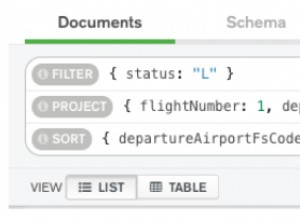
सामान्य तौर पर, आप अपने सबसे महत्वपूर्ण/लगातार प्रश्नों में फ़िल्टर मानदंड के रूप में सबसे अधिक उपयोग किए जाने वाले फ़ील्ड पर एक अनुक्रमणिका रखना चाहेंगे, सबसे पहले सबसे चुनिंदा फ़ील्ड से शुरू करें। MongoDB दस्तावेज़ीकरण के भाग के रूप में कुछ अच्छे विषय पर मार्गदर्शन
है। . आपके मामले में विशेष रुचि का एक कथन शायद यह है क्योंकि आपके पास बहुत सारे $or . हैं रों:
हालांकि, यहां सबसे महत्वपूर्ण बात व्याख्या करें () . इसका कारण यह है कि सबसे अधिक संभावना है कि आपके पास विभिन्न प्रकार के प्रश्न होंगे जिन्हें आपके आवेदन का समर्थन करने की आवश्यकता है और आपको किसी बिंदु पर ट्रेड-ऑफ के लिए जाना होगा जहां आपको इंडेक्स रखरखाव लागतों के बीच चयन करना होगा (उदाहरण के लिए लॉक लिखें इंडेक्स अपडेट और डिस्क स्पेस आवश्यकताओं के दौरान) और सैद्धांतिक रूप से सबसे तेज़ समाधान जहां एक ही क्वेरी में उपयोग किए जाने वाले सभी फ़ील्ड एक ही इंडेक्स द्वारा कवर किए जाते हैं।
वह संपूर्ण अनुक्रमण विषय थोड़ा अस्पष्ट है जो आपके सटीक परिदृश्य पर बहुत अधिक निर्भर करता है:
- क्या आपका डेटा अत्यधिक अपडेट किया गया है और क्या राइट्स को सुपर-फास्ट होने की आवश्यकता है (आप कम/छोटे इंडेक्स चाहते हैं) या क्या आपका डेटा लगातार पढ़ने के साथ बहुत स्थिर है जिसे तेज़ होना है (अधिक/बड़े इंडेक्स के साथ जाएं)?
- आपको किस प्रकार के प्रश्नों का समर्थन करने की आवश्यकता है? वे अपने फ़िल्टर के मामले में कितने समान हैं? क्या फ़िल्टर के कुछ संयोजन दूसरों की तुलना में अधिक होने की संभावना है? किन प्रश्नों को अच्छा प्रदर्शन करने की आवश्यकता है, कौन से प्रश्न थोड़े धीमे हो सकते हैं?
- आपके संभावित रूप से अनुक्रमित फ़ील्ड में डेटा कैसे वितरित किया जाता है?
- और इसी तरह...
आपको एक भी इंडेक्स नहीं मिलेगा जो आपके सभी प्रश्नों को सर्वश्रेष्ठ प्रदर्शन करने में मदद करता है। और साथ ही, जब अधिक इंडेक्स जोड़ते हैं या मौजूदा बदलते हैं, तो यह क्वेरी ऑप्टिमाइज़र को कुछ प्रश्नों के लिए कुछ इंडेक्स का उपयोग करना बंद कर सकता है और इसके बजाय एक अलग निष्पादन योजना चुन सकता है जो वांछित हो सकता है या नहीं। इसलिए अपने इंडेक्सिंग या भौतिक डेटा लेआउट (हार्डवेयर सेटअप, शार्डिंग...) में किसी भी बदलाव के लिए जो कुछ भी महत्वपूर्ण है, उसे मापें। अंत में, आपको अपने क्वेरी प्रदर्शन को नियमित आधार पर मापना चाहिए क्योंकि आपके डेटा की मात्रा बढ़ती है जब तक कि यह वितरण में अनुमानित रूप से एक समान न हो।
एक लंबी कहानी को छोटा करने के लिए:एक पुनरावृत्त दृष्टिकोण के लिए जाएं और एक इंडेक्स जोड़कर शुरू करें (मैं isBlockedByAdmin पर एक जोड़ने का सुझाव दूंगा। , isDelete और information.shares.userId ) फिर अपने क्वेरी प्रदर्शन को मापें और फिर अपने निष्कर्षों के आधार पर अपनी अनुक्रमणिका परिशोधित करें (और बार-बार, ...).