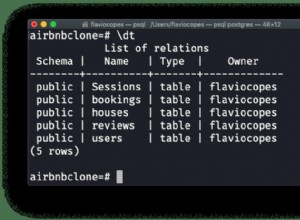
समस्या यह है कि आप encode . को कॉल कर रहे हैं एक str . पर वस्तु।
एक str एक बाइट स्ट्रिंग है, जो आमतौर पर यूटीएफ -8 जैसे किसी तरह से एन्कोड किए गए टेक्स्ट का प्रतिनिधित्व करती है। जब आप encode call को कॉल करते हैं उस पर, इसे पहले टेक्स्ट में वापस डीकोड करना होगा, ताकि टेक्स्ट को फिर से एन्कोड किया जा सके। डिफ़ॉल्ट रूप से, Python s.decode(sys.getgetdefaultencoding()) को कॉल करके ऐसा करता है। , और getdefaultencoding() आमतौर पर 'ascii' . लौटाता है ।
तो, आप यूटीएफ -8 एन्कोडेड टेक्स्ट की बात कर रहे हैं, इसे डीकोड कर रहे हैं जैसे कि यह एएससीआईआई था, फिर इसे यूटीएफ -8 में फिर से एन्कोडिंग करें।
सामान्य समाधान स्पष्ट रूप से decode . को कॉल करना है सही एन्कोडिंग के साथ, पायथन को डिफ़ॉल्ट का उपयोग करने देने के बजाय, और फिर encode परिणाम।
लेकिन जब सही एन्कोडिंग पहले से ही आप चाहते हैं, तो आसान समाधान केवल .decode('utf-8').encode('utf-8') को छोड़ देना है। और बस UTF-8 str . का उपयोग करें UTF-8 के रूप में str कि यह पहले से ही है।
या, वैकल्पिक रूप से, यदि आपके MySQL आवरण में आपको एक एन्कोडिंग निर्दिष्ट करने और unicode वापस पाने की सुविधा है CHAR . के लिए मान /VARCHAR /TEXT str . के बजाय कॉलम मान (जैसे, MySQLdb में, आप use_unicode=True . पास करते हैं connect . के लिए कॉल करें, या charset='UTF-8' यदि आपका डेटाबेस ऑटो-डिटेक्ट करने के लिए बहुत पुराना है), तो बस ऐसा करें। फिर आपके पास unicode होगा ऑब्जेक्ट्स, और आप .encode('utf-8') . पर कॉल कर सकते हैं उन पर।
सामान्य तौर पर, यूनिकोड की समस्याओं से निपटने का सबसे अच्छा तरीका आखिरी तरीका है—जितनी जल्दी हो सके सब कुछ डीकोड करना, यूनिकोड में सभी प्रसंस्करण करना, और फिर जितनी देर हो सके एन्कोड करना। लेकिन किसी भी तरह से, आपको लगातार बने रहना होगा। str पर कॉल न करें किसी ऐसी चीज़ पर जो एक unicode हो सकता है; एक str को संयोजित न करें एक unicode . के लिए शाब्दिक या एक को उसके replace . में पास करें तरीका; आदि। जब भी आप मिक्स एंड मैच करते हैं, तो पाइथन आपके डिफ़ॉल्ट एन्कोडिंग का उपयोग करके आपके लिए परोक्ष रूप से रूपांतरित होने जा रहा है, जो कि आप जो चाहते हैं वह लगभग कभी नहीं है।
एक साइड नोट के रूप में, यह कई चीजों में से एक है जिसमें पायथन 3.x का यूनिकोड परिवर्तन मदद करता है। सबसे पहले, str अब यूनिकोड टेक्स्ट है, एन्कोडेड बाइट्स नहीं। इससे भी महत्वपूर्ण बात यह है कि यदि आपके पास है एन्कोडेड बाइट्स, उदाहरण के लिए, bytes . में ऑब्जेक्ट, कॉल करना encode आपको एक AttributeError देगा चुपचाप डीकोड करने की कोशिश करने के बजाय यह फिर से एन्कोड कर सकता है। और, इसी तरह, यूनिकोड और बाइट्स को मिलाने और मिलाने की कोशिश करने से आपको एक स्पष्ट TypeError मिलेगा , एक निहित रूपांतरण के बजाय जो कुछ मामलों में सफल होता है और एक एन्कोड या डिकोड के बारे में एक गुप्त संदेश देता है जिसे आपने दूसरों में नहीं पूछा था।