MongoDB एक NoSQL डेटाबेस है जो विभिन्न प्रकार के इनपुट डेटासेट स्रोतों का समर्थन करता है। यह लचीले JSON जैसे दस्तावेज़ों में डेटा संग्रहीत करने में सक्षम है, जिसका अर्थ फ़ील्ड या मेटाडेटा दस्तावेज़ से दस्तावेज़ में भिन्न हो सकता है और समय के साथ डेटा संरचना को बदला जा सकता है। दस्तावेज़ मॉडल एप्लिकेशन कोड में ऑब्जेक्ट्स को मैप करके डेटा को काम करना आसान बनाता है। MongoDB को इसके मूल में एक वितरित डेटाबेस के रूप में भी जाना जाता है, इसलिए उच्च उपलब्धता, क्षैतिज स्केलिंग और भौगोलिक वितरण अंतर्निहित और उपयोग में आसान हैं। यह मॉडल प्रशिक्षण के लिए मापदंडों को मूल रूप से संशोधित करने की क्षमता के साथ आता है। डेटा वैज्ञानिक इस मॉडल पीढ़ी के साथ डेटा की संरचना को आसानी से मर्ज कर सकते हैं।
मशीन लर्निंग क्या है?
मशीन लर्निंग कंप्यूटर को सीखने और इंसानों की तरह कार्य करने और स्वायत्त तरीके से समय के साथ अपने सीखने में सुधार करने का विज्ञान है। सीखने की प्रक्रिया अवलोकन या डेटा से शुरू होती है, जैसे उदाहरण, प्रत्यक्ष अनुभव, या निर्देश, डेटा में पैटर्न देखने और भविष्य में हमारे द्वारा प्रदान किए गए उदाहरणों के आधार पर बेहतर निर्णय लेने के लिए। प्राथमिक उद्देश्य कंप्यूटर को मानवीय हस्तक्षेप या सहायता के बिना स्वचालित रूप से सीखने और उसके अनुसार कार्यों को समायोजित करने की अनुमति देना है।
एक रिच प्रोग्रामिंग और क्वेरी मॉडल
MongoDB, MongoDB के डेटा के साथ मशीन लर्निंग मॉडल बनाने वाले डेवलपर्स और डेटा वैज्ञानिकों के लिए मूल ड्राइवर और प्रमाणित कनेक्टर दोनों प्रदान करता है। PyMongo, MongoDB सिंटैक्स को Python कोड में एम्बेड करने के लिए एक बेहतरीन लाइब्रेरी है। हम MongoDB के सभी कार्यों और विधियों को अपने मशीन लर्निंग कोड में उपयोग करने के लिए आयात कर सकते हैं। एकल कोड में बहु-भाषा कार्यक्षमता प्राप्त करने के लिए यह एक बेहतरीन तकनीक है। अतिरिक्त लाभ यह है कि आप एक कुशल एप्लिकेशन बनाने के लिए उन प्रोग्रामिंग भाषाओं की आवश्यक सुविधाओं का उपयोग कर सकते हैं।
रिच सेकेंडरी इंडेक्स वाली MongoDB क्वेरी भाषा डेवलपर्स को ऐसे एप्लिकेशन बनाने में सक्षम बनाती है जो डेटा को कई आयामों में क्वेरी और विश्लेषण कर सकते हैं। जटिल एकत्रीकरण और MapReduce नौकरियों के माध्यम से डेटा को एकल कुंजी, श्रेणियों, पाठ खोज, ग्राफ़ और भू-स्थानिक प्रश्नों द्वारा पहुँचा जा सकता है, मिलीसेकंड में प्रतिक्रियाएँ लौटाता है।
एक वितरित डेटाबेस क्लस्टर में डेटा प्रोसेसिंग को समानांतर करने के लिए, MongoDB एकत्रीकरण पाइपलाइन और MapReduce प्रदान करता है। MongoDB एकत्रीकरण पाइपलाइन को डेटा प्रोसेसिंग पाइपलाइनों की अवधारणा के साथ तैयार किया गया है। दस्तावेज़ एक बहु-चरण पाइपलाइन में प्रवेश करते हैं जो MongoDB के भीतर निष्पादित मूल संचालन का उपयोग करके दस्तावेज़ों को एक समग्र परिणाम में बदल देता है। सबसे बुनियादी पाइपलाइन चरण फ़िल्टर प्रदान करते हैं जो प्रश्नों की तरह काम करते हैं, और दस्तावेज़ परिवर्तन जो आउटपुट दस्तावेज़ के रूप को संशोधित करते हैं। अन्य पाइपलाइन संचालन विशिष्ट क्षेत्रों के साथ-साथ दस्तावेज़ों की सरणियों सहित, सरणियों की सामग्री को एकत्र करने के लिए उपकरण के साथ-साथ दस्तावेजों को समूहीकृत करने और छाँटने के लिए उपकरण प्रदान करते हैं। इसके अलावा, पाइपलाइन चरण दस्तावेजों के संग्रह में औसत या मानक विचलन की गणना करने और स्ट्रिंग्स में हेरफेर करने जैसे कार्यों के लिए ऑपरेटरों का उपयोग कर सकते हैं। MongoDB मैप को निष्पादित करने और चरणों को कम करने के लिए कस्टम जावास्क्रिप्ट फ़ंक्शन का उपयोग करके डेटाबेस के भीतर मूल MapReduce संचालन भी प्रदान करता है।
अपने मूल क्वेरी ढांचे के अलावा, MongoDB Apache Spark के लिए एक उच्च प्रदर्शन कनेक्टर भी प्रदान करता है। कनेक्टर स्पार्क के सभी पुस्तकालयों को उजागर करता है, जिसमें पायथन, आर, स्काला और जावा शामिल हैं। MongoDB डेटा को मशीन लर्निंग, ग्राफ़, स्ट्रीमिंग और SQL API के साथ विश्लेषण के लिए DataFrames और Datasets के रूप में अमल में लाया जाता है।
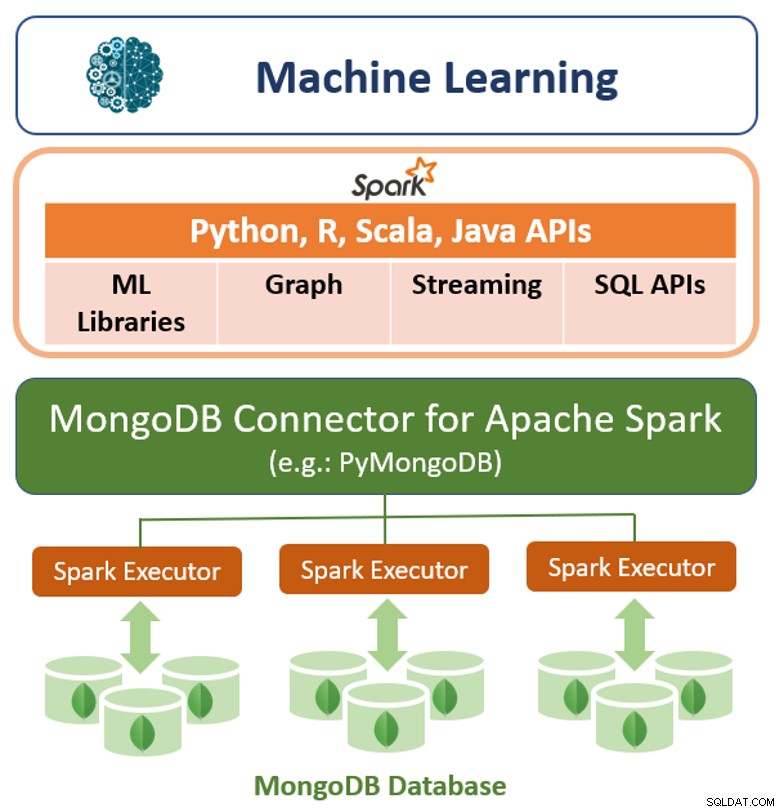
अपाचे स्पार्क के लिए MongoDB कनेक्टर MongoDB की एग्रीगेशन पाइपलाइन और सेकेंडरी का लाभ उठा सकता है केवल उस डेटा की श्रेणी को निकालने, फ़िल्टर करने और संसाधित करने के लिए अनुक्रमणिका - उदाहरण के लिए, एक विशिष्ट भूगोल में स्थित सभी ग्राहकों का विश्लेषण करना। यह साधारण NoSQL डेटास्टोर्स से बहुत अलग है जो या तो सेकेंडरी इंडेक्स या इन-डेटाबेस एग्रीगेशन का समर्थन नहीं करते हैं। इन मामलों में, स्पार्क को एक साधारण प्राथमिक कुंजी के आधार पर सभी डेटा निकालने की आवश्यकता होगी, भले ही स्पार्क प्रक्रिया के लिए उस डेटा का केवल एक सबसेट आवश्यक हो। इसका मतलब है कि डेटा वैज्ञानिकों और इंजीनियरों के लिए अधिक प्रोसेसिंग ओवरहेड, अधिक हार्डवेयर और लंबे समय तक अंतर्दृष्टि। बड़े, वितरित डेटा सेट में प्रदर्शन को अधिकतम करने के लिए, Apache Spark के लिए MongoDB कनेक्टर, स्रोत MongoDB नोड के साथ रेजिलिएंट डिस्ट्रिब्यूटेड डेटासेट (RDDs) का सह-पता लगा सकता है, जिससे क्लस्टर में डेटा की आवाजाही कम हो जाती है और विलंबता कम हो जाती है।
प्रदर्शन, मापनीयता और अतिरेक
एक परफॉर्मेंट और स्केलेबल डेटाबेस लेयर के ऊपर मशीन लर्निंग प्लेटफॉर्म बनाकर मॉडल प्रशिक्षण समय को कम किया जा सकता है। MongoDB मशीन लर्निंग वर्कलोड की थ्रूपुट को अधिकतम करने और विलंबता को कम करने के लिए कई नवाचार प्रदान करता है:
- WiredTiger को MongoDB के लिए डिफ़ॉल्ट स्टोरेज इंजन के रूप में जाना जाता है, जिसे बर्कले डीबी के आर्किटेक्ट द्वारा विकसित किया गया है, जो दुनिया में सबसे व्यापक रूप से तैनात एम्बेडेड डेटा प्रबंधन सॉफ्टवेयर है। WiredTiger आधुनिक, मल्टी-कोर आर्किटेक्चर पर स्केल करता है। विभिन्न प्रकार की प्रोग्रामिंग तकनीकों जैसे कि हैजर्ड पॉइंटर्स, लॉक-फ्री एल्गोरिदम, फास्ट लैचिंग और मैसेज पासिंग का उपयोग करते हुए, WiredTiger प्रति CPU कोर और घड़ी चक्र के कम्प्यूटेशनल कार्य को अधिकतम करता है। ऑन-डिस्क ओवरहेड और I/O को कम करने के लिए, WiredTiger कॉम्पैक्ट फ़ाइल स्वरूपों और संग्रहण संपीड़न का उपयोग करता है।
- सबसे विलंबता-संवेदनशील मशीन सीखने के अनुप्रयोगों के लिए, MongoDB को इन-मेमोरी स्टोरेज इंजन के साथ कॉन्फ़िगर किया जा सकता है। WiredTiger के आधार पर, यह स्टोरेज इंजन उपयोगकर्ताओं को इन-मेमोरी कंप्यूटिंग का लाभ देता है, बिना रिच क्वेरी फ्लेक्सिबिलिटी, रीयल-टाइम एनालिटिक्स और पारंपरिक डिस्क-आधारित डेटाबेस द्वारा पेश की जाने वाली स्केलेबल क्षमता का व्यापार किए बिना।
- मॉडल प्रशिक्षण को समानांतर करने के लिए और एक नोड से परे इनपुट डेटासेट को स्केल करने के लिए, MongoDB शार्डिंग नामक एक तकनीक का उपयोग करता है, जो कमोडिटी हार्डवेयर के क्लस्टर में प्रोसेसिंग और डेटा वितरित करता है। MongoDB शार्किंग पूरी तरह से लोचदार है, जैसे ही इनपुट डेटासेट बढ़ता है, या जैसे ही नोड्स जोड़े और निकाले जाते हैं, क्लस्टर में डेटा को स्वचालित रूप से पुनर्संतुलित करता है।
- एक MongoDB क्लस्टर के भीतर, प्रत्येक शार्क से डेटा स्वचालित रूप से अलग-अलग नोड्स पर होस्ट की गई कई प्रतिकृतियों को वितरित किया जाता है। MongoDB प्रतिकृति सेट विफलता की स्थिति में प्रशिक्षण डेटा को पुनर्प्राप्त करने के लिए अतिरेक प्रदान करते हैं, चेकपॉइंटिंग के ऊपरी हिस्से को कम करते हैं।
MongoDB की ट्यून करने योग्य संगति
MongoDB डिफ़ॉल्ट रूप से दृढ़ता से संगत है, मशीन सीखने के अनुप्रयोगों को डेटाबेस में लिखी गई चीज़ों को तुरंत पढ़ने में सक्षम बनाता है, इस प्रकार अंततः संगत सिस्टम द्वारा लगाए गए डेवलपर जटिलता से बचा जाता है। मजबूत स्थिरता मशीन लर्निंग एल्गोरिदम के लिए सबसे सटीक परिणाम प्रदान करेगी; हालांकि, कुछ परिदृश्यों में MongoDB माध्यमिक प्रतिकृति सेट सदस्यों के एक समूह में प्रश्नों को वितरित करके विशिष्ट प्रदर्शन लक्ष्यों के विरुद्ध एकरूपता का व्यापार करना स्वीकार्य है।
MongoDB में लचीला डेटा मॉडल
MongoDB का दस्तावेज़ डेटा मॉडल डेवलपर्स और डेटा वैज्ञानिकों के लिए डेटा गुणवत्ता को नियंत्रित करने के लिए परिष्कृत सत्यापन नियमों को छोड़े बिना, डेटाबेस के अंदर संरचना के किसी भी रूप के डेटा को संग्रहीत और एकत्र करना आसान बनाता है। स्कीमा को किसी एप्लिकेशन या डेटाबेस डाउनटाइम के बिना गतिशील रूप से संशोधित किया जा सकता है जो कि महंगे स्कीमा संशोधनों या रिलेशनल डेटाबेस सिस्टम द्वारा किए गए रीडिज़ाइन के परिणामस्वरूप होता है।
डेटाबेस में मॉडलों को सहेजना और उन्हें पायथन का उपयोग करके लोड करना भी एक आसान और बहुत आवश्यक तरीका है। MongoDB को चुनना भी एक फायदा है क्योंकि यह एक ओपन-सोर्स दस्तावेज़ डेटाबेस है और एक प्रमुख NoSQL डेटाबेस भी है। MongoDB अपाचे स्पार्क वितरित ढांचे के लिए एक कनेक्टर के रूप में भी कार्य करता है।
MongoDB की गतिशील प्रकृति
MongoDB की गतिशील प्रकृति मशीन लर्निंग अनुप्रयोगों के विकास में डेटाबेस हेरफेर कार्यों में इसके उपयोग को सक्षम बनाती है। यह डेटासेट और डेटाबेस का विश्लेषण करने का एक बहुत ही कुशल और आसान तरीका है। विश्लेषण के आउटपुट का उपयोग प्रशिक्षण मशीन लर्निंग मॉडल में किया जा सकता है। यह अनुशंसा की गई है कि डेटा विश्लेषक और मशीन लर्निंग प्रोग्रामर MongoDB में महारत हासिल करें और इसे कई अलग-अलग अनुप्रयोगों में लागू करें। कई अनुप्रयोगों के लिए डेटा विश्लेषण करने के लिए डेटा विज्ञान वर्कफ़्लो के लिए MongoDB के एकत्रीकरण ढांचे का उपयोग किया जाता है।
निष्कर्ष
MongoDB कई अलग-अलग क्षमताएं प्रदान करता है जैसे:लचीला डेटा मॉडल, समृद्ध प्रोग्रामिंग, डेटा मॉडल, क्वेरी मॉडल और इसकी ट्यून करने योग्य स्थिरता जो पारंपरिक, रिलेशनल डेटाबेस की तुलना में मशीन लर्निंग एल्गोरिदम को प्रशिक्षण और उपयोग करना बहुत आसान बनाती है। MongoDB को बैकएंड डेटाबेस के रूप में चलाने से मशीन लर्निंग डेटा को स्टोर करने और समृद्ध करने में मदद मिलेगी, जिससे दृढ़ता और दक्षता में वृद्धि होगी।



