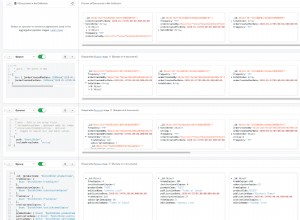
आप इससे दो अलग-अलग तरीकों से निपट सकते हैं। वे निश्चित रूप से दृष्टिकोण और प्रदर्शन पर भिन्न होते हैं, और मुझे लगता है कि कुछ बड़े विचार हैं जिन्हें आपको अपने डिजाइन में बनाने की आवश्यकता है। सबसे विशेष रूप से यहां आपके वास्तविक एप्लिकेशन के उपयोग पैटर्न में "संशोधन" डेटा की "आवश्यकता" है।
समग्र द्वारा क्वेरी
"आंतरिक सरणी से अंतिम तत्व" प्राप्त करने के सबसे महत्वपूर्ण बिंदु के लिए, तो आपको वास्तव में एक .aggregate()
ऐसा करने के लिए ऑपरेशन:
function getProject(req,projectId) {
return new Promise((resolve,reject) => {
Project.aggregate([
{ "$match": { "project_id": projectId } },
{ "$addFields": {
"uploaded_files": {
"$map": {
"input": "$uploaded_files",
"as": "f",
"in": {
"latest": {
"$arrayElemAt": [
"$$f.history",
-1
]
},
"_id": "$$f._id",
"display_name": "$$f.display_name"
}
}
}
}},
{ "$lookup": {
"from": "owner_collection",
"localField": "owner",
"foreignField": "_id",
"as": "owner"
}},
{ "$unwind": "$uploaded_files" },
{ "$lookup": {
"from": "files_collection",
"localField": "uploaded_files.latest.file",
"foreignField": "_id",
"as": "uploaded_files.latest.file"
}},
{ "$group": {
"_id": "$_id",
"project_id": { "$first": "$project_id" },
"updated_at": { "$first": "$updated_at" },
"created_at": { "$first": "$created_at" },
"owner" : { "$first": { "$arrayElemAt": [ "$owner", 0 ] } },
"name": { "$first": "$name" },
"uploaded_files": {
"$push": {
"latest": { "$arrayElemAt": [ "$$uploaded_files", 0 ] },
"_id": "$$uploaded_files._id",
"display_name": "$$uploaded_files.display_name"
}
}
}}
])
.then(result => {
if (result.length === 0)
reject(new createError.NotFound(req.path));
resolve(result[0])
})
.catch(reject)
})
}
चूंकि यह एक एग्रीगेशन स्टेटमेंट है जहां हम अतिरिक्त अनुरोध करने के विपरीत "सर्वर" पर "जॉइन" भी कर सकते हैं (जो कि .populate() है। वास्तव में यहाँ करता है) $lookup का उपयोग करके
, मैं वास्तविक संग्रह नामों के साथ कुछ स्वतंत्रता ले रहा हूं क्योंकि आपकी स्कीमा प्रश्न में शामिल नहीं है। कोई बात नहीं, क्योंकि आपको नहीं पता था कि आप वास्तव में इसे इस तरह से कर सकते हैं।
बेशक "वास्तविक" संग्रह नाम सर्वर द्वारा आवश्यक हैं, जिसमें "एप्लिकेशन पक्ष" परिभाषित स्कीमा की कोई अवधारणा नहीं है। आप यहां सुविधा के लिए कुछ चीजें कर सकते हैं, लेकिन उस पर और बाद में।
आपको यह भी ध्यान रखना चाहिए कि projectId . के आधार पर वास्तव में से आता है, फिर नियमित नेवला विधियों जैसे .find() . के विपरीत $मिलान एक ObjectId . पर वास्तव में "कास्टिंग" की आवश्यकता होगी यदि इनपुट मान वास्तव में "स्ट्रिंग" है। नेवला एक एकत्रीकरण पाइपलाइन में "स्कीमा प्रकार" लागू नहीं कर सकता है, इसलिए आपको इसे स्वयं करने की आवश्यकता हो सकती है, खासकर यदि projectId अनुरोध पैरामीटर से आया है:
{ "$match": { "project_id": Schema.Types.ObjectId(projectId) } },
यहां मूल भाग वह है जहां हम $map
सभी "uploaded_files" . के माध्यम से पुनरावृति करने के लिए प्रविष्टियाँ, और फिर बस "इतिहास" . से "नवीनतम" निकालें सरणी $arrayElemAt के साथ
"अंतिम" अनुक्रमणिका का उपयोग करना, जो कि -1 . है ।
यह उचित होना चाहिए क्योंकि यह सबसे अधिक संभावना है कि "सबसे हालिया संशोधन" वास्तव में "अंतिम" सरणी प्रविष्टि है। $अधिकतम
एक शर्त के रूप में $filter
. ताकि पाइपलाइन चरण बन जाए:
{ "$addFields": {
"uploaded_files": {
"$map": {
"input": "$uploaded_files",
"as": "f",
"in": {
"latest": {
"$arrayElemAt": [
{ "$filter": {
"input": "$$f.history.revision",
"as": "h",
"cond": {
"$eq": [
"$$h",
{ "$max": "$$f.history.revision" }
]
}
}},
0
]
},
"_id": "$$f._id",
"display_name": "$$f.display_name"
}
}
}
}},
जो कमोबेश एक ही बात है, सिवाय इसके कि हम से तुलना करते हैं। $अधिकतम
मान, और केवल "एक" return लौटाएं "फ़िल्टर्ड" सरणी से "प्रथम" स्थिति, या 0 पर लौटने के लिए अनुक्रमणिका बनाने वाले सरणी से प्रविष्टि सूचकांक।
$lookup का उपयोग करने की अन्य सामान्य तकनीकों के संबंध में
.populate() . के स्थान पर , मेरी प्रविष्टि देखें "नेवला में आबादी के बाद पूछताछ"
जो उन चीजों के बारे में कुछ और बात करता है जिन्हें इस दृष्टिकोण को अपनाने पर अनुकूलित किया जा सकता है।
पॉप्युलेट द्वारा क्वेरी
इसके अलावा हम .populate() का उपयोग करके एक ही प्रकार का ऑपरेशन कर सकते हैं (भले ही उतनी कुशलता से नहीं) कॉल और परिणामी सरणियों में हेरफेर:
Project.findOne({ "project_id": projectId })
.populate(populateQuery)
.lean()
.then(project => {
if (project === null)
reject(new createError.NotFound(req.path));
project.uploaded_files = project.uploaded_files.map( f => ({
latest: f.history.slice(-1)[0],
_id: f._id,
display_name: f.display_name
}));
resolve(project);
})
.catch(reject)
बेशक आप वास्तव में "इतिहास" . से "सभी" आइटम वापस कर रहे हैं , लेकिन हम केवल एक .map लागू करते हैं। ()
.slice()<का आह्वान करने के लिए /कोड>
उन तत्वों पर फिर से प्रत्येक के लिए अंतिम सरणी तत्व प्राप्त करने के लिए।
थोड़ा और ओवरहेड क्योंकि सारा इतिहास वापस आ गया है, और .populate() कॉल अतिरिक्त अनुरोध हैं, लेकिन इसके अंतिम परिणाम समान होते हैं।
डिज़ाइन का एक बिंदु
मुख्य समस्या जो मैं यहाँ देख रहा हूँ, वह यह है कि आपके पास सामग्री के भीतर एक "इतिहास" सरणी भी है। यह वास्तव में एक अच्छा विचार नहीं है क्योंकि आपको केवल वही प्रासंगिक वस्तु वापस करने के लिए उपरोक्त चीजों को करने की आवश्यकता है जो आप चाहते हैं।
तो "डिजाइन के बिंदु" के रूप में, मैं ऐसा नहीं करूँगा। लेकिन इसके बजाय मैं सभी मामलों में इतिहास को वस्तुओं से "अलग" कर दूंगा। "एम्बेडेड" दस्तावेज़ों को ध्यान में रखते हुए, मैं "इतिहास" को एक अलग सरणी में रखूंगा, और केवल "नवीनतम" संशोधन को वास्तविक सामग्री के साथ रखूंगा:
{
"_id" : ObjectId("5935a41f12f3fac949a5f925"),
"project_id" : 13,
"updated_at" : ISODate("2017-07-02T22:11:43.426Z"),
"created_at" : ISODate("2017-06-05T18:34:07.150Z"),
"owner" : ObjectId("591eea4439e1ce33b47e73c3"),
"name" : "Demo project",
"uploaded_files" : [
{
"latest" : {
{
"file" : ObjectId("59596f9fb6c89a031019bcae"),
"revision" : 1
}
},
"_id" : ObjectId("59596f9fb6c89a031019bcaf"),
"display_name" : "Example filename.txt"
}
]
"file_history": [
{
"_id": ObjectId("59596f9fb6c89a031019bcaf"),
"file": ObjectId("59596f9fb6c89a031019bcae"),
"revision": 0
},
{
"_id": ObjectId("59596f9fb6c89a031019bcaf"),
"file": ObjectId("59596f9fb6c89a031019bcae"),
"revision": 1
}
}
आप इसे आसानी से $set सेट करके रख सकते हैं।
प्रासंगिक प्रविष्टि और $push का उपयोग करना
एक ऑपरेशन में "इतिहास" पर:
.update(
{ "project_id": projectId, "uploaded_files._id": fileId }
{
"$set": {
"uploaded_files.$.latest": {
"file": revisionId,
"revision": revisionNum
}
},
"$push": {
"file_history": {
"_id": fileId,
"file": revisionId,
"revision": revisionNum
}
}
}
)
सरणी अलग होने के साथ, आप बस क्वेरी कर सकते हैं और हमेशा नवीनतम प्राप्त कर सकते हैं, और "इतिहास" को तब तक त्याग सकते हैं जब तक आप वास्तव में वह अनुरोध करना चाहते हैं:
Project.findOne({ "project_id": projectId })
.select('-file_history') // The '-' here removes the field from results
.populate(populateQuery)
एक सामान्य मामले के रूप में हालांकि मैं "संशोधन" संख्या से बिल्कुल भी परेशान नहीं होगा। एक ही संरचना को रखते हुए आपको वास्तव में इसकी आवश्यकता नहीं होती है जब "नवीनतम" हमेशा "अंतिम" होने के बाद से किसी सरणी में "संलग्न" होता है। यह संरचना को बदलने के बारे में भी सच है, जहां फिर से "नवीनतम" हमेशा दी गई अपलोड की गई फ़ाइल के लिए अंतिम प्रविष्टि होगी।
इस तरह के "कृत्रिम" सूचकांक को बनाए रखने की कोशिश करना समस्याओं से भरा है, और ज्यादातर "परमाणु" संचालन के किसी भी बदलाव को बर्बाद कर देता है जैसा कि .update() में दिखाया गया है। उदाहरण यहां, चूंकि आपको नवीनतम संशोधन संख्या प्रदान करने के लिए "काउंटर" मान जानने की आवश्यकता है, और इसलिए इसे कहीं से "पढ़ने" की आवश्यकता है।