एकत्रीकरण के साथ, पूरी क्वेरी को MongoDB सर्वर पर एकल प्रक्रिया के रूप में निष्पादित किया जाता है - एप्लिकेशन प्रोग्राम सर्वर से परिणाम कर्सर प्राप्त करेगा।
जावा प्रोग्राम के साथ भी आपको एप्लिकेशन में प्रोसेसिंग के इनपुट के रूप में डेटाबेस सर्वर से एक कर्सर मिल रहा है। सर्वर से प्रतिक्रिया कर्सर डेटा का बड़ा सेट होने वाला है और अधिक नेटवर्क बैंडविड्थ का उपयोग करेगा। और फिर एप्लिकेशन प्रोग्राम में प्रोसेसिंग होती है, और यह क्वेरी को पूरा करने के लिए और चरण जोड़ता है।
मुझे लगता है कि एकत्रीकरण विकल्प एक बेहतर विकल्प है - क्योंकि सभी प्रसंस्करण (प्रारंभिक मिलान और सरणी को फ़िल्टर करना) डेटाबेस सर्वर पर एक ही प्रक्रिया के रूप में होता है।
साथ ही, ध्यान दें कि आपके द्वारा पोस्ट किए गए एकत्रीकरण क्वेरी चरणों को एक कुशल तरीके से किया जा सकता है। कई चरणों (2, 3, 4 और 5) के बजाय आप उन कार्यों को दो चरणों . में कर सकते हैं - एक $project . का उपयोग करें $map . के साथ बाहरी सरणी पर और फिर $filter आंतरिक सरणी पर और फिर $filter बाहरी सरणी।
एकत्रीकरण:
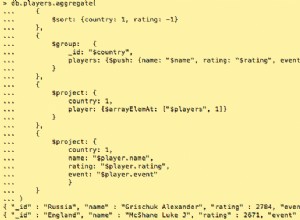
db.test.aggregate( [
{
$addFields: {
Field2: {
$map: {
input: "$Field2",
as: "fld2",
in: {
Field3: "$$fld2.Field3",
Field4: {
$filter: {
input: "$$fld2.Field4",
as: "fld4",
cond: { $eq: [ "$$fld4.id", "123" ] }
}
}
}
}
}
}
},
{
$addFields: {
Field2: {
$filter: {
input: "$Field2",
as: "f2",
cond: { $gt: [ { $size: "$$f2.Field4" }, 0 ] }
}
}
}
},
] )