सूचकांक
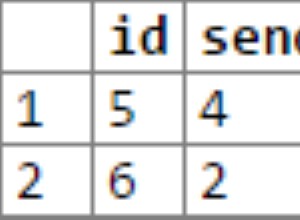
x.id . पर इंडेक्स बनाएं और y.id - जो शायद आपके पास पहले से ही है यदि वे आपकी प्राथमिक कुंजी हैं।
एक बहु-स्तंभ अनुक्रमणिका भी मदद कर सकती है, विशेष रूप से केवल अनुक्रमणिका स्कैन करता है
पृष्ठ 9.2+ में:
CREATE INDEX y_mult_idx ON y (id DESC, val)
हालाँकि, मेरे परीक्षणों में, पहले इस सूचकांक का उपयोग नहीं किया गया था। जोड़ना पड़ा (अन्यथा व्यर्थ) val करने के लिए ORDER BY क्वेरी प्लानर को यह समझाने के लिए कि सॉर्ट ऑर्डर मेल खाता है। क्वेरी देखें 3 ।
इस सिंथेटिक सेटअप में इंडेक्स का बहुत कम फर्क पड़ता है। लेकिन अधिक कॉलम वाली तालिकाओं के लिए, val . को पुनः प्राप्त करना तालिका से अधिक महंगा हो जाता है, जिससे "कवरिंग" इंडेक्स अधिक आकर्षक हो जाता है।
प्रश्न
1) सरल
SELECT DISTINCT ON (x.id)
x.id, y.val
FROM x
JOIN y ON y.id <= x.id
ORDER BY x.id, y.id DESC;
DISTINCT . के साथ तकनीक के लिए अधिक स्पष्टीकरण इस संबंधित उत्तर में:
मैंने कुछ परीक्षण चलाए क्योंकि मुझे संदेह था कि पहली क्वेरी अच्छी तरह से स्केल नहीं होगी। यह एक छोटी सी टेबल के साथ तेज़ है, लेकिन बड़ी टेबल के साथ अच्छा नहीं है। Postgres योजना को अनुकूलित नहीं करता है और O(N²) की लागत के साथ (सीमित) क्रॉस जॉइन के साथ शुरू होता है ।
2) तेज़
यह क्वेरी अभी भी काफी सरल है और उत्कृष्ट रूप से मापी जाती है:
SELECT x.id, y.val
FROM x
JOIN (SELECT *, lead(id, 1, 2147483647) OVER (ORDER BY id) AS next_id FROM y) y
ON x.id >= y.id
AND x.id < y.next_id
ORDER BY 1;
विंडो फ़ंक्शन lead()
वाद्य है। मैं अंतिम पंक्ति के कोने के मामले को कवर करने के लिए एक डिफ़ॉल्ट प्रदान करने के विकल्प का उपयोग करता हूं:2147483647 सबसे बड़ा संभावित पूर्णांक
है . अपने डेटा प्रकार के अनुकूल बनें।
3) बहुत ही सरल और लगभग तेज़
SELECT x.id
,(SELECT val FROM y WHERE id <= x.id ORDER BY id DESC, val LIMIT 1) AS val
FROM x;आम तौर पर, सहसंबंधित सबक्वेरी धीमे होते हैं। लेकिन यह केवल (कवर) सूचकांक से एक मूल्य चुन सकता है और अन्यथा इतना आसान है कि यह प्रतिस्पर्धा कर सकता है।
अतिरिक्त ORDER BY आइटम val (बोल्ड जोर) व्यर्थ लगता है। लेकिन इसे जोड़ने से क्वेरी प्लानर को यकीन हो जाता है कि मल्टी-कॉलम इंडेक्स y_mult_idx का इस्तेमाल करना ठीक है ऊपर से, क्योंकि सॉर्ट ऑर्डर मेल खाता है। नोट करें
EXPLAIN . में आउटपुट।
टेस्ट केस
एक जीवंत बहस और कई अपडेट के बाद मैंने अब तक पोस्ट किए गए सभी प्रश्नों को एकत्र किया और त्वरित अवलोकन के लिए एक परीक्षण केस बनाया। मैं केवल 1000 पंक्तियों का उपयोग करता हूं, इसलिए SQLfiddle धीमे प्रश्नों के साथ समय समाप्त नहीं करता है। लेकिन शीर्ष 4 (इरविन 2, क्लोडोआल्डो, ए_हॉर्स, इरविन 3) मेरे सभी स्थानीय परीक्षणों में रैखिक रूप से स्केल करते हैं। मेरे नवीनतम अतिरिक्त को शामिल करने के लिए एक बार फिर अपडेट किया गया, अब प्रदर्शन द्वारा प्रारूप और क्रम में सुधार करें:
बिग SQL Fiddle प्रदर्शन की तुलना करना।