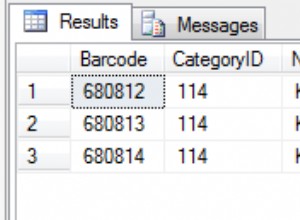
कुछ मान्यताओं (प्रश्न में अस्पष्टता) के आधार पर मेरा सुझाव है:
SELECT upper(trim(t.full_name)) AS teacher
, m.study_month
, r.room_code AS room
, count(s.room_id) AS study_count
FROM teachers t
CROSS JOIN generate_series(date_trunc('month', now() - interval '12 month') -- 12!
, date_trunc('month', now())
, interval '1 month') m(study_month)
CROSS JOIN rooms r
LEFT JOIN ( -- parentheses!
studies s
JOIN teacher_contacts tc ON tc.id = s.teacher_contact_id -- INNER JOIN!
) ON tc.teacher_id = t.id
AND s.study_dt >= m.study_month
AND s.study_dt < m.study_month + interval '1 month' -- sargable!
AND s.room_id = r.id
GROUP BY t.id, m.study_month, r.id -- id is PK of respective tables
ORDER BY t.id, m.study_month, r.id;
प्रमुख बिंदु
-
CROSS JOIN. के साथ सभी वांछित संयोजनों का ग्रिड बनाएं . और फिरLEFT JOINमौजूदा पंक्तियों के लिए। संबंधित: -
आपके मामले में, यह कई तालिकाओं का जोड़ है, इसलिए मैं
FROMमें कोष्ठक का उपयोग करता हूं सूची मेंLEFT JOINपरिणाम . तकINNER JOIN. का कोष्ठक के भीतर। यह गलत होगा करने के लिएLEFT JOINप्रत्येक तालिका के लिए अलग से, क्योंकि आप आंशिक मिलानों पर हिट शामिल करेंगे और संभावित रूप से गलत गणनाएं प्राप्त करेंगे। -
मान लें कि संदर्भात्मक अखंडता और सीधे पीके कॉलम के साथ काम करते हुए, हमें
rooms. को शामिल करने की आवश्यकता नहीं है औरteachersदूसरी बार बाईं ओर। लेकिन हमारे पास अभी भी दो तालिकाओं (studies. का एक संयोजन है औरteacher_contacts)teacher_contacts. की भूमिका मेरे लिए अस्पष्ट है। आम तौर पर, मैंstudies. के बीच संबंध की अपेक्षा करता हूं औरteachersसीधे। इसे और सरल बनाया जा सकता है... -
वांछित गणना प्राप्त करने के लिए हमें बाईं ओर एक गैर-शून्य कॉलम गिनने की आवश्यकता है। जैसे
count(s.room_id) -
बड़ी तालिकाओं के लिए इसे तेज़ रखने के लिए, सुनिश्चित करें कि आपके विधेय sargable हैं . और मिलते-जुलते इंडेक्स जोड़ें ।
-
कॉलम
teachersशायद ही (विश्वसनीय रूप से) अद्वितीय है। एक अद्वितीय आईडी के साथ काम करें, अधिमानतः पीके (तेज और सरल भी)। मैं अभी भीteachersका उपयोग कर रहा हूं आउटपुट के लिए आपके वांछित परिणाम से मेल खाने के लिए। एक अद्वितीय आईडी शामिल करना बुद्धिमानी हो सकती है, क्योंकि नाम डुप्लीकेट हो सकते हैं। -
आप चाहते हैं:
तो
date_trunc('month', now() - interval '12 month'. से शुरू करें (13 नहीं)। यह पहले से ही शुरुआत को गोल कर रहा है और वही करता है जो आप चाहते हैं - आपकी मूल क्वेरी की तुलना में अधिक सटीक।
चूंकि आपने वास्तविक तालिका परिभाषाओं और डेटा वितरण के आधार पर धीमे प्रदर्शन का उल्लेख किया है, इसलिए संभवत:पहले एकत्र करना और बाद में शामिल होना अधिक तेज़ है , जैसे इस संबंधित उत्तर में:
SELECT upper(trim(t.full_name)) AS teacher
, m.mon AS study_month
, r.room_code AS room
, COALESCE(s.ct, 0) AS study_count
FROM teachers t
CROSS JOIN generate_series(date_trunc('month', now() - interval '12 month') -- 12!
, date_trunc('month', now())
, interval '1 month') mon
CROSS JOIN rooms r
LEFT JOIN ( -- parentheses!
SELECT tc.teacher_id, date_trunc('month', s.study_dt) AS mon, s.room_id, count(*) AS ct
FROM studies s
JOIN teacher_contacts tc ON s.teacher_contact_id = tc.id
WHERE s.study_dt >= date_trunc('month', now() - interval '12 month') -- sargable
GROUP BY 1, 2, 3
) s ON s.teacher_id = t.id
AND s.mon = m.mon
AND s.room_id = r.id
ORDER BY 1, 2, 3;
आपकी समापन टिप्पणी के बारे में:
संभावना है कि आप कर सकते हैं crosstab() . के दो-पैरामीटर फ़ॉर्म का इस्तेमाल करें अपने वांछित परिणाम को सीधे और उत्कृष्ट प्रदर्शन के साथ उत्पन्न करने के लिए और उपरोक्त क्वेरी को शुरू करने की आवश्यकता नहीं है। विचार करें: