टेबल और इंडेक्स में हटाए गए टुपल्स को पुनः प्राप्त करने के लिए वैक्यूम सबसे महत्वपूर्ण विशेषताओं में से एक है। वैक्यूम के बिना, टेबल और इंडेक्स बिना सीमा के आकार में बढ़ते रहेंगे। यह ब्लॉग पोस्ट VACUUM कमांड के लिए PARALLEL विकल्प का वर्णन करता है, जिसे PostgreSQL13 में हाल ही में पेश किया गया है।
वैक्यूम प्रोसेसिंग चरण
नए विकल्प पर गहराई से चर्चा करने से पहले आइए इस विवरण की समीक्षा करें कि वैक्यूम कैसे काम करता है।
निर्वात (पूर्ण विकल्प के बिना) में पाँच चरण होते हैं। उदाहरण के लिए, दो इंडेक्स वाली टेबल के लिए, यह इस तरह काम करता है:
- हीप स्कैन चरण
- तालिका को ऊपर से स्कैन करें और मेमोरी में कचरा टुपल्स इकट्ठा करें।
- सूचकांक निर्वात चरण
- एक-एक करके दोनों इंडेक्स को वैक्यूम करें।
- हीप वैक्यूम चरण
- ढेर को खाली करें (तालिका)।
- सूचकांक सफाई चरण
- एक-एक करके दोनों इंडेक्स को साफ करें।
- ढेर काटने का चरण
- तालिका के अंत में खाली पृष्ठों को छोटा करें।
हीप स्कैन चरण में, वैक्यूम दृश्यता मानचित्र का उपयोग उन पृष्ठों के प्रसंस्करण को छोड़ने के लिए कर सकता है, जिन्हें कोई कचरा नहीं होने के रूप में जाना जाता है, जबकि इंडेक्स वैक्यूम चरण और इंडेक्स क्लीनअप चरण दोनों में, इंडेक्स एक्सेस विधियों के आधार पर, एक संपूर्ण इंडेक्स स्कैनिंग आवश्यक है।
उदाहरण के लिए, सबसे लोकप्रिय इंडेक्स प्रकार, btree इंडेक्स को कचरा टुपल्स को हटाने और इंडेक्स क्लीनअप करने के लिए पूरे इंडेक्स स्कैन की आवश्यकता होती है। चूंकि वैक्यूम हमेशा एक ही प्रक्रिया द्वारा किया जाता है, इसलिए इंडेक्स को एक-एक करके संसाधित किया जाता है। विशेष रूप से एक बड़ी मेज पर वैक्यूम का लंबा निष्पादन समय अक्सर उपयोगकर्ताओं को परेशान करता है।
समानांतर विकल्प
इस समस्या को हल करने के लिए, मैंने 2016 में वैक्यूम को समानांतर करने के लिए एक पैच का प्रस्ताव रखा। एक लंबी समीक्षा प्रक्रिया और कई सुधारों के बाद, PARALLEL विकल्प को PostgreSQL 13 में पेश किया गया है। इस विकल्प के साथ, वैक्यूम इंडेक्स वैक्यूम चरण और इंडेक्स क्लीनअप चरण के साथ प्रदर्शन कर सकता है। समानांतर कार्यकर्ता। समानांतर वैक्यूम कार्यकर्ता या तो इंडेक्स वैक्यूम चरण या इंडेक्स क्लीनअप चरण में प्रवेश करने से पहले लॉन्च करते हैं और चरण के अंत में बाहर निकलते हैं। एक व्यक्तिगत कार्यकर्ता को एक सूचकांक को सौंपा गया है। समानांतर वैक्यूम हमेशा ऑटोवैक्यूम में अक्षम होता है।
पूर्णांक तर्क विकल्प के बिना PARALLEL विकल्प स्वचालित रूप से तालिका पर अनुक्रमणिका की संख्या के आधार पर समानांतर डिग्री की गणना करेगा।
VACUUM (PARALLEL) tbl;
चूंकि लीडर प्रक्रिया हमेशा एक इंडेक्स को प्रोसेस करती है, समानांतर वर्कर्स की अधिकतम संख्या (तालिका -1 में इंडेक्स की संख्या) होगी, जो आगे max_parallel_maintenance_workers तक सीमित है। लक्ष्य सूचकांक min_parallel_index_scan_size से बड़ा या उसके बराबर होना चाहिए।
PARALLEL विकल्प हमें गैर-शून्य पूर्णांक मान पास करके समानांतर डिग्री निर्दिष्ट करने की अनुमति देता है। निम्नलिखित उदाहरण समानांतर में कुल चार प्रक्रियाओं के लिए तीन श्रमिकों का उपयोग करता है।
VACUUM (PARALLEL 3) tbl;
PARALLEL विकल्प डिफ़ॉल्ट रूप से सक्षम है; समानांतर वैक्यूम को अक्षम करने के लिए, max_parallel_maintenance_workers को 0 पर सेट करें, या PARALLEL 0 निर्दिष्ट करें ।
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
VACUUM VERBOSE आउटपुट को देखते हुए, हम देख सकते हैं कि एक वर्कर इंडेक्स को प्रोसेस कर रहा है।
कार्यकर्ता द्वारा "समानांतर कार्यकर्ता द्वारा" के रूप में मुद्रित जानकारी की सूचना दी जाती है।
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
इंडेक्स एक्सेस मेथड्स बनाम समानता की डिग्री
वैक्यूम हमेशा इंडेक्स वैक्यूम फेज और इंडेक्स क्लीनअप फेज को समानांतर में जरूरी नहीं करता है। यदि सूचकांक का आकार छोटा है, या यदि यह ज्ञात है कि प्रक्रिया को जल्दी से पूरा किया जा सकता है, तो समानांतर के लिए समानांतर श्रमिकों को लॉन्च करने और प्रबंधित करने की लागत इसके बजाय ओवरहेड का कारण बनती है। इंडेक्स एक्सेस विधियों और उसके आकार के आधार पर, इन चरणों को समानांतर वैक्यूम वर्कर प्रक्रिया द्वारा निष्पादित नहीं करना बेहतर है।
उदाहरण के लिए, एक बड़े पर्याप्त बीट्री इंडेक्स को वैक्यूम करने में, इंडेक्स के इंडेक्स वैक्यूम चरण को समानांतर वैक्यूम वर्कर द्वारा किया जा सकता है क्योंकि इसके लिए हमेशा पूरे इंडेक्स स्कैन की आवश्यकता होती है, जबकि इंडेक्स क्लीनअप चरण समानांतर वैक्यूम वर्कर द्वारा किया जाता है यदि इंडेक्स वैक्यूम नहीं किया जाता है (उदाहरण के लिए, टेबल पर कोई कचरा नहीं है)। ऐसा इसलिए है क्योंकि इंडेक्स क्लीनअप चरण में बीट्री इंडेक्स को इंडेक्स आंकड़े एकत्र करने की आवश्यकता होती है, जिसे इंडेक्स वैक्यूम चरण के दौरान भी एकत्र किया जाता है। दूसरी ओर, हैश इंडेक्स को हमेशा इंडेक्स क्लीनअप चरण पर इंडेक्स पर स्कैन की आवश्यकता नहीं होती है।
विभिन्न प्रकार की इंडेक्स वैक्यूम रणनीतियों का समर्थन करने के लिए, इंडेक्स एक्सेस विधियों के डेवलपर्स amparallelvacuumoptions पर फ़्लैग सेट करके इन व्यवहारों को निर्दिष्ट कर सकते हैं। IndexAmRoutine . का क्षेत्र संरचना। उपलब्ध झंडे इस प्रकार हैं:
- VACUUM_OPTION_NO_PARALLEL (डिफ़ॉल्ट)
- समानांतर वैक्यूम दोनों चरणों में अक्षम है।
- VACUUM_OPTION_PARALLEL_BULKDEL
- सूचकांक निर्वात चरण समानांतर में किया जा सकता है।
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- इंडेक्स क्लीनअप चरण समानांतर में किया जा सकता है यदि इंडेक्स वैक्यूम चरण अभी तक निष्पादित नहीं किया गया है।
- VACUUM_OPTION_PARALLEL_CLEANUP
- इंडेक्स क्लीनअप चरण समानांतर में किया जा सकता है, भले ही इंडेक्स वैक्यूम चरण पहले ही इंडेक्स को प्रोसेस कर चुका हो।
नीचे दी गई तालिका दिखाती है कि कैसे इंडेक्स एएम बिल्ट-इन पोस्टग्रेएसक्यूएल समानांतर वैक्यूम का समर्थन करता है।
| nbtree | हैश | gin | जिस्ट | spgist | brin | ब्लूम | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
अधिक विवरण के लिए 'src/include/command/vacuum.h' देखें।
प्रदर्शन सत्यापन
मैंने अपने लैपटॉप (कोर i7 2.6GHz, 16GB RAM, 512GB SSD) पर समानांतर वैक्यूम के प्रदर्शन का मूल्यांकन किया है। तालिका का आकार 6GB है और इसमें आठ 3GB अनुक्रमित हैं। कुल संबंध 30GB है, जो मशीन RAM में फिट नहीं होता है। प्रत्येक मूल्यांकन के लिए, मैंने वैक्यूमिंग के बाद टेबल के कई प्रतिशत समान रूप से गंदा कर दिया, फिर समानांतर डिग्री बदलते हुए वैक्यूम का प्रदर्शन किया। नीचे दिया गया ग्राफ़ वैक्यूम निष्पादन समय दिखाता है।
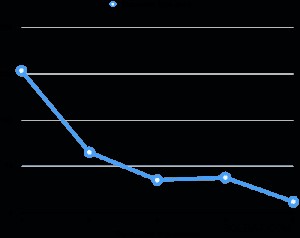
सभी मूल्यांकनों में सूचकांक निर्वात का निष्पादन समय कुल निष्पादन समय के 95% से अधिक के लिए जिम्मेदार है। इसलिए, इंडेक्स वैक्यूम चरण के समानांतरीकरण ने वैक्यूम निष्पादन समय को बहुत कम करने में मदद की।
धन्यवाद
पोस्टग्रेएसक्यूएल 13 को समर्पित समीक्षा, सलाह प्रदान करने और इस सुविधा को करने के लिए अमित कपिला का विशेष धन्यवाद। मैं उन सभी डेवलपर्स की सराहना करता हूं जो समीक्षा, परीक्षण और चर्चा के लिए इस सुविधा में शामिल थे।



