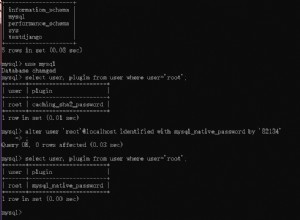
आपको यह पता लगाना होगा कि WHERE इस क्वेरी के साथ आप जिन क्लॉज़ का उपयोग करने जा रहे हैं, उनमें से प्रत्येक कितनी बार होगा और प्रत्येक शर्त कितनी चयनात्मक होगी।
-
उन प्रश्नों के लिए अनुक्रमित न करें जो शायद ही कभी होते हैं जब तक कि आपको ऐसा न करना पड़े।
-
एक
=. में आने वाले कॉलम से शुरू होने वाले मल्टीकॉलम इंडेक्स का इस्तेमाल करें तुलना। -
एक बहु-स्तंभ अनुक्रमणिका में स्तंभों के क्रम के संबंध में, उन स्तंभों से प्रारंभ करें जिनका उपयोग स्वयं एक क्वेरी में किया जाएगा (एक अनुक्रमणिका का उपयोग केवल कुछ स्तंभों वाली क्वेरी के लिए किया जा सकता है, बशर्ते वे अनुक्रमणिका की शुरुआत में हों)।
-
आप कम चयनात्मकता वाले कॉलम छोड़ सकते हैं, जैसे
gender।
उदाहरण के लिए, आपके उपरोक्त प्रश्नों के साथ, यदि वे सभी लगातार हैं और सभी कॉलम चयनात्मक हैं, तो ये अनुक्रमणिकाएँ अच्छी होंगी:
... ON apartments (city_id, rooms, size)
... ON apartments (area_id, ad_type, price)
... ON apartments (area_id, ad_type, published_at)
इन इंडेक्स का उपयोग WHERE . के लिए भी किया जा सकता है केवल area_id with के साथ क्लॉज या city_id उनमें।
बहुत अधिक अनुक्रमणिका होना बुरा है।
यदि उपरोक्त विधि बहुत अधिक अनुक्रमित करती है, उदा। क्योंकि उपयोगकर्ता WHERE . के लिए मनमाना कॉलम चुन सकता है खंड, अलग-अलग स्तंभों या कभी-कभी स्तंभों के जोड़े जो नियमित रूप से एक साथ चलते हैं, को अनुक्रमित करना बेहतर होता है।
इस तरह PostgreSQL एक बिटमैप इंडेक्स स्कैन . चुन सकता है एक क्वेरी के लिए कई इंडेक्स को संयोजित करने के लिए। यह नियमित इंडेक्स स्कैन . से कम कुशल है , लेकिन आमतौर पर अनुक्रमिक स्कैन . से बेहतर होता है ।