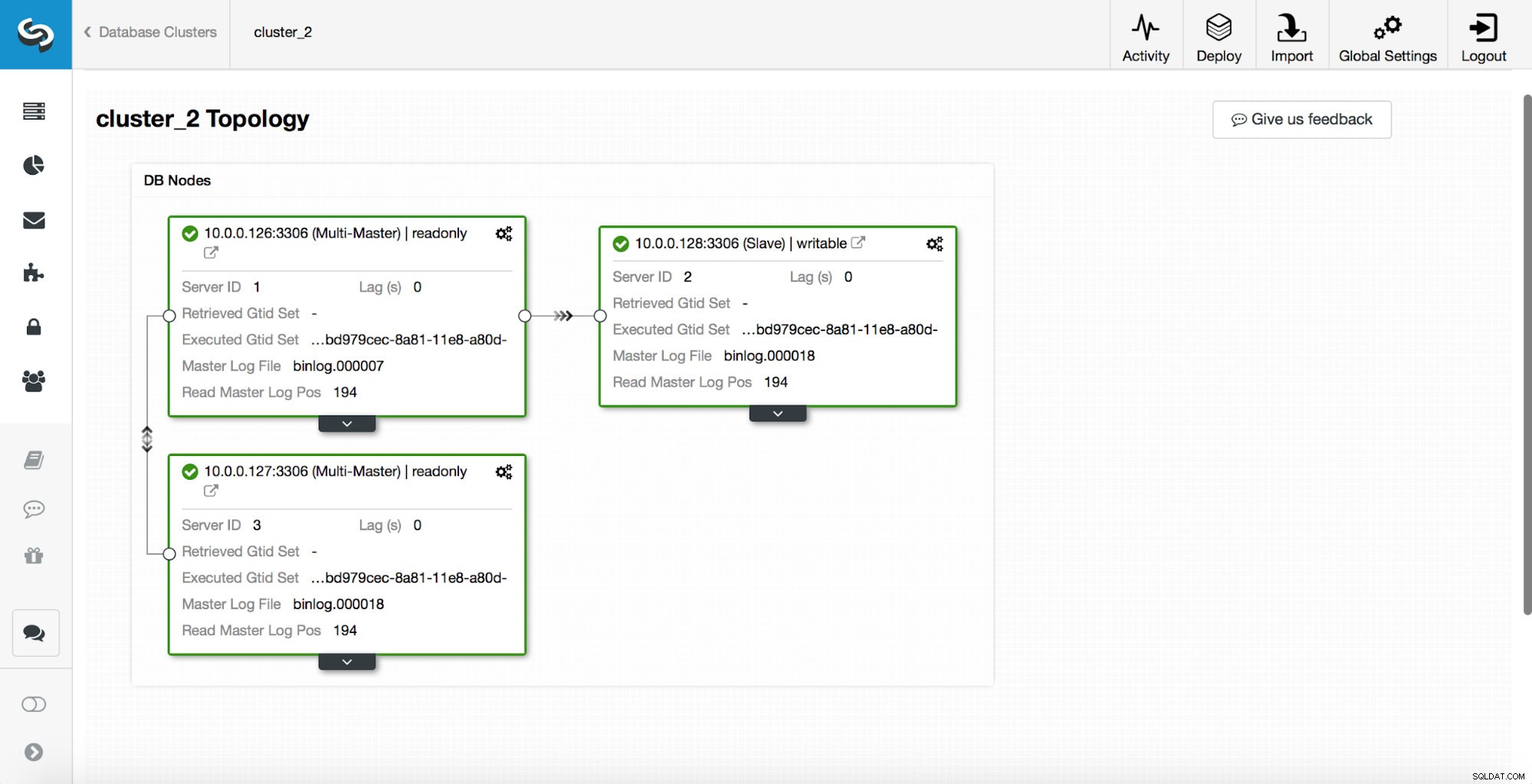
एक मास्टर मारा गया है और विफलता प्रक्रिया शुरू हो गई है। कृपया ध्यान दें, हाल ही की लॉग प्रविष्टियां शीर्ष पर हैं इसलिए आप नीचे से ऊपर तक विफलता का पालन करना चाहते हैं।
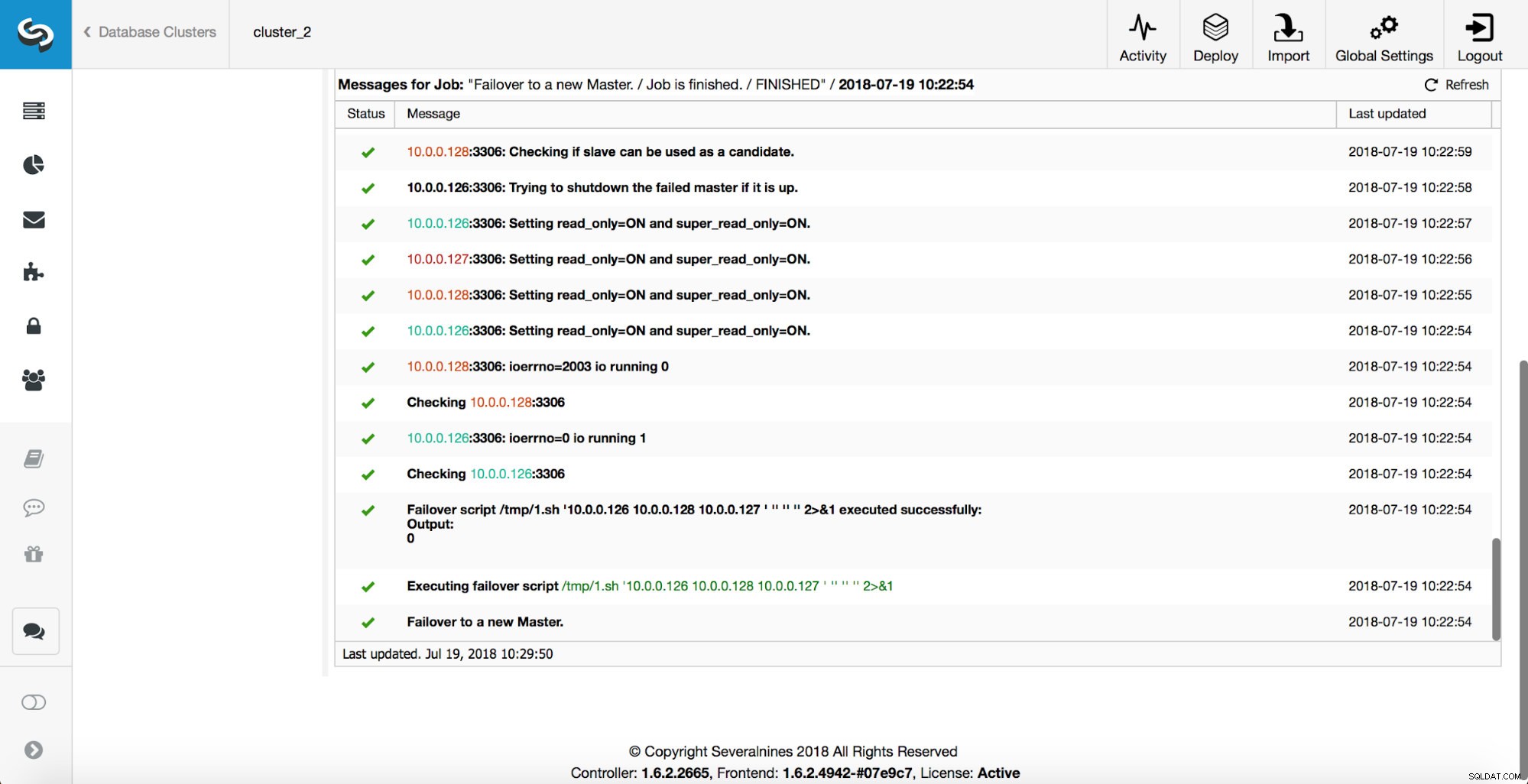
जैसा कि आप देख सकते हैं, फ़ेलओवर कार्य प्रारंभ होने के तुरंत बाद, यह 'replication_onfail_failover_script' हुक को ट्रिगर करता है। फिर, सभी पहुंच योग्य होस्ट को केवल read_only के रूप में चिह्नित किया जाता है और ClusterControl पुराने मास्टर को चलने से रोकने का प्रयास करता है।
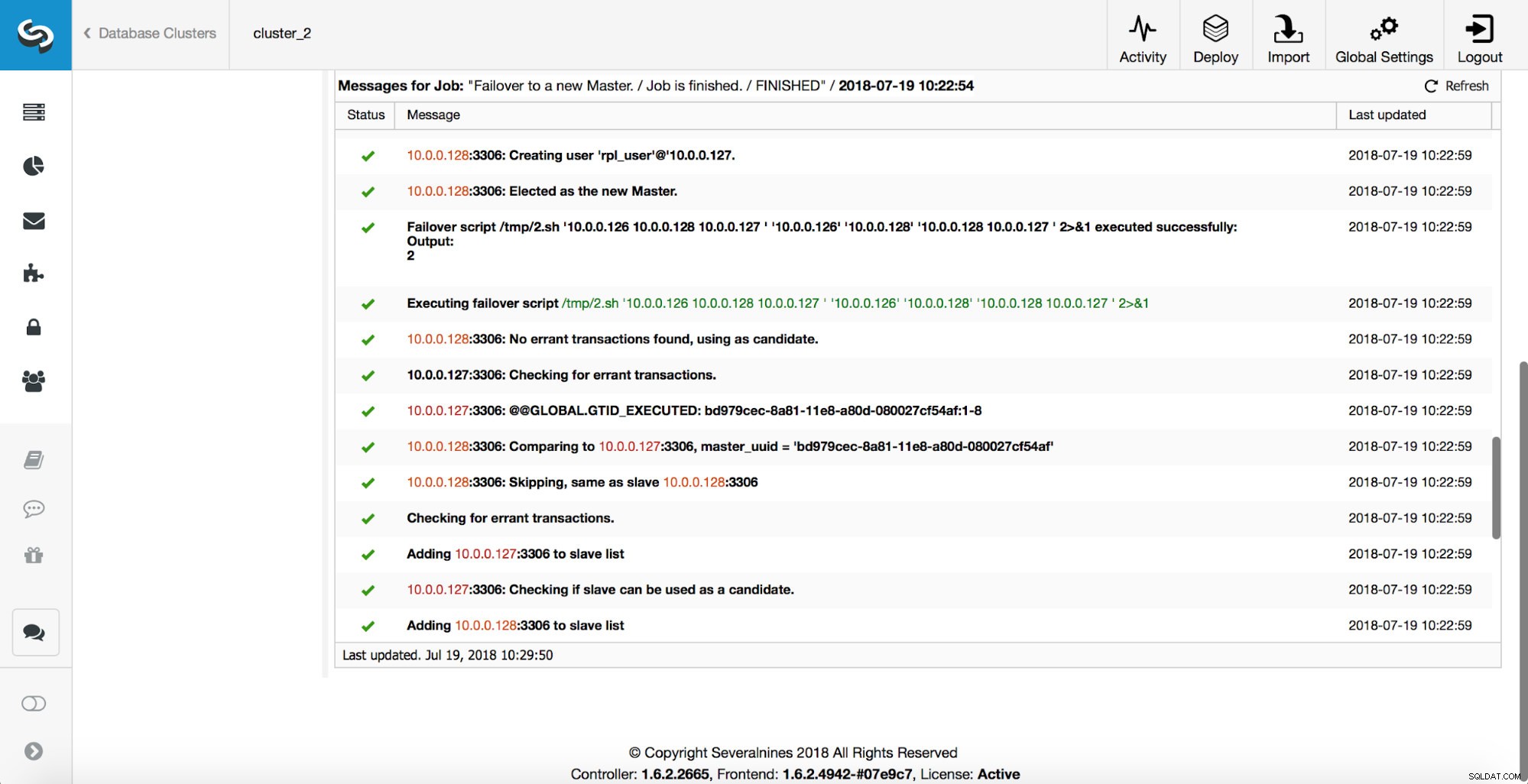
इसके बाद, मास्टर उम्मीदवार को चुना जाता है, विवेक जांच निष्पादित की जाती है। एक बार जब यह पुष्टि हो जाती है कि मास्टर उम्मीदवार को नए मास्टर के रूप में इस्तेमाल किया जा सकता है, तो 'replication_pre_failover_script' निष्पादित किया जाता है।
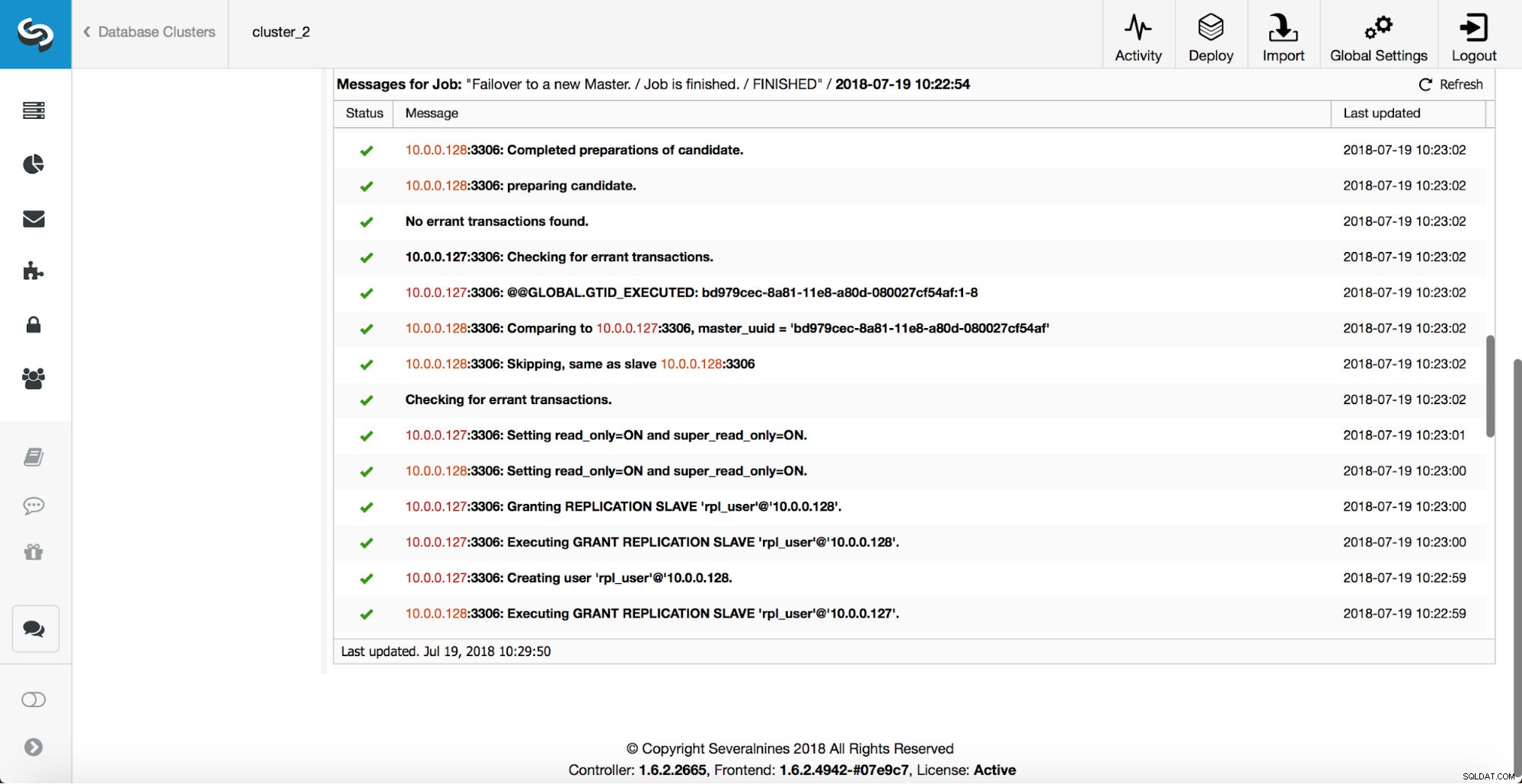
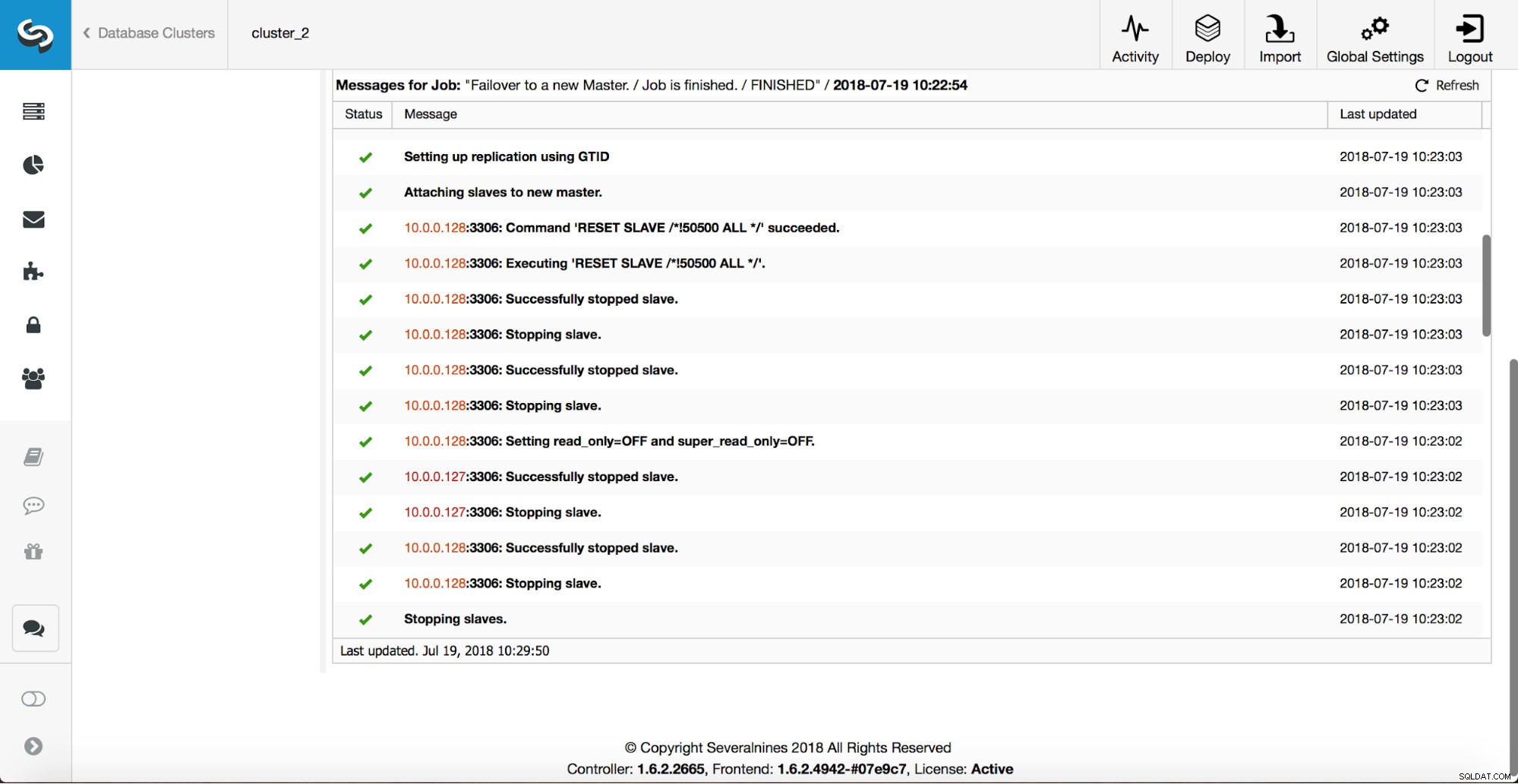
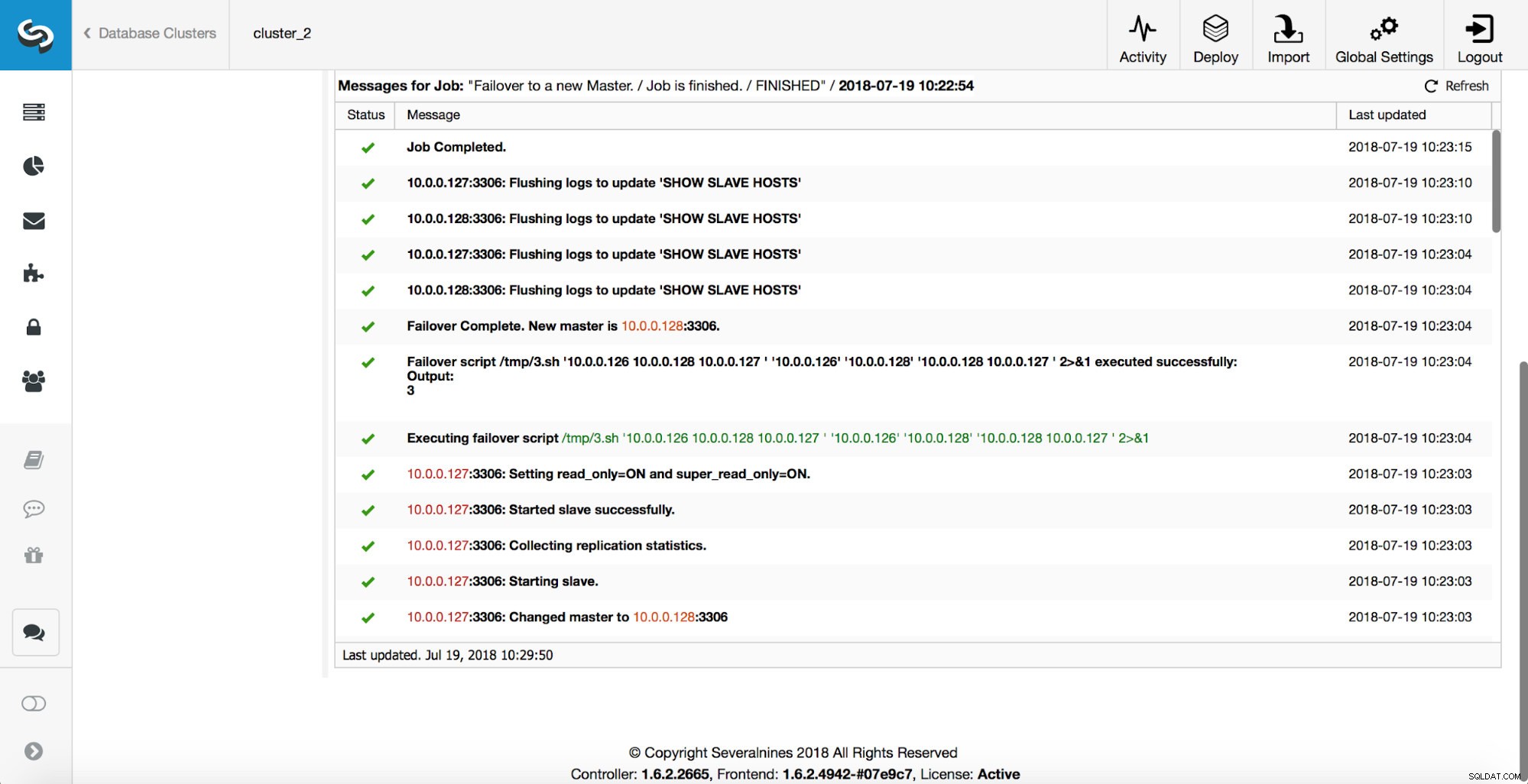
अधिक जांच की जाती है, प्रतिकृतियां रोक दी जाती हैं और नए मास्टर को बंद कर दिया जाता है। अंत में, फ़ेलओवर पूरा होने के बाद, एक अंतिम हुक, 'replication_post_failover_script', चालू हो जाता है।
हुक कब उपयोगी हो सकते हैं?
इस खंड में, हम कुछ ऐसे उदाहरणों के बारे में जानेंगे जहां बाहरी स्क्रिप्ट को लागू करना एक अच्छा विचार हो सकता है। हम किसी भी विवरण में नहीं जाएंगे क्योंकि वे एक विशेष वातावरण से बहुत निकट से संबंधित हैं। यह सुझावों की एक सूची होगी जो लागू करने के लिए उपयोगी हो सकती है।
स्टोनिथ स्क्रिप्ट
शूट द अदर नोड इन द हेड (STONITH) यह सुनिश्चित करने की एक प्रक्रिया है कि पुराना मास्टर, जो मर चुका है, मृत रहेगा (और हाँ .. हम अपने बुनियादी ढांचे में घूमते हुए लाश को पसंद नहीं करते हैं)। आखिरी चीज जो आप शायद चाहते हैं, वह है एक अनुत्तरदायी पुराना मास्टर जो फिर ऑनलाइन वापस आ जाता है और परिणामस्वरूप, आप दो लिखने योग्य स्वामी के साथ समाप्त हो जाते हैं। यह सुनिश्चित करने के लिए आप कुछ सावधानियां बरत सकते हैं कि पुराने मास्टर का उपयोग नहीं किया जाएगा, भले ही वह फिर से दिखाई दे, और इसके लिए ऑफ़लाइन रहना सुरक्षित है। यह सुनिश्चित करने के तरीके पर्यावरण से पर्यावरण में भिन्न होंगे। इसलिए, सबसे अधिक संभावना है, फेलओवर टूल में STONITH के लिए कोई अंतर्निहित समर्थन नहीं होगा। पर्यावरण के आधार पर, आप सीएलआई कमांड निष्पादित करना चाह सकते हैं जो एक वीएम को रोक देगा (और यहां तक कि हटा भी देगा) जिस पर पुराना मास्टर चल रहा है। यदि आपके पास ऑन-प्रिमाइसेस सेटअप है, तो आपका हार्डवेयर पर अधिक नियंत्रण हो सकता है। किसी प्रकार के दूरस्थ प्रबंधन (एकीकृत लाइट-आउट या सर्वर के लिए कुछ अन्य दूरस्थ पहुँच) का उपयोग करना संभव हो सकता है। आपके पास प्रबंधनीय पावर सॉकेट तक भी पहुंच हो सकती है और उनमें से किसी एक में बिजली बंद कर सकते हैं ताकि यह सुनिश्चित हो सके कि सर्वर मानव हस्तक्षेप के बिना फिर से शुरू नहीं होगा।
सेवा खोज
हमने पहले ही सेवा खोज के बारे में कुछ उल्लेख किया है। प्रतिकृति टोपोलॉजी के बारे में जानकारी संग्रहीत करने और यह पता लगाने के कई तरीके हैं कि कौन सा होस्ट मास्टर है। निश्चित रूप से, वर्तमान टोपोलॉजी के बारे में डेटा संग्रहीत करने के लिए etc.d या Consul का उपयोग करना अधिक लोकप्रिय विकल्पों में से एक है। इसके साथ, एक एप्लिकेशन या प्रॉक्सी ट्रैफ़िक को सही नोड पर भेजने के लिए इस डेटा पर भरोसा कर सकता है। ClusterControl (ज्यादातर टूल की तरह जो फेलओवर से निपटने का समर्थन करते हैं) का etc.d या Consul के साथ कोई सीधा एकीकरण नहीं है। टोपोलॉजी डेटा को अपडेट करने का काम यूजर पर होता है। वह कुछ लिपियों को लागू करने और आवश्यक परिवर्तन करने के लिए प्रतिकृति_पोस्ट_फेलओवर_स्क्रिप्ट या प्रतिकृति_पोस्ट_स्विचओवर_स्क्रिप्ट जैसे हुक का उपयोग कर सकती है। यातायात को सही उदाहरणों के लिए निर्देशित करने के लिए DNS का उपयोग करना एक और सुंदर सामान्य समाधान है। यदि आप किसी DNS रिकॉर्ड का टाइम-टू-लाइव कम रखेंगे, तो आपको एक डोमेन परिभाषित करने में सक्षम होना चाहिए, जो आपके मास्टर की ओर इशारा करेगा (अर्थात write.cluster1.example.com)। इसके लिए DNS रिकॉर्ड्स में बदलाव की आवश्यकता है और, फिर से, प्रतिकृति_पोस्ट_फेलओवर_स्क्रिप्ट या प्रतिकृति_पोस्ट_स्विचओवर_स्क्रिप्ट जैसे हुक विफलता के बाद आवश्यक संशोधन करने में वास्तव में सहायक हो सकते हैं।
प्रॉक्सी पुनर्विन्यास
उपयोग किए जाने वाले प्रत्येक प्रॉक्सी सर्वर को सही उदाहरणों के लिए ट्रैफ़िक भेजना होता है। प्रॉक्सी के आधार पर, मास्टर डिटेक्शन कैसे किया जाता है, इसे या तो (आंशिक रूप से) हार्डकोड किया जा सकता है या उपयोगकर्ता जो कुछ भी पसंद करता है उसे परिभाषित करने के लिए हो सकता है। ClusterControl फेलओवर मैकेनिज्म को इस तरह से डिज़ाइन किया गया है कि यह प्रॉक्सी के साथ अच्छी तरह से एकीकृत हो जाता है जिसे इसे तैनात और कॉन्फ़िगर किया गया है। यह अभी भी हो सकता है कि जगह पर प्रॉक्सी हैं, जो क्लस्टर कंट्रोल द्वारा स्थापित नहीं किए गए थे और फेलओवर निष्पादित होने के दौरान उन्हें कुछ मैन्युअल क्रियाओं की आवश्यकता होती है। इस तरह के प्रॉक्सी को बाहरी स्क्रिप्ट और प्रतिकृति_पोस्ट_फेलओवर_स्क्रिप्ट या प्रतिकृति_पोस्ट_स्विचओवर_स्क्रिप्ट जैसे हुक के माध्यम से क्लस्टरकंट्रोल विफलता प्रक्रिया के साथ भी एकीकृत किया जा सकता है।
अतिरिक्त लॉगिंग
ऐसा हो सकता है कि आप डिबगिंग उद्देश्यों के लिए फ़ेलओवर प्रक्रिया का डेटा एकत्र करना चाहें। ClusterControl में व्यापक प्रिंटआउट हैं ताकि यह सुनिश्चित किया जा सके कि प्रक्रिया का पालन करना और यह पता लगाना संभव है कि क्या हुआ और क्यों हुआ। ऐसा अभी भी हो सकता है कि आप कुछ अतिरिक्त, कस्टम जानकारी एकत्र करना चाहें। मूल रूप से सभी हुक का उपयोग यहां किया जा सकता है - आप प्रारंभिक स्थिति एकत्र कर सकते हैं, विफलता से पहले, आप विफलता के सभी चरणों में पर्यावरण की स्थिति को ट्रैक कर सकते हैं।