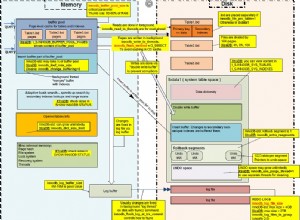
इस क्वेरी ने कोई डिस्क I/O उत्पन्न नहीं की - सभी ब्लॉक साझा बफर से पढ़े जाते हैं। लेकिन चूंकि क्वेरी 73424 ब्लॉक (लगभग 574 एमबी) पढ़ती है, यह तालिका के कैश नहीं होने पर पर्याप्त I/O लोड उत्पन्न करेगी।
लेकिन दो चीजें हैं जिन्हें सुधारा जा सकता है।
-
आपके पास हानिकारक ब्लॉक मिलान . हैं ढेर स्कैन में। इसका मतलब है कि
work_memबिटमैप को प्रति तालिका पंक्ति के साथ रखने के लिए पर्याप्त बड़ा नहीं है, और इसके बजाय 26592 बिट्स तालिका ब्लॉक को मैप करते हैं। सभी पंक्तियों को फिर से जांचना पड़ता है, और 86733 पंक्तियों को छोड़ दिया जाता है, जिनमें से अधिकांश हानिपूर्ण ब्लॉक मैचों से झूठी सकारात्मक होती हैं।अगर आप
work_memincrease बढ़ाते हैं , बिट प्रति तालिका पंक्ति वाला बिटमैप मेमोरी में फ़िट हो जाएगा, और यह संख्या सिकुड़ जाएगी, जिससे हीप स्कैन के दौरान काम कम हो जाएगा। -
190108 पंक्तियों को छोड़ दिया जाता है क्योंकि वे बिटमैप हीप स्कैन में अतिरिक्त फ़िल्टर स्थिति से मेल नहीं खाती हैं। शायद यही वह जगह है जहां ज्यादातर समय बिताया जाता है। यदि आप उस राशि को कम कर सकते हैं, तो आप जीतेंगे।
इस क्वेरी के लिए आदर्श इंडेक्स होंगे:
CREATE INDEX ON map_listing(transaction_type, la); CREATE INDEX ON map_listing(transaction_type, lo);अगर
transaction_typeबहुत चयनात्मक नहीं है (अर्थात, अधिकांश पंक्तियों का मानSale. है ), आप उस कॉलम को छोड़ सकते हैं।
संपादित करें:
vmstat . की परीक्षा और iostat दिखाता है कि सीपीयू और आई/ओ सबसिस्टम दोनों बड़े पैमाने पर अधिभार से पीड़ित हैं:सभी सीपीयू संसाधन I/O प्रतीक्षा और वीएम चोरी के समय पर खर्च किए जाते हैं। आपको एक बेहतर I/O सिस्टम और अधिक मुक्त CPU संसाधनों के साथ एक होस्ट सिस्टम की आवश्यकता है। रैम माइगजेट बढ़ाने से I/O समस्या कम हो जाती है, लेकिन केवल डिस्क रीड करने के लिए।