सूचना प्रौद्योगिकी की दुनिया में, हम में से अधिकांश के लिए स्वचालन कोई नई बात नहीं है। वास्तव में, अधिकांश संगठन अपने कार्य प्रकार और उद्देश्यों के आधार पर विभिन्न उद्देश्यों के लिए इसका उपयोग कर रहे हैं। उदाहरण के लिए, डेटा विश्लेषक रिपोर्ट जेनरेट करने के लिए ऑटोमेशन का उपयोग करते हैं, सिस्टम एडमिनिस्ट्रेटर डिस्क स्थान की सफाई जैसे अपने दोहराए जाने वाले कार्यों के लिए ऑटोमेशन का उपयोग करते हैं, और डेवलपर्स अपनी विकास प्रक्रिया को स्वचालित करने के लिए ऑटोमेशन का उपयोग करते हैं।
आजकल, IT के लिए बहुत सारे स्वचालन उपकरण उपलब्ध हैं और इन्हें चुना जा सकता है, DevOps युग के लिए धन्यवाद। सबसे अच्छा साधन कौन सा है? उत्तर एक पूर्वानुमेय है 'यह निर्भर करता है', क्योंकि यह इस बात पर निर्भर करता है कि हम क्या हासिल करने की कोशिश कर रहे हैं और साथ ही साथ हमारे पर्यावरण की स्थापना भी। कुछ स्वचालन उपकरण टेराफॉर्म, बोल्ट, शेफ, साल्टस्टैक हैं और एक बहुत ही ट्रेंडी है Ansible। Ansible एक ओपन-सोर्स एजेंट रहित IT इंजन है जो एप्लिकेशन परिनियोजन, कॉन्फ़िगरेशन प्रबंधन और IT ऑर्केस्ट्रेशन को स्वचालित कर सकता है। Ansible की स्थापना 2012 में हुई थी और इसे सबसे लोकप्रिय भाषा, Python में लिखा गया है। यह सभी स्वचालन को लागू करने के लिए एक प्लेबुक का उपयोग करता है, जहां सभी कॉन्फ़िगरेशन मानव-पठनीय भाषा, YAML में लिखे गए हैं।
आज की पोस्ट में, हम सीखेंगे कि Postgresql डेटाबेस परिनियोजन करने के लिए Ansible का उपयोग कैसे करें।
क्या Ansible को खास बनाता है?
जिस कारण से ansible का उपयोग मुख्य रूप से उसकी विशेषताओं के कारण किया जाता है। वे विशेषताएं हैं:
-
साधारण मानव-पठनीय भाषा YAML का उपयोग करके कुछ भी स्वचालित किया जा सकता है
-
रिमोट मशीन (एजेंट रहित आर्किटेक्चर) पर कोई एजेंट इंस्टॉल नहीं किया जाएगा
-
कॉन्फ़िगरेशन आपकी स्थानीय मशीन से आपकी स्थानीय मशीन (पुश मॉडल) से सर्वर पर पुश किया जाएगा
पी> -
पायथन (वर्तमान में उपयोग की जाने वाली लोकप्रिय भाषाओं में से एक) का उपयोग करके विकसित किया गया है और बहुत से पुस्तकालयों को चुना जा सकता है
-
रेड हैड इंजीनियरिंग टीम द्वारा सावधानीपूर्वक चुने गए उत्तरदायी मॉड्यूल का संग्रह
अंसिबल वर्क्स का तरीका
इससे पहले कि Ansible दूरस्थ होस्ट को कोई भी परिचालन कार्य चला सके, हमें इसे एक होस्ट में स्थापित करने की आवश्यकता है जो नियंत्रक नोड बन जाएगा। इस नियंत्रक नोड में, हम किसी भी कार्य को व्यवस्थित करेंगे जिसे हम दूरस्थ होस्ट में करना चाहते हैं जिसे प्रबंधित नोड्स के रूप में भी जाना जाता है।
नियंत्रक नोड के पास प्रबंधित नोड्स की सूची और इसे प्रबंधित करने के लिए Ansible सॉफ़्टवेयर होना चाहिए। Ansible द्वारा उपयोग किए जाने वाले आवश्यक डेटा जैसे प्रबंधित नोड का होस्टनाम या IP पता इस इन्वेंट्री के अंदर रखा जाएगा। उचित सूची के बिना, Ansible स्वचालन को सही ढंग से नहीं कर सका। इन्वेंट्री के बारे में और जानने के लिए यहां देखें।
Ansible एजेंट रहित है और परिवर्तनों को आगे बढ़ाने के लिए SSH का उपयोग कर रहा है, जिसका अर्थ है कि हमें सभी नोड्स में Ansible को स्थापित करने की आवश्यकता नहीं है, लेकिन सभी प्रबंधित नोड्स में अजगर और कोई भी आवश्यक पायथन लाइब्रेरी स्थापित होनी चाहिए। नियंत्रक नोड और प्रबंधित नोड दोनों को पासवर्ड रहित के रूप में सेट किया जाना चाहिए। यह उल्लेखनीय है कि सभी नियंत्रक नोड और प्रबंधित नोड्स के बीच कनेक्शन अच्छा है और ठीक से परीक्षण किया गया है।
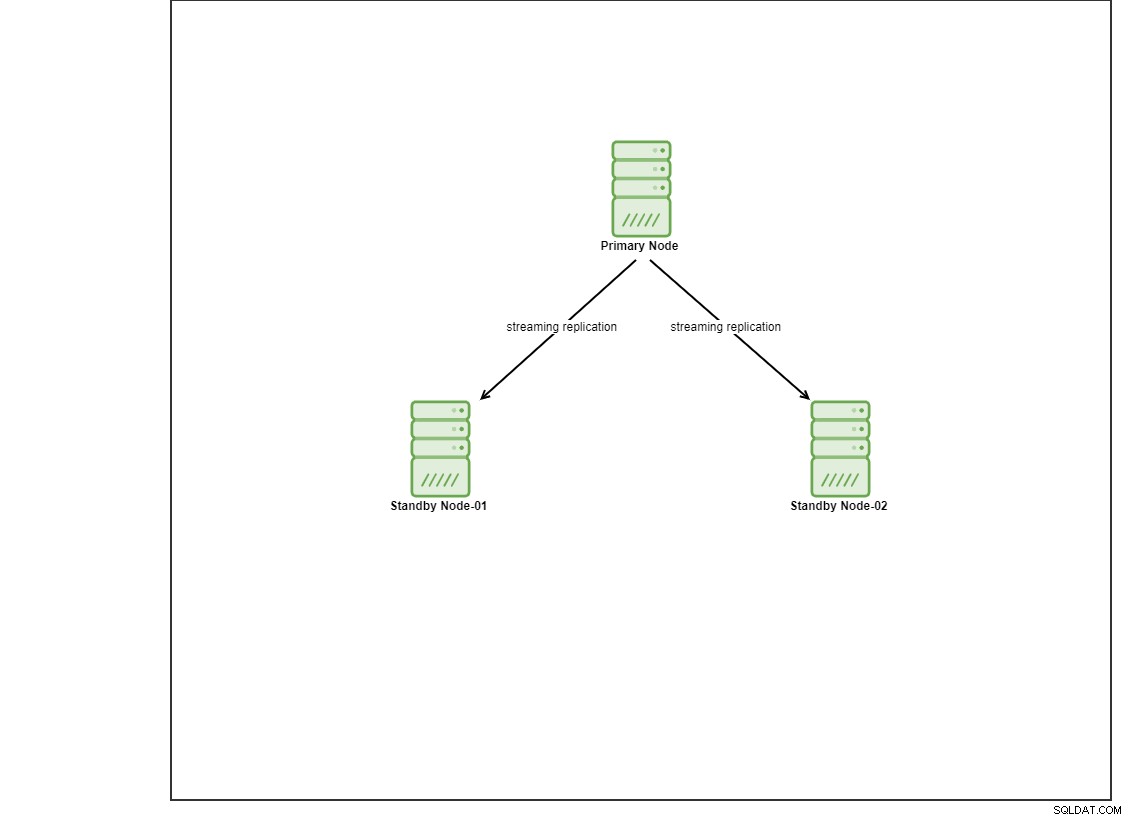
इस डेमो के लिए, मैंने vagrant का उपयोग करके 4 Centos 8 VMs का प्रावधान किया है। एक नियंत्रक नोड के रूप में कार्य करेगा और अन्य 2 वीएम तैनात किए जाने वाले डेटाबेस नोड्स के रूप में कार्य करेंगे। हम इस ब्लॉग पोस्ट में Ansible को कैसे स्थापित करें, इस बारे में विवरण में नहीं जा रहे हैं, लेकिन यदि आप गाइड देखना चाहते हैं, तो बेझिझक इस लिंक पर जाएँ। ध्यान दें कि हम एक प्राथमिक और 2 स्टैंडबाय नोड्स के साथ एक स्ट्रीमिंग प्रतिकृति टोपोलॉजी सेट करने के लिए 3 नोड्स का उपयोग कर रहे हैं। आजकल, कई उत्पादन डेटाबेस उच्च उपलब्धता सेटअप में हैं और 3 नोड सेटअप एक सामान्य है।
PostgreSQL इंस्टॉल करना
Ansible का उपयोग करके PostgreSQL को स्थापित करने के कई तरीके हैं। आज, मैं इस उद्देश्य को प्राप्त करने के लिए Ansible Roles का उपयोग करूँगा। उत्तरदायी भूमिकाएँ संक्षेप में एक सेवा को कॉन्फ़िगर करने जैसे एक निश्चित उद्देश्य की पूर्ति के लिए होस्ट को कॉन्फ़िगर करने के लिए कार्यों का एक समूह है। Ansible भूमिकाओं को YAML फ़ाइलों का उपयोग करके परिभाषित किया गया है, जिसमें एक पूर्वनिर्धारित निर्देशिका संरचना है जो Ansible Galaxy पोर्टल से डाउनलोड के लिए उपलब्ध है।
दूसरी ओर Ansible Galaxy, Ansible भूमिकाओं के लिए एक भंडार है जो आपके ऑटोमेशन प्रोजेक्ट्स को कारगर बनाने के लिए सीधे आपकी Playbooks में ड्रॉप करने के लिए उपलब्ध है।
इस डेमो के लिए, मैंने उन भूमिकाओं को चुना है जिन्हें ड्यूडेफेल्लाह द्वारा बनाए रखा गया है। इस भूमिका का उपयोग करने के लिए, हमें इसे नियंत्रक नोड में डाउनलोड और इंस्टॉल करना होगा। कार्य बहुत सीधा है और निम्न आदेश चलाकर किया जा सकता है बशर्ते कि आपके नियंत्रक नोड पर Ansible स्थापित किया गया हो:
$ ansible-galaxy install dudefellah.postgresqlएक बार भूमिका आपके नियंत्रक नोड में सफलतापूर्वक स्थापित हो जाने पर आपको निम्न परिणाम दिखाई देने चाहिए:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
इस भूमिका का उपयोग करके PostgreSQL को स्थापित करने के लिए, कुछ चरणों को पूरा करने की आवश्यकता है। यहाँ Ansible Playbook आता है। Ansible Playbook वह जगह है जहाँ हम Ansible कोड या स्क्रिप्ट का एक संग्रह लिख सकते हैं जिसे हम प्रबंधित नोड्स पर चलाना चाहते हैं। Ansible Playbook YAML का उपयोग करता है और इसमें एक या एक से अधिक नाटक एक विशेष क्रम में चलते हैं। आप होस्ट के साथ-साथ कार्यों के एक सेट को भी परिभाषित कर सकते हैं जिसे आप उस असाइन किए गए होस्ट या प्रबंधित नोड्स पर चलाना चाहते हैं।
सभी कार्यों को लॉग इन करने वाले उत्तरदायी उपयोगकर्ता के रूप में निष्पादित किया जाएगा। हमारे लिए 'रूट' सहित एक अलग उपयोगकर्ता के साथ कार्यों को निष्पादित करने के लिए, हम बन का उपयोग कर सकते हैं। आइए नीचे दिए गए pg-play.yml पर एक नज़र डालें:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13जैसा कि आप देख सकते हैं, मैंने मेजबानों को pgcluster के रूप में परिभाषित किया है और बनने का उपयोग किया है ताकि Ansible कार्यों को sudo विशेषाधिकार के साथ चलाए। उपयोगकर्ता आवारा पहले से ही sudoer समूह में है। मैंने उस भूमिका को भी परिभाषित किया है जिसे मैंने dudefellah.postgresql स्थापित किया था। pgcluster को मेरे द्वारा बनाई गई होस्ट फ़ाइल में परिभाषित किया गया है। यदि आपको आश्चर्य है कि यह कैसा दिखता है, तो आप नीचे देख सकते हैं:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleइसके अलावा, मैंने एक और कस्टम फ़ाइल (custom_var.yml) बनाई है जिसमें मैंने PostgreSQL के लिए सभी कॉन्फ़िगरेशन और सेटिंग शामिल की हैं जिन्हें मैं लागू करना चाहता हूं। कस्टम फ़ाइल का विवरण नीचे दिया गया है:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }इंस्टॉलेशन चलाने के लिए, हमें केवल निम्नलिखित कमांड को निष्पादित करना है। आप प्लेबुक फ़ाइल बनाए बिना ansible-playbook कमांड नहीं चला पाएंगे (मेरे मामले में यह pg-play.yml है)।
$ ansible-playbook pg-play.yml -i pghostइस आदेश को निष्पादित करने के बाद, यह भूमिका द्वारा परिभाषित कुछ कार्यों को चलाएगा और यदि आदेश सफलतापूर्वक चला तो यह संदेश दिखाएगा:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12एक बार जब ansible ने कार्यों को पूरा कर लिया, तो मैंने दास (n2) में लॉग इन किया, PostgreSQL सेवा को रोक दिया, डेटा निर्देशिका की सामग्री को हटा दिया (/var/lib/pgsql/13/data/) और बैकअप कार्य आरंभ करने के लिए निम्न आदेश चलाएँ:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |पोस्टग्रेएसक्यूएल सेवा को वापस शुरू करने के बाद हम निम्नलिखित कमांड का उपयोग करके स्टैंडबाय पर प्रतिकृति की स्थिति की जांच कर सकते हैं:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyजैसा कि आप देख सकते हैं, पोस्टग्रेएसक्यूएल के लिए प्रतिकृति स्थापित करने के लिए हमें बहुत सारे काम करने की आवश्यकता है, भले ही हमने कुछ कार्यों को स्वचालित कर दिया हो। आइए देखें कि यह कैसे ClusterControl के साथ पूरा किया जा सकता है।
ClusterControl GUI का उपयोग करके PostgreSQL परिनियोजन
अब जब हम जानते हैं कि Ansible का उपयोग करके PostgreSQL को कैसे परिनियोजित किया जाता है, तो आइए देखें कि हम ClusterControl का उपयोग करके कैसे परिनियोजित कर सकते हैं। ClusterControl MySQL, MariaDB, MongoDB के साथ-साथ TimescaleDB सहित डेटाबेस क्लस्टर के लिए एक प्रबंधन और स्वचालन सॉफ्टवेयर है। यह आपके डेटाबेस क्लस्टर को तैनात, मॉनिटर, प्रबंधित और स्केल करने में मदद करता है। डेटाबेस को तैनात करने के दो तरीके हैं, इस ब्लॉग पोस्ट में हम आपको दिखाएंगे कि ग्राफिकल यूजर इंटरफेस (जीयूआई) का उपयोग करके इसे कैसे तैनात किया जाए, यह मानते हुए कि आपके पास पहले से ही आपके पर्यावरण पर क्लस्टर कंट्रोल स्थापित है।
पहला कदम है कि आप अपने ClusterControl में लॉग इन करें और डिप्लॉय पर क्लिक करें:
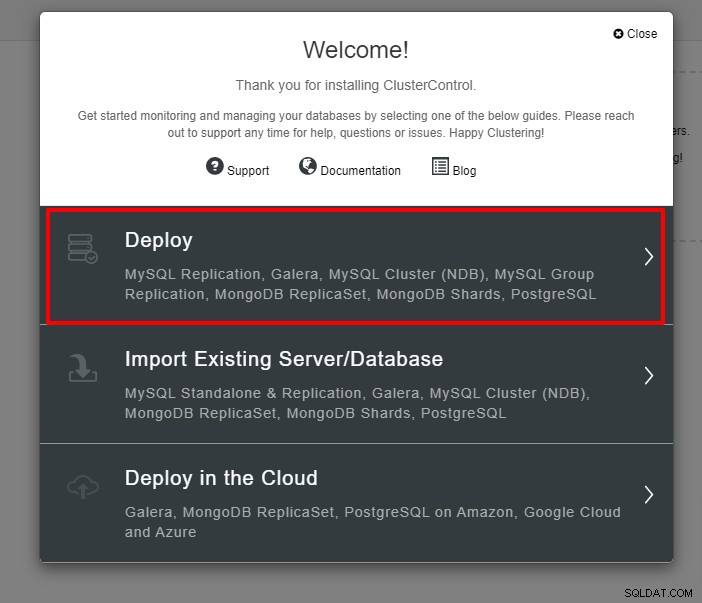
आपको परिनियोजन के अगले चरण के लिए नीचे स्क्रीनशॉट के साथ प्रस्तुत किया जाएगा , जारी रखने के लिए PostgreSQL टैब चुनें:
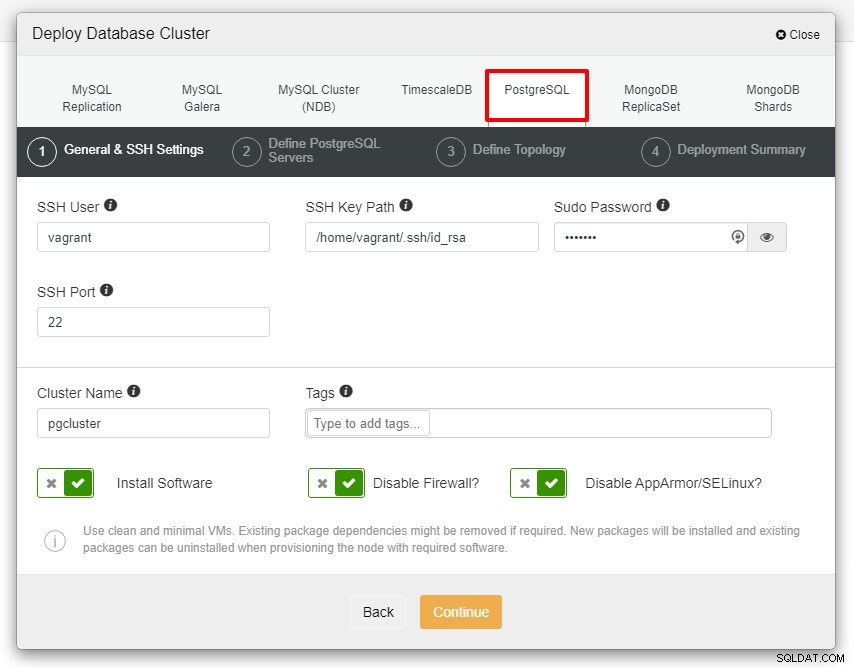
आगे बढ़ने से पहले, मैं आपको याद दिलाना चाहूंगा कि ClusterControl नोड और डेटाबेस नोड्स के बीच कनेक्शन पासवर्ड रहित होना चाहिए। परिनियोजन से पहले, हमें केवल ClusterControl नोड से ssh-keygen उत्पन्न करना है और फिर इसे सभी नोड्स में कॉपी करना है। अपनी आवश्यकता के अनुसार SSH उपयोगकर्ता, सूडो पासवर्ड के साथ-साथ क्लस्टर नाम के लिए इनपुट भरें और जारी रखें पर क्लिक करें।
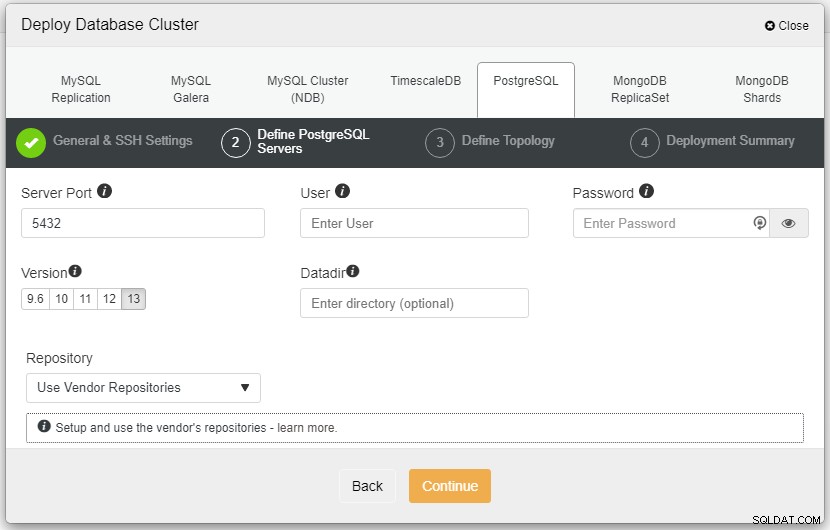
उपरोक्त स्क्रीनशॉट में, आपको सर्वर पोर्ट (यदि आप दूसरों का उपयोग करना चाहते हैं) को परिभाषित करने की आवश्यकता होगी, जिस उपयोगकर्ता को आप चाहते हैं, साथ ही साथ पासवर्ड और संस्करण जो आप चाहते हैं स्थापित करने के लिए।
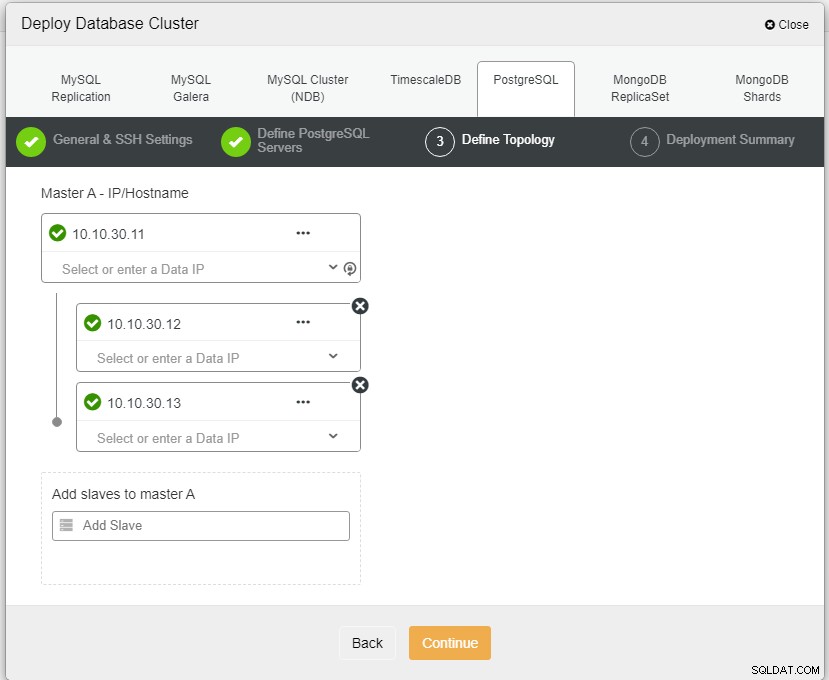
यहां हमें होस्टनाम या आईपी पते का उपयोग करने वाले सर्वर को परिभाषित करने की आवश्यकता है, जैसे इस मामले में 1 मास्टर और 2 स्लेव। अंतिम चरण हमारे क्लस्टर के लिए प्रतिकृति मोड चुनना है।
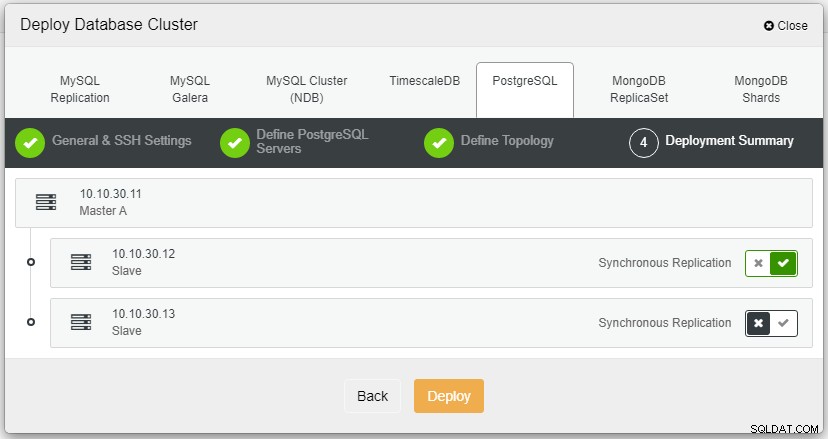
तैनाती पर क्लिक करने के बाद, परिनियोजन प्रक्रिया शुरू हो जाएगी और हम गतिविधि टैब में प्रगति की निगरानी कर सकते हैं।
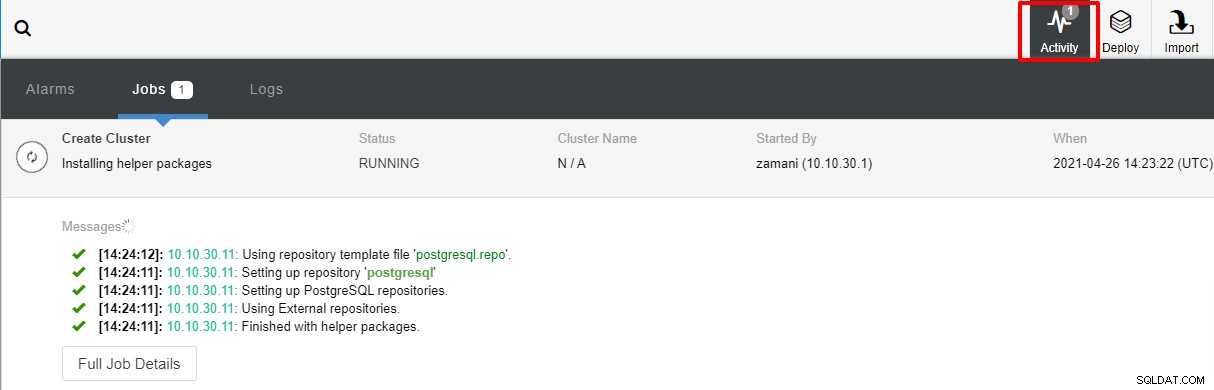
परिनियोजन में सामान्य रूप से कुछ मिनट लगेंगे, प्रदर्शन ज्यादातर नेटवर्क और सर्वर की विशिष्टता पर निर्भर करता है।

अब जबकि हमने ClusterControl का उपयोग करके PostgreSQL इंस्टॉल कर लिया है।
ClusterControl CLI का उपयोग करके PostgreSQL परिनियोजन
PostgreSQL को परिनियोजित करने का दूसरा वैकल्पिक तरीका CLI का उपयोग करना है। बशर्ते हम पहले से ही पासवर्ड रहित कनेक्शन को कॉन्फ़िगर कर चुके हों, हम केवल निम्नलिखित कमांड को निष्पादित कर सकते हैं और इसे समाप्त कर सकते हैं।
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logप्रक्रिया सफलतापूर्वक पूर्ण होने के बाद आपको नीचे संदेश देखना चाहिए और सत्यापित करने के लिए ClusterControl वेब में लॉग इन कर सकते हैं:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.निष्कर्ष
जैसा कि आप देख सकते हैं कि PostgreSQL को परिनियोजित करने के कुछ तरीके हैं। इस ब्लॉग पोस्ट में, हमने सीखा है कि Ansible का उपयोग करके और साथ ही हमारे ClusterControl का उपयोग करके इसे कैसे परिनियोजित किया जाए। दोनों तरीकों का पालन करना आसान है और न्यूनतम सीखने की अवस्था के साथ हासिल किया जा सकता है। क्लस्टरकंट्रोल के साथ, स्ट्रीमिंग प्रतिकृति सेटअप को कनेक्शन विफलता, वर्चुअल आईपी और सेटअप में कनेक्शन पूलिंग जोड़ने के लिए HAProxy, VIP और PGBouncer के साथ पूरक किया जा सकता है।
ध्यान दें कि परिनियोजन उत्पादन डेटाबेस वातावरण का केवल एक पहलू है। इसे चालू रखना और चलाना, विफलताओं को स्वचालित करना, टूटे हुए नोड्स को पुनर्प्राप्त करना और निगरानी, चेतावनी, बैकअप जैसे अन्य पहलू आवश्यक हैं।
उम्मीद है, यह ब्लॉग पोस्ट आप में से कुछ के लिए फायदेमंद होगा और पोस्टग्रेएसक्यूएल परिनियोजन को स्वचालित करने के बारे में एक विचार देगा।