यह ब्लॉग पोस्ट सीडीपी में डेटा डिस्कवरी और एक्सप्लोरेशन क्लस्टर में होस्ट की गई अपाचे सोलर सेवा द्वारा अनुक्रमित और परोसे जाने वाले डेटा को प्राप्त करने के तरीके पर एक सरल "हैलो वर्ल्ड" उदाहरण प्रस्तुत करेगा। जिज्ञासुओं के लिए:DDE CDP में एक पूर्व-टेम्पलेट सोलर-अनुकूलित क्लस्टर परिनियोजन विकल्प है, और हाल ही में तकनीकी पूर्वावलोकन में जारी किया गया है। . हम इस ब्लॉग में केवल AWS और S3 परिवेशों को कवर करेंगे। Azure और ADLS परिनियोजन विकल्प तकनीकी पूर्वावलोकन में भी उपलब्ध हैं, लेकिन इन्हें भविष्य के ब्लॉग पोस्ट में शामिल किया जाएगा।
आरंभ करना आसान बनाने के लिए हम सबसे सरल परिदृश्य का चित्रण करेंगे। बेशक अधिक उन्नत डेटा पाइपलाइन सेटअप और अधिक समृद्ध स्कीमा संभव हैं, लेकिन यह एक शुरुआत के लिए एक अच्छा प्रारंभिक बिंदु है।
धारणाएं:
- आपके पास पहले से ही एक CDP खाता है और आपके पास उस परिवेश के लिए पावर उपयोगकर्ता या व्यवस्थापक अधिकार हैं जिसमें आप इस सेवा को स्पिन करने की योजना बना रहे हैं।
यदि आपके पास CDP AWS खाता नहीं है, तो कृपया अपने पसंदीदा Cloudera प्रतिनिधि से संपर्क करें, या CDP परीक्षण के लिए यहां साइन अप करें। - आपके पास परिवेश और पहचान को मैप और कॉन्फ़िगर किया गया है। अधिक स्पष्ट रूप से, आपको केवल सीडीपी उपयोगकर्ता की एडब्ल्यूएस भूमिका के मानचित्रण की आवश्यकता है जो उस विशिष्ट एस 3 बाल्टी तक पहुंच प्रदान करता है जिसे आप पढ़ना चाहते हैं (और लिखें)।
- आपके पास एक वर्कलोड (फ्रीआईपीए) पासवर्ड पहले से ही सेट है।
- आपके पास एक डीडीई क्लस्टर चल रहा है। आप यहां सीडीपी डेटा हब में टेम्प्लेट का उपयोग करने के बारे में अधिक जानकारी प्राप्त कर सकते हैं।
- आपके पास उस क्लस्टर तक CLI एक्सेस है।
- SSH पोर्ट आपके IP पते के लिए AWS पर खुला है। आप डेटाहब क्लस्टर विवरण के भीतर सोलर नोड्स में से किसी एक के लिए सार्वजनिक आईपी पता प्राप्त कर सकते हैं। यहां जानें कि AWS क्लस्टर में SSH कैसे करें।
- आपके पास एक S3 बकेट में एक लॉग फ़ाइल है जो आपके उपयोगकर्ता के लिए पहुँच योग्य है (
/sample.log इस उदाहरण में)। यदि आपके पास एक नहीं है, तो हमारे द्वारा उपयोग किए गए लिंक का लिंक यहां दिया गया है।
कार्यप्रवाह
निम्न अनुभाग आपको डीडीई के साथ बॉक्स से बाहर आने वाले क्रंच इंडेक्सर टूल का उपयोग करके डेटा अनुक्रमित करने के चरणों के बारे में बताएंगे।

अपनी अनुक्रमणिका धारण करने के लिए एक संग्रह बनाएं
HUE में एक इंडेक्स डिज़ाइनर होता है; हालांकि, जब तक डीडीई तकनीकी पूर्वावलोकन में है, यह कुछ हद तक पुनर्निर्माण के अधीन होगा और इस बिंदु पर इसकी अनुशंसा नहीं की जाती है। लेकिन डीडीई के जीए जाने के बाद कृपया इसे आजमाएं, और हमें बताएं कि आप क्या सोचते हैं।
अभी के लिए, आप CLI टूल 'solrctl' का उपयोग करके अपना सोलर स्कीमा और कॉन्फिग बना सकते हैं। 'माई-ओन-लॉग्स-कॉन्फ़िगरेशन' नामक एक कॉन्फिगरेशन बनाएं और 'माय-ओन-लॉग्स' नामक एक संग्रह बनाएं। इसके लिए आवश्यक है कि आपके पास CLI एक्सेस हो।
1. आपके क्लस्टर में किसी भी कार्यकर्ता नोड को SSH।
2. संग्रह कॉन्फ़िगरेशन बनाने की अनुमति वाले उपयोगकर्ता के रूप में kinit:
किनिट
3. सुनिश्चित करें कि SOLR_ZK_ENSEMBLE पर्यावरण चर /etc/solr/conf/solr-env.sh में सेट है। इसके मूल्य को बचाएं क्योंकि आगे के चरणों में इसकी आवश्यकता होगी।
एंटर दबाएं और अपना वर्कलोड (फ्रीआईपीए) पासवर्ड टाइप करें।
उदाहरण के लिए:
cat /etc/solr/conf/solr-env.sh
अपेक्षित आउटपुट:
निर्यात SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
यह क्लाउडेरा मैनेजर में सोलर सर्वर या गेटवे भूमिका वाले होस्ट पर अपने आप सेट हो जाता है।
4. संग्रह के लिए कॉन्फ़िगरेशन फ़ाइलें जेनरेट करने के लिए, निम्न आदेश चलाएँ:
solrctl config -- create my-owner-logs-config schemalessTemplate -p immutable=false
schemalessTemplate सीडीपी में सोलर के साथ भेजे गए डिफ़ॉल्ट टेम्पलेट्स में से एक है, लेकिन एक टेम्पलेट होने के नाते, यह अपरिवर्तनीय है। इस वर्कफ़्लो के प्रयोजनों के लिए, आपको इसे कॉपी करने और इस प्रकार एक नया बनाने की आवश्यकता है जो कि परिवर्तनशील हो (यह वही है जो अपरिवर्तनीय =गलत विकल्प करता है)। यह आपको एक लचीला, स्कीमा रहित कॉन्फ़िगरेशन प्रदान करता है। एक अच्छी तरह से डिज़ाइन किया गया स्कीमा बनाना डिज़ाइन समय में निवेश करने लायक कुछ है, लेकिन खोजपूर्ण उपयोग के लिए आवश्यक नहीं है। इस कारण से यह इस ब्लॉग पोस्ट के दायरे से बाहर है। हालांकि वास्तविक उत्पादन परिवेश में, हम अच्छी तरह से डिज़ाइन किए गए स्कीमा के उपयोग की दृढ़ता से अनुशंसा करते हैं - और यदि आवश्यक हो तो हम विशेषज्ञ सहायता प्रदान करने में प्रसन्न हैं!
5. निम्न आदेश का उपयोग करके एक नया संग्रह बनाएं:
solrctl संग्रह -- my-owner-logs -s 1 -c my-owner-logs-configबनाएं
यह एक शार्ड पर "my-owner-logs-config" संग्रह कॉन्फ़िगरेशन के आधार पर "my-owner-logs" संग्रह बनाता है।
6. यह सत्यापित करने के लिए कि संग्रह बनाया गया है, आप सोलर व्यवस्थापक UI पर नेविगेट कर सकते हैं। "माई-ओन-लॉग्स" का संग्रह बाएं नेविगेशन पर ड्रॉप-डाउन के माध्यम से उपलब्ध होगा।

अपना डेटा अनुक्रमित करें
यहां हम एक सरल उदाहरण का उपयोग करते हुए वर्णन करते हैं कि S3 में डेटा को त्वरित रूप से अनुक्रमित करने और DDE में सोलर के माध्यम से सेवा करने के लिए अंतर्निहित क्रंच इंडेक्सर टूल को कैसे कॉन्फ़िगर और चलाया जाए। चूंकि क्लस्टर सुरक्षित करने से सीएम ऑटो टीएलएस, नॉक्स, केर्बरोस और रेंजर का उपयोग हो सकता है, 'स्पार्क सबमिट' इस पोस्ट में शामिल नहीं किए गए पहलुओं पर निर्भर हो सकता है।
S3 से अनुक्रमण डेटा HDFS से अनुक्रमण के समान ही है।
यार्न वर्कर नोड (प्रबंधन कंसोल वेबयूआई पर "यार्नवर्कर" के रूप में संदर्भित) पर इन चरणों का पालन करें।
1. सोलर व्यवस्थापक उपयोगकर्ता के रूप में DDE क्लस्टर के समर्पित यार्न वर्कर नोड को SSH।
यार्न वर्कर नोड का IP पता जानने के लिए, हार्डवेयर पर क्लिक करें। क्लस्टर विवरण पृष्ठ पर टैब करें, फिर "यार्नवर्कर" नोड तक स्क्रॉल करें।

2. अपनी संसाधन निर्देशिका पर जाएं (या यदि आपके पास पहले से नहीं है तो एक बनाएं:
cd
संसाधन निर्देशिका के रूप में व्यवस्थापक उपयोगकर्ता के होम फ़ोल्डर का उपयोग करें (
3. अपने उपयोगकर्ता को किनीट करें :
किनिट
एंटर दबाएं और अपना वर्कलोड (फ्रीआईपीए) पासवर्ड टाइप करें।
4.
curl --negotiate -u:"https://: /solr/admin?op=GETDELEGATIONTOKEN" --insecure> tokenFile.txt
5. इस उदाहरण में क्रंच इंडेक्सर टूल, read-log-morphline.conf के लिए मॉर्फलाइन कॉन्फ़िगरेशन फ़ाइल बनाएं। बदलें
SOLR_LOCATOR :{ # सोलर संग्रह संग्रह का नाम :my-owner-logs #zk पहनावा zkHost :
यह मॉर्फलाइन दी गई लॉग फ़ाइल से स्टैक ट्रेस को पढ़ती है, फिर एक डीबग प्रविष्टि लॉग लिखती है और इसे निर्दिष्ट सोलर पर लोड करती है।
6. लॉग कॉन्फ़िगरेशन के लिए log4j.properties फ़ाइल बनाएँ:
log4j.rootLogger=INFO, A1# A1 को ConsoleAppender.log4j.appender.A1=org.apache.log4j.ConsoleAppender# A1 के रूप में सेट किया गया है PatternLayout.log4j.appender.A1.layout=org.apache.log4j का उपयोग करता है .PatternLayoutlog4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. जांचें कि क्या आप जिस फ़ाइल को पढ़ना चाहते हैं वह S3 पर मौजूद है (यदि आपके पास एक नहीं है, तो यहां एक लिंक है जिसे हमने इस सरल उदाहरण के लिए उपयोग किया है:
aws s3 ls s3://
8. स्पार्क-सबमिट कमांड चलाएँ:
प्लेसहोल्डर्स को में बदलें और आपके द्वारा निर्धारित मूल्यों के साथ।
निर्यात करें मैक्सडेप्थ 1-नाम 'सर्च-क्रंच- *। जार'! -नाम '*-जॉब.जर'! -नाम '*-sources.jar') एक्सपोर्ट माय डिपेंडेंसीजारफाइल्स =$ ($ माय डिपेंडेंसी जारडिर -नाम '*। जार' खोजें | सॉर्ट | tr '\ n' ',' | हेड-सी -1) myDependencyJarPaths =$ निर्यात करें ($ myDependencyJarDir -name '*.jar' | सॉर्ट | tr '\n' ':' | हेड-सी -1) निर्यात myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ "export myResourcesDir=" अगर आपको ऐसा ही कोई संदेश मिलता है, तो आप उसे नज़रअंदाज़ कर सकते हैं:
चेतावनी मेटाडेटा.हाइव:सभी functions.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportExceptionको पंजीकृत करने में विफल
9. कमांड के निष्पादन की निगरानी के लिए, संसाधन प्रबंधक पर जाएँ।

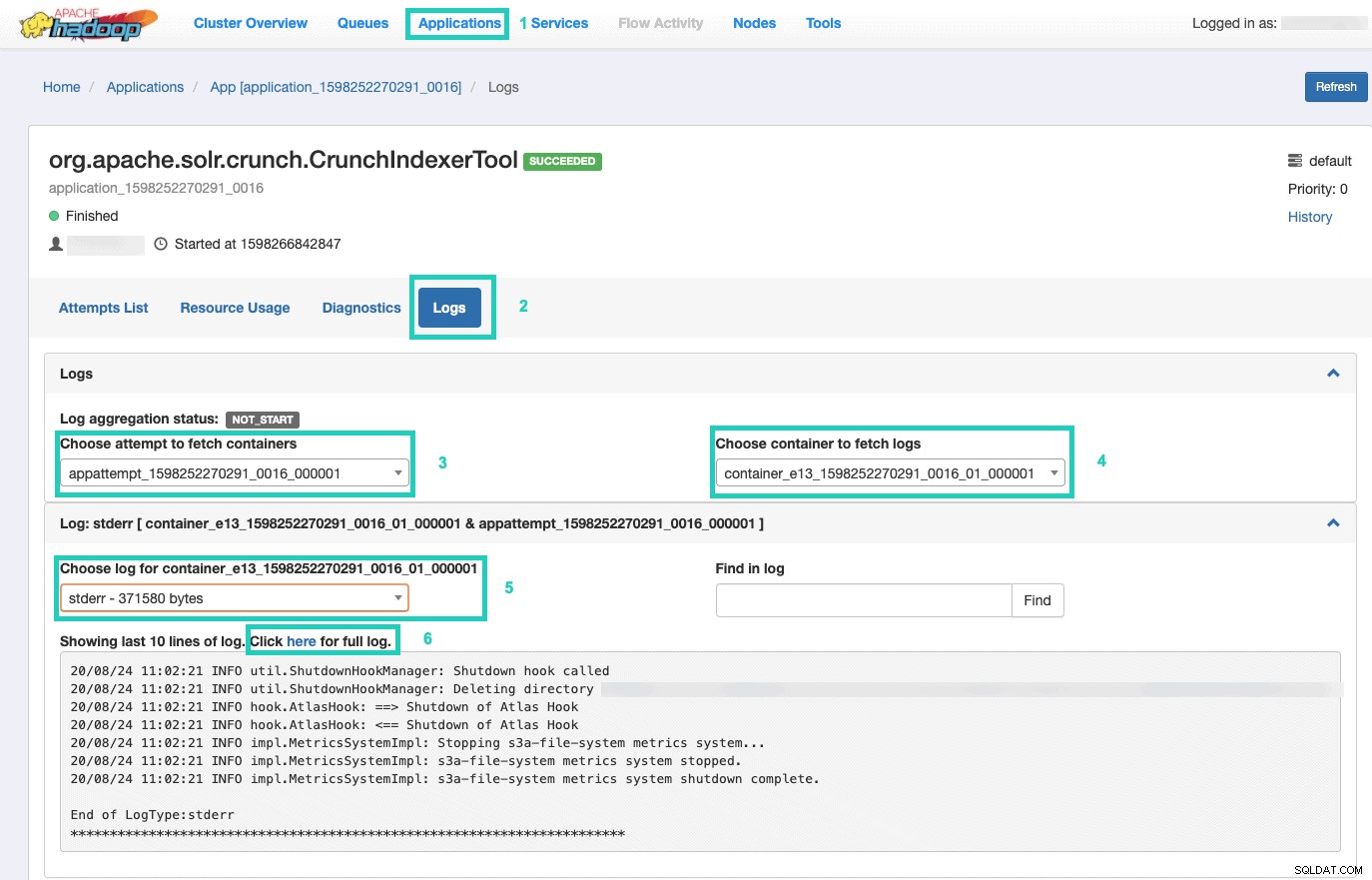
वहां पहुंचने के बाद, एप्लिकेशन . चुनें टैब > एप्लिकेशन आईडी . क्लिक करें आप जिस एप्लिकेशन प्रयास की निगरानी करना चाहते हैं उसकी > लॉग> कंटेनर लाने का प्रयास चुनें> लॉग लाने के लिए कंटेनर चुनें> कंटेनर के लिए लॉग चुनें> चुनें stderr . चुनें लॉग> पूर्ण लॉग के लिए यहां क्लिक करें . पर क्लिक करें ।
अपना अनुक्रमणिका प्रस्तुत करें
आपके पास अंतिम उपयोगकर्ताओं को खोजने योग्य अनुक्रमित डेटा की सेवा करने के कई विकल्प हैं। आप सोलर के समृद्ध एपीआई (बहुत सामान्य) के आधार पर अपना खुद का समृद्ध एप्लिकेशन बना सकते हैं। आप अपने पसंदीदा तृतीय पक्ष टूल, जैसे Qlik, झांकी आदि को उनके प्रमाणित सोलर कनेक्शन से कनेक्ट कर सकते हैं। प्रोटोटाइप एप्लिकेशन बनाने के लिए आप ह्यू के सरल सोलर डैशबोर्ड का उपयोग कर सकते हैं।
बाद वाला करने के लिए:
1. ह्यू पर जाएं।

2. डैशबोर्ड दृश्य में, पसंद की अनुक्रमणिका फ़ाइल पर नेविगेट करें (उदा. जिसे आपने अभी बनाया है)।
3. विभिन्न डैशबोर्ड तत्वों को खींचना और छोड़ना प्रारंभ करें और उपलब्ध दृश्य के लिए डेटा को पॉप्युलेट करने के लिए अनुक्रमणिका से फ़ील्ड का चयन करें।
प्रेरणा के लिए अतीत से एक त्वरित डैशबोर्ड ट्यूटोरियल वीडियो यहां पाया जा सकता है।
हम भविष्य के ब्लॉग पोस्ट के लिए एक गहरा गोता लगाएंगे।
सारांश
हमें उम्मीद है कि आपने इस ब्लॉग पोस्ट से क्रंच इंडेक्सर टूल का उपयोग करके डीडीई में सोलर द्वारा अनुक्रमित S3 में डेटा प्राप्त करने के बारे में बहुत कुछ सीखा है। बेशक कई अन्य तरीके हैं (डेटा इंजीनियरिंग अनुभव में स्पार्क, डेटा प्रवाह अनुभव में निफी, स्ट्रीम प्रबंधन अनुभव में काफ्का, और इसी तरह), लेकिन वे भविष्य के ब्लॉग पोस्ट में शामिल होंगे। हम आशा करते हैं कि आप टेक्स्ट और अन्य असंरचित डेटा को शामिल करते हुए शक्तिशाली अंतर्दृष्टि अनुप्रयोगों के निर्माण पर अपनी निरंतर यात्रा में बहुत सफल रहे हैं। यदि आप डीडीई को सीडीपी में आज़माने का निर्णय लेते हैं, तो कृपया हमें बताएं कि यह सब कैसे हुआ!



