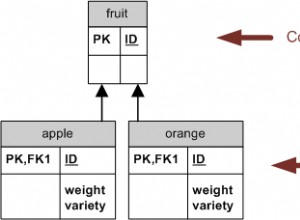
मुझे लगता है कि आपको elements . का उपयोग करना चाहिए टेबल:
-
पोस्टग्रेज़ आँकड़ों का उपयोग करके यह अनुमान लगाने में सक्षम होंगे कि क्वेरी निष्पादित करने से पहले कितनी पंक्तियों का मिलान होगा, इसलिए यह सर्वोत्तम क्वेरी योजना का उपयोग करने में सक्षम होगा (यदि आपका डेटा समान रूप से वितरित नहीं है तो यह अधिक महत्वपूर्ण है);
-
आप
CLUSTER elements USING elements_id_element_idxका उपयोग करके क्वेरी डेटा को स्थानीयकृत करने में सक्षम होंगे; -
जब Postgres 9.2 जारी किया जाएगा तब आप केवल अनुक्रमणिका स्कैन का लाभ उठा सकेंगे;
लेकिन मैंने 10M तत्वों के लिए कुछ परीक्षण किए हैं:
create table elements (id_item bigint, id_element bigint);
insert into elements
select (random()*524288)::int, (random()*32768)::int
from generate_series(1,10000000);
\timing
create index elements_id_item on elements(id_item);
Time: 15470,685 ms
create index elements_id_element on elements(id_element);
Time: 15121,090 ms
select relation, pg_size_pretty(pg_relation_size(relation))
from (
select unnest(array['elements','elements_id_item', 'elements_id_element'])
as relation
) as _;
relation | pg_size_pretty
---------------------+----------------
elements | 422 MB
elements_id_item | 214 MB
elements_id_element | 214 MB
create table arrays (id_item bigint, a_elements bigint[]);
insert into arrays select array_agg(id_element) from elements group by id_item;
create index arrays_a_elements_idx on arrays using gin (a_elements);
Time: 22102,700 ms
select relation, pg_size_pretty(pg_relation_size(relation))
from (
select unnest(array['arrays','arrays_a_elements_idx']) as relation
) as _;
relation | pg_size_pretty
-----------------------+----------------
arrays | 108 MB
arrays_a_elements_idx | 73 MB
तो दूसरी ओर सरणियाँ छोटी होती हैं, और छोटी अनुक्रमणिका होती हैं। निर्णय लेने से पहले मैं कुछ 200M तत्वों का परीक्षण करूँगा।