यह रिलेशनल-डिवीजन का मामला है - अतिरिक्त विशेष आवश्यकता के साथ कि एक ही बातचीत में कोई अतिरिक्त नहीं होगा उपयोगकर्ता।
मानते हैं तालिका का पीके है "conversationUsers" जो संयोजनों की विशिष्टता को लागू करता है, NOT NULL और परोक्ष रूप से प्रदर्शन के लिए आवश्यक सूचकांक भी प्रदान करता है। इस . में बहुस्तंभ PK के स्तंभ गण! नहीं तो आपको और अधिक करना होगा।
इंडेक्स कॉलम के क्रम के बारे में:
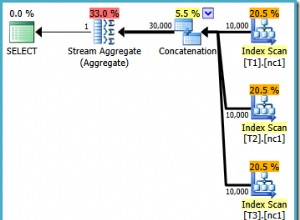
मूल प्रश्न के लिए, "जानवर बल" . है सभी . के लिए मेल खाने वाले उपयोगकर्ताओं की संख्या गिनने के लिए दृष्टिकोण सभी दिए गए उपयोगकर्ताओं की बातचीत और फिर सभी दिए गए उपयोगकर्ताओं से मेल खाने वाले को फ़िल्टर करें। छोटी तालिकाओं और/या केवल छोटी इनपुट सरणी और/या प्रति उपयोगकर्ता कुछ बातचीत के लिए ठीक है, लेकिन अच्छी तरह से स्केल नहीं करता :
SELECT "conversationId"
FROM "conversationUsers" c
WHERE "userId" = ANY ('{1,4,6}'::int[])
GROUP BY 1
HAVING count(*) = array_length('{1,4,6}'::int[], 1)
AND NOT EXISTS (
SELECT FROM "conversationUsers"
WHERE "conversationId" = c."conversationId"
AND "userId" <> ALL('{1,4,6}'::int[])
);
NOT EXISTS . के साथ अतिरिक्त उपयोगकर्ताओं के साथ बातचीत को समाप्त करना विरोधी अर्ध-जुड़ना। अधिक:
वैकल्पिक तकनीकें:
कई अन्य हैं, (बहुत) तेज़ रिलेशनल-डिवीजन क्वेरी तकनीक। लेकिन सबसे तेज़ वाले गतिशील . के लिए उपयुक्त नहीं हैं उपयोगकर्ता आईडी की संख्या।
तेज़ क्वेरी . के लिए जो उपयोगकर्ता आईडी की एक गतिशील संख्या से भी निपट सकता है, एक पर विचार करें। पुनरावर्ती सीटीई :
WITH RECURSIVE rcte AS (
SELECT "conversationId", 1 AS idx
FROM "conversationUsers"
WHERE "userId" = ('{1,4,6}'::int[])[1]
UNION ALL
SELECT c."conversationId", r.idx + 1
FROM rcte r
JOIN "conversationUsers" c USING ("conversationId")
WHERE c."userId" = ('{1,4,6}'::int[])[idx + 1]
)
SELECT "conversationId"
FROM rcte r
WHERE idx = array_length(('{1,4,6}'::int[]), 1)
AND NOT EXISTS (
SELECT FROM "conversationUsers"
WHERE "conversationId" = r."conversationId"
AND "userId" <> ALL('{1,4,6}'::int[])
);
उपयोग में आसानी के लिए इसे किसी फ़ंक्शन या तैयार स्टेटमेंट में लपेटें . पसंद:
PREPARE conversations(int[]) AS
WITH RECURSIVE rcte AS (
SELECT "conversationId", 1 AS idx
FROM "conversationUsers"
WHERE "userId" = $1[1]
UNION ALL
SELECT c."conversationId", r.idx + 1
FROM rcte r
JOIN "conversationUsers" c USING ("conversationId")
WHERE c."userId" = $1[idx + 1]
)
SELECT "conversationId"
FROM rcte r
WHERE idx = array_length($1, 1)
AND NOT EXISTS (
SELECT FROM "conversationUsers"
WHERE "conversationId" = r."conversationId"
AND "userId" <> ALL($1);
कॉल करें:
EXECUTE conversations('{1,4,6}');
db<>fiddle यहां (एक फ़ंक्शन भी दिखा रहा है )
अभी भी सुधार की गुंजाइश है:शीर्ष पाने के लिए प्रदर्शन आपको कम से कम बातचीत वाले उपयोगकर्ताओं को अपने इनपुट ऐरे में पहले रखना होगा ताकि जितनी जल्दी संभव हो उतनी पंक्तियों को समाप्त किया जा सके। शीर्ष प्रदर्शन प्राप्त करने के लिए आप गतिशील रूप से एक गैर-गतिशील, गैर-पुनरावर्ती क्वेरी उत्पन्न कर सकते हैं (तेज़ में से किसी एक का उपयोग करके) पहले लिंक से तकनीक) और बदले में उस पर अमल करें। आप इसे डायनेमिक SQL के साथ एकल plpgsql फ़ंक्शन में भी लपेट सकते हैं ...
अधिक स्पष्टीकरण:
वैकल्पिक:कम लिखी गई तालिका के लिए एमवी
यदि तालिका "conversationUsers" अधिकतर केवल पढ़ने के लिए है (पुरानी बातचीत के बदलने की संभावना नहीं है) आप का उपयोग कर सकते हैं। MATERIALIZED VIEW
पूर्व-एकत्रित उपयोगकर्ताओं के साथ क्रमबद्ध सरणियों में और उस सरणी स्तंभ पर एक सादा btree अनुक्रमणिका बनाएँ।
CREATE MATERIALIZED VIEW mv_conversation_users AS
SELECT "conversationId", array_agg("userId") AS users -- sorted array
FROM (
SELECT "conversationId", "userId"
FROM "conversationUsers"
ORDER BY 1, 2
) sub
GROUP BY 1
ORDER BY 1;
CREATE INDEX ON mv_conversation_users (users) INCLUDE ("conversationId");
प्रदर्शित कवरिंग इंडेक्स के लिए Postgres 11 की आवश्यकता होती है। देखें:
सबक्वेरी में पंक्तियों को छाँटने के बारे में:
पुराने संस्करणों में (users, "conversationId") पर एक सादे बहु-स्तंभ अनुक्रमणिका का उपयोग करें . बहुत लंबी सरणियों के साथ, हैश इंडेक्स 10 या बाद के पोस्टग्रेज में सार्थक हो सकता है।
तब अधिक तेज़ क्वेरी बस होगी:
SELECT "conversationId"
FROM mv_conversation_users c
WHERE users = '{1,4,6}'::int[]; -- sorted array!
db<>fiddle यहां
प्रदर्शन पढ़ने के लाभों के विरुद्ध आपको भंडारण, लेखन और रखरखाव में अतिरिक्त लागतों को तौलना होगा।
इसके अलावा:दोहरे उद्धरण चिह्नों के बिना कानूनी पहचानकर्ताओं पर विचार करें। conversation_id "conversationId" . के बजाय आदि: