उच्च उपलब्धता कई प्रणालियों के लिए एक आवश्यकता है, चाहे आप किसी भी तकनीक का उपयोग कर रहे हों। यह डेटाबेस के लिए विशेष रूप से महत्वपूर्ण है, क्योंकि वे डेटा संग्रहीत करते हैं जिस पर एप्लिकेशन भरोसा करते हैं। आवश्यकताओं के आधार पर, PostgreSQL के लिए एक उच्च उपलब्धता वातावरण को तैनात करने के विभिन्न तरीके हैं, लेकिन एक पूरक उपकरण का उपयोग करना हमेशा आवश्यक होता है क्योंकि मूल PostgreSQL सुविधाएँ पर्याप्त नहीं होती हैं।
इस ब्लॉग में, हम देखेंगे कि उच्च उपलब्धता के लिए PostgreSQL के लिए Percona वितरण को कैसे परिनियोजित किया जाए, और इसे करने के लिए किस प्रकार के उपकरण आवश्यक हैं।
PostgreSQL के लिए Percona वितरण
यह आपके PostgreSQL डेटाबेस सिस्टम को प्रबंधित करने में आपकी सहायता करने के लिए टूल का एक संग्रह है। यह पोस्टग्रेएसक्यूएल स्थापित करता है और इसे एक्सटेंशन के चयन से पूरा करता है जो आवश्यक व्यावहारिक कार्यों को कुशलतापूर्वक हल करने में सक्षम बनाता है, जिसमें निम्न शामिल हैं:
- pg_repack :यह PostgreSQL डेटाबेस ऑब्जेक्ट का पुनर्निर्माण करता है।
- pgaudit :यह मानक पोस्टग्रेएसक्यूएल लॉगिंग सुविधा के माध्यम से विस्तृत सत्र या ऑब्जेक्ट ऑडिट लॉगिंग प्रदान करता है।
- pgBackRest :यह PostgreSQL के लिए एक बैकअप और पुनर्स्थापना समाधान है।
- पेट्रोनी :यह PostgreSQL के लिए एक उच्च उपलब्धता समाधान है।
- pg_stat_monitor :यह पोस्टग्रेएसक्यूएल के लिए आंकड़े एकत्र और एकत्र करता है और हिस्टोग्राम जानकारी प्रदान करता है।
- अतिरिक्त PostgreSQL योगदान एक्सटेंशन का संग्रह।
PostgreSQL पर उच्च उपलब्धता
पोस्टग्रेएसक्यूएल उच्च उपलब्धता के लिए अलग-अलग आर्किटेक्चर हैं, लेकिन सबसे आम मास्टर-स्लेव टोपोलॉजी (प्राथमिक-स्टैंडबाय) है। यह एक या अधिक स्टैंडबाय नोड्स के साथ एक प्राथमिक डेटाबेस पर आधारित है। ये स्टैंडबाय डेटाबेस प्राथमिक के साथ सिंक्रनाइज़ (या लगभग सिंक्रनाइज़) रहेंगे, यह इस बात पर निर्भर करता है कि प्रतिकृति सिंक्रोनस या एसिंक्रोनस है या नहीं। यदि मुख्य सर्वर विफल हो जाता है, तो स्टैंडबाय में मुख्य सर्वर का लगभग सभी डेटा होता है, और इसे जल्दी से नए प्राथमिक डेटाबेस सर्वर में बदला जा सकता है।
लेकिन एक मास्टर-स्लेव सेटअप प्रभावी रूप से उच्च उपलब्धता सुनिश्चित करने के लिए पर्याप्त नहीं है, क्योंकि आपको विफलताओं को संभालने की भी आवश्यकता होती है। एक बार विफलता का पता चलने के बाद, आपको एक स्टैंडबाय नोड का चयन करने में सक्षम होना चाहिए और इसे कम से कम देरी के साथ फेलओवर करना चाहिए। PostgreSQL में स्वयं एक स्वचालित विफलता तंत्र शामिल नहीं है, इसलिए इस स्वचालन के लिए कुछ कस्टम स्क्रिप्ट या तृतीय-पक्ष टूल की आवश्यकता होगी।
एक विफलता होने के बाद, एप्लिकेशन को तदनुसार अधिसूचित करने की आवश्यकता होती है, ताकि वे नए प्राथमिक नोड का उपयोग शुरू कर सकें। इसके अलावा, आपको विफलता के बाद हमारे आर्किटेक्चर की स्थिति का मूल्यांकन करने की आवश्यकता है, क्योंकि आप ऐसी स्थिति में चल सकते हैं जहां आपके पास केवल नया प्राथमिक चल रहा है (यानी, आपके पास प्राथमिक और समस्या से पहले केवल एक स्टैंडबाय नोड था)। उस स्थिति में, आपको किसी तरह एक नया स्टैंडबाय नोड जोड़ना होगा ताकि उच्च उपलब्धता के लिए मूल रूप से आपके पास मौजूद मास्टर-स्लेव सेटअप को फिर से बनाया जा सके।
इसे काम करने के लिए, आपको इस कार्य में सहायता के लिए विभिन्न टूल/सेवाओं की आवश्यकता होगी।
बैलेंसर लोड करें
लोड बैलेंसर ऐसे टूल हैं जिनका उपयोग आपके एप्लिकेशन से ट्रैफ़िक को प्रबंधित करने के लिए किया जा सकता है ताकि आपके डेटाबेस आर्किटेक्चर का अधिकतम लाभ उठाया जा सके।
यह न केवल हमारे डेटाबेस के भार को संतुलित करने के लिए उपयोगी है, बल्कि यह एप्लिकेशन को उपलब्ध/स्वस्थ नोड्स पर पुनर्निर्देशित करने में भी मदद करता है और यहां तक कि विभिन्न भूमिकाओं वाले पोर्ट को भी निर्दिष्ट करता है।
HAProxy एक लोड बैलेंसर है जो एक मूल से एक या अधिक गंतव्यों तक ट्रैफ़िक वितरित करता है और इस कार्य के लिए विशिष्ट नियमों और/या प्रोटोकॉल को परिभाषित कर सकता है। यदि कोई भी गंतव्य प्रतिसाद देना बंद कर देता है, तो उसे ऑफ़लाइन के रूप में चिह्नित कर दिया जाता है, और ट्रैफ़िक को शेष उपलब्ध गंतव्यों पर भेज दिया जाता है।
Kepalived एक ऐसी सेवा है जो आपको सर्वरों के एक सक्रिय/निष्क्रिय समूह के भीतर वर्चुअल आईपी को कॉन्फ़िगर करने की अनुमति देती है। यह वर्चुअल आईपी एक सक्रिय सर्वर को सौंपा गया है। यदि यह सर्वर विफल हो जाता है, तो आईपी स्वचालित रूप से "माध्यमिक" निष्क्रिय सर्वर में माइग्रेट हो जाता है, जिससे यह सिस्टम के लिए पारदर्शी तरीके से उसी आईपी के साथ काम करना जारी रखता है।
इन सभी चीजों को लागू करने के लिए आप इसे मैन्युअल रूप से कर सकते हैं, जिसका अर्थ होगा अतिरिक्त काम और समय लेने वाले कार्य, या आप इसे ClusterControl का उपयोग करके सिर्फ एक सिस्टम से कर सकते हैं।
आइए देखते हैं कि PostgreSQL के लिए अपने मौजूदा Percona वितरण को ClusterControl में कैसे आयात करें, और फिर HAProxy का उपयोग करके एक उच्च उपलब्धता वातावरण को कैसे कॉन्फ़िगर करें और इस सेटअप के आसपास एक अनुकूल और उपयोग में आसान इंटरफ़ेस से रखें।
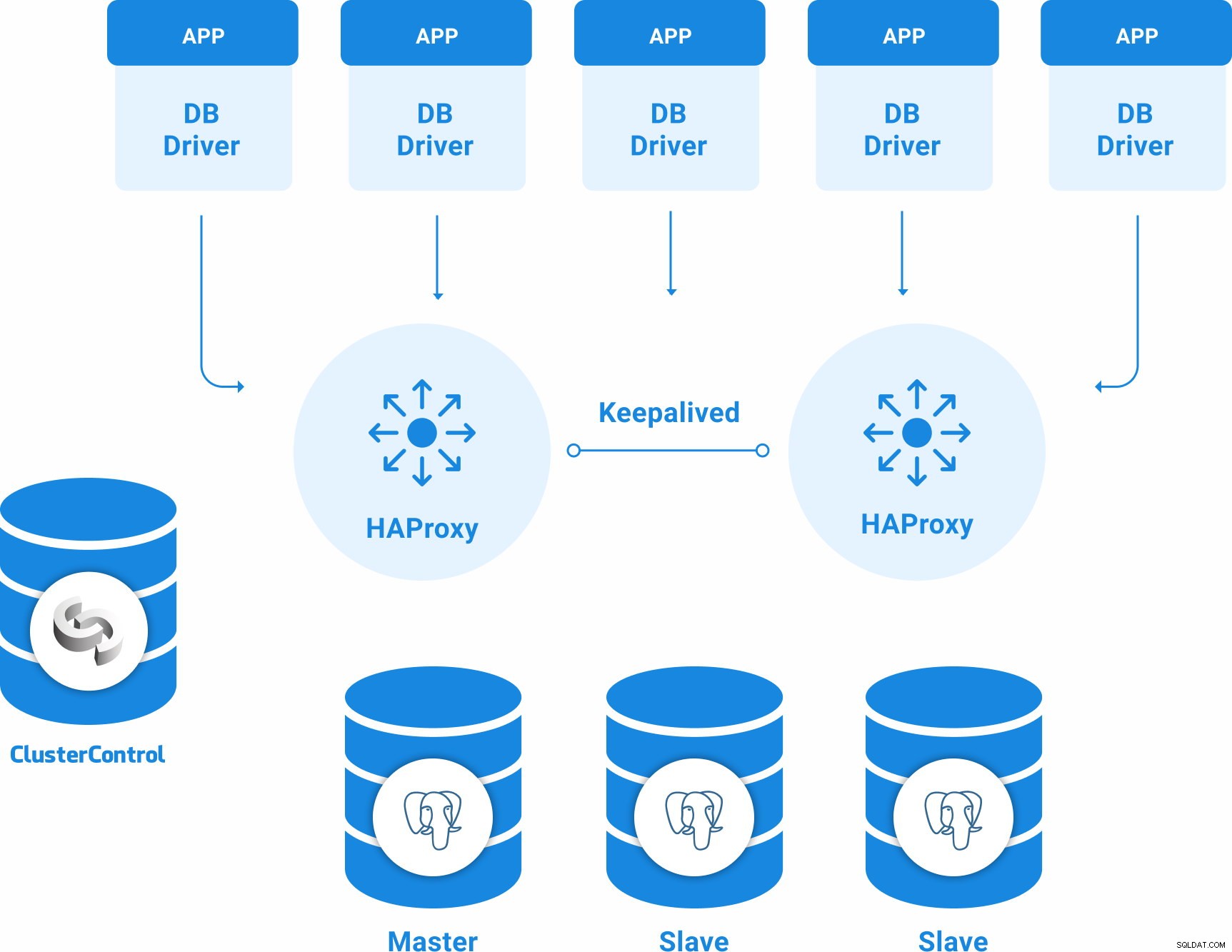
उच्च उपलब्धता के लिए PostgreSQL टोपोलॉजी
PostgreSQL के लिए एक बुनियादी उच्च उपलब्धता टोपोलॉजी हो सकती है:
- 3 PostgreSQL 12 सर्वर (एक प्राथमिक और दो स्टैंडबाय नोड्स)।
- 2 HAProxy लोड बैलेंसर।
- लोड बैलेंसर सर्वर के बीच कॉन्फ़िगर किया गया।
- 1 ClusterControl सर्वर
तो, आपके पास निम्न टोपोलॉजी होगी:
PostgreSQL के लिए Percona वितरण कैसे स्थापित करें
आइए PostgreSQL के लिए Percona डिस्ट्रीब्यूशन इंस्टॉल करके शुरू करते हैं। इस उदाहरण के लिए, हम CentOS 7 और PostgreSQL 12 का उपयोग करेंगे।
यदि आपने अपना क्लस्टर स्थापित कर लिया है, तो आप अपने मौजूदा डेटाबेस को ClusterControl में आयात करने के लिए अगले भाग पर जाएँ।
एपेल-रिलीज़ और परकोना-रिलीज़ इंस्टॉल करें
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmPostgreSQL 12 रिपॉजिटरी को सक्षम करें
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!सर्वर पैकेज स्थापित करें
$ yum install percona-postgresql12-serverध्यान दें कि यह पैकेज सभी Percona वितरण घटकों को स्थापित नहीं करेगा। इन घटकों को स्थापित करने के लिए उपयुक्त वैकल्पिक पैकेजों का उपयोग करें जैसा कि नीचे दिखाया गया है:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribडेटाबेस को प्रारंभ करें
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKसुनिश्चित करें कि आपके पास PostgreSQL प्रतिकृति को कॉन्फ़िगर करने में सक्षम होने के लिए सही कॉन्फ़िगरेशन है, जैसे:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onफिर, डेटाबेस सेवा प्रारंभ करें
$ systemctl start postgresql-12अब, यदि आप स्टैंडबाय नोड्स जोड़ना चाहते हैं, तो उन सभी नोड्स में चरण 1, 2, और 3 दोहराएं जिन्हें आप क्लस्टर में जोड़ना चाहते हैं। उन नोड्स के लिए, आपको कुछ और कॉन्फ़िगर करने की आवश्यकता नहीं है क्योंकि ClusterControl संबंधित कॉन्फ़िगरेशन बनाएगा।
ClusterControl में PostgreSQL के लिए Percona वितरण आयात करना
ClusterControl के साथ आप एक ही सिस्टम से अलग-अलग ओपन सोर्स डेटाबेस इंजन को तैनात या आयात कर सकते हैं, और इसका उपयोग करने के लिए केवल SSH एक्सेस और एक विशेषाधिकार प्राप्त उपयोगकर्ता की आवश्यकता होती है।
“आयात” अनुभाग पर जाएं और अपने PostgreSQL सर्वर की आवश्यक जानकारी को पूरा करें।
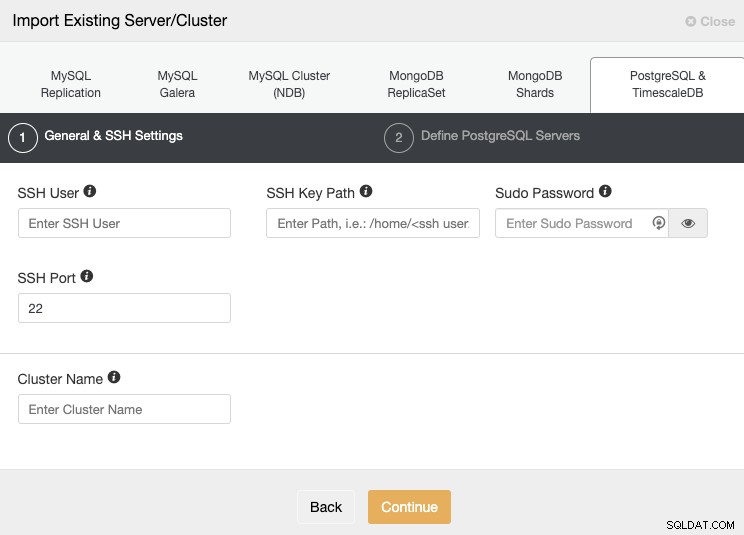
आपको SSH द्वारा कनेक्ट करने के लिए उपयोगकर्ता, कुंजी या पासवर्ड और पोर्ट निर्दिष्ट करना होगा अपने सर्वरों के लिए। आपको अपने नए क्लस्टर के लिए एक नाम की भी आवश्यकता है, अन्यथा, ClusterControl आपके लिए एक सामान्य नाम निर्दिष्ट करेगा।
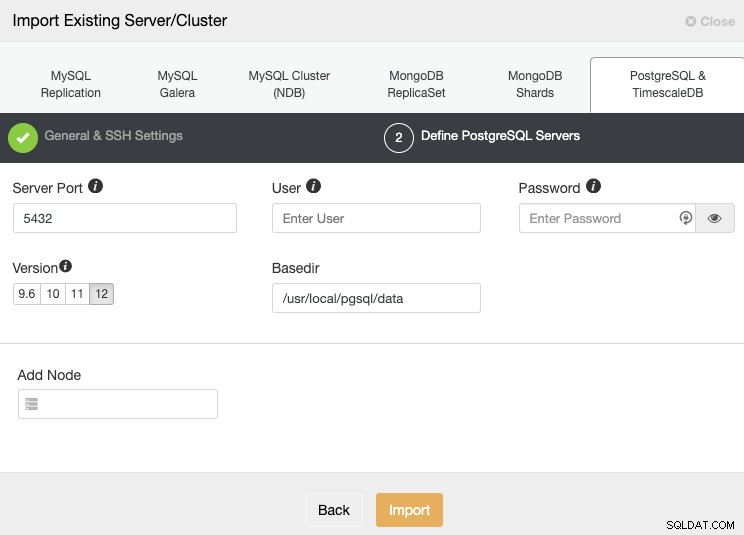
SSH एक्सेस जानकारी सेट करने के बाद, आपको डेटाबेस क्रेडेंशियल्स को परिभाषित करना होगा, प्रत्येक डेटाबेस नोड के लिए संस्करण, आधारित, और आईपी पता या होस्टनाम।
यदि आपके पास अभी तक प्रतिकृति कॉन्फ़िगर नहीं है, तो आपको केवल प्राथमिक नोड के लिए IP पता या होस्टनाम जोड़ने की आवश्यकता है, क्योंकि हम आपको दिखाएंगे कि बाद में बाकी नोड्स को कैसे जोड़ा जाए।
होस्टनाम या आईपी पता दर्ज करते समय सुनिश्चित करें कि आपको हरे रंग की टिक मिलती है, यह दर्शाता है कि ClusterControl नोड के साथ संचार करने में सक्षम है। फिर, आयात बटन पर क्लिक करें और तब तक प्रतीक्षा करें जब तक ClusterControl अपना काम पूरा नहीं कर लेता। आप ClusterControl गतिविधि अनुभाग में प्रक्रिया की निगरानी कर सकते हैं। जब यह समाप्त हो जाए, तो आप ClusterControl मुख्य स्क्रीन पर नया क्लस्टर देखेंगे। एक नई प्रतिकृति जोड़ने के लिए, क्लस्टर क्रियाओं पर जाएँ, और "प्रतिकृति दास जोड़ें" विकल्प चुनें।
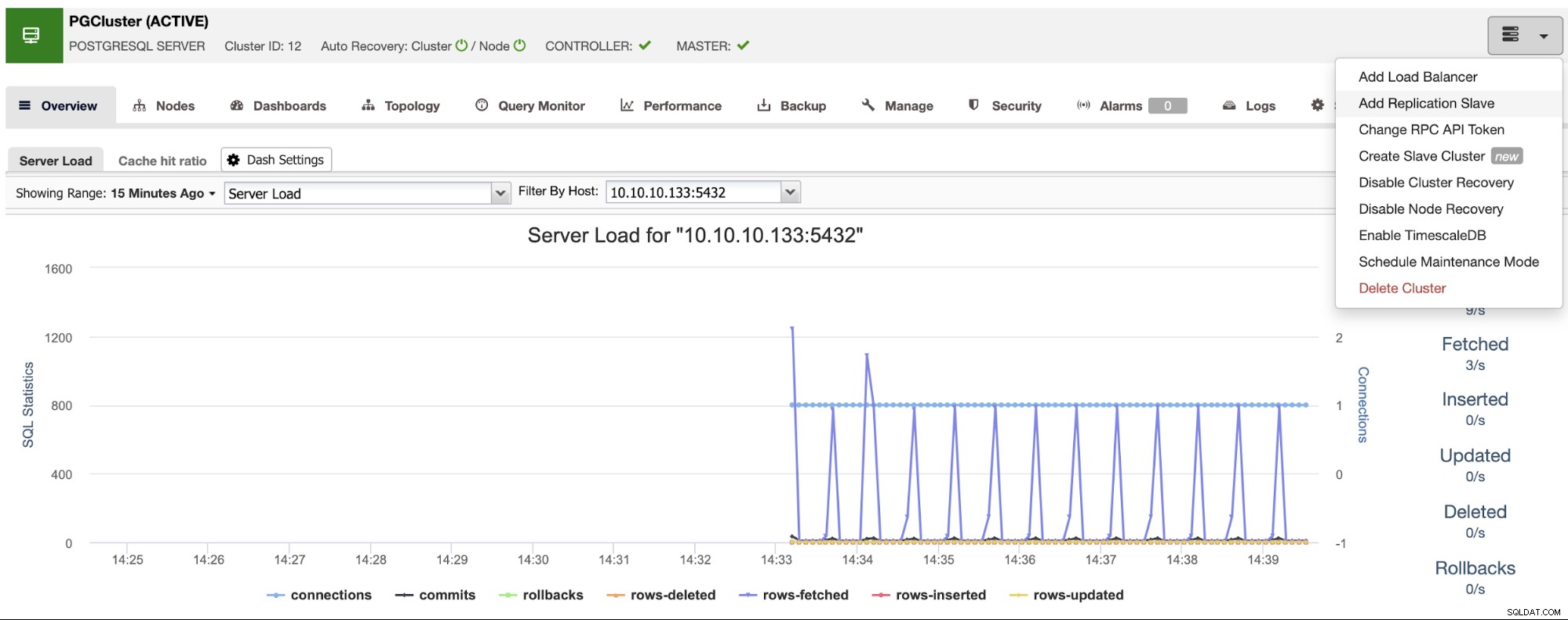
यदि आपने पिछले चरणों का पालन किया है, तो आपके पास PostgreSQL के लिए Percona वितरण स्थापित होगा सभी स्टैंडबाय नोड्स में, इसलिए आपको इस अनुभाग में "PostgreSQL सॉफ़्टवेयर स्थापित करें" को अक्षम करना होगा।
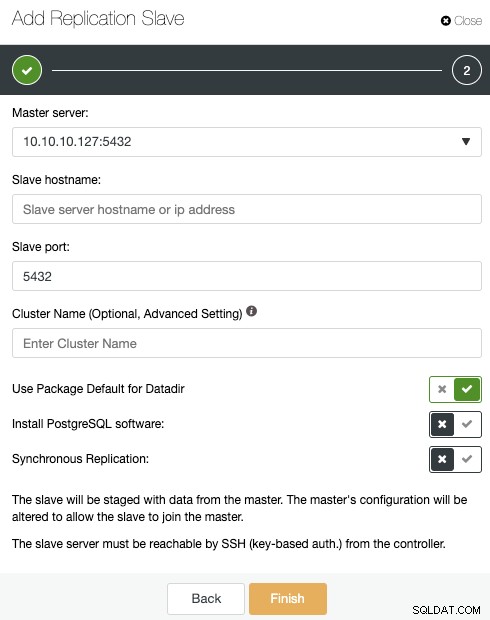
इस तरह, ClusterControl इसके बजाय PostgreSQL पैकेज के लिए स्थापित Percona वितरण का उपयोग करेगा आधिकारिक PostgreSQL संकुल को स्थापित करने के लिए।
जब आप इसे पूरा कर लेंगे, तो आप क्लस्टर में सभी नोड्स और अवलोकन अनुभाग में उन सभी की स्थिति देखेंगे।
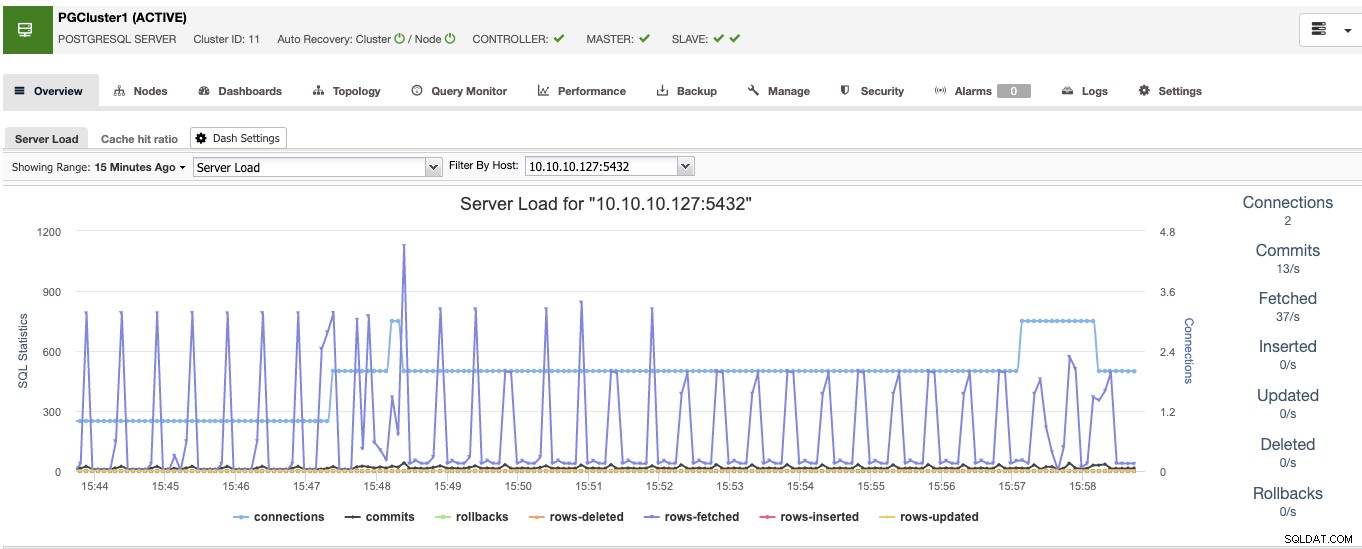
अब आपके पास डेटाबेस साइड तैयार है, आइए देखें कि हाई को कैसे पूरा करें ClusterControl का उपयोग करके शेष उपकरणों को जोड़कर उपलब्धता वातावरण।
बैलेंसर परिनियोजन लोड करें
लोड बैलेंसर परिनियोजन करने के लिए, क्लस्टर क्रियाओं में "लोड बैलेंसर जोड़ें" विकल्प चुनें और मांगी गई जानकारी भरें। 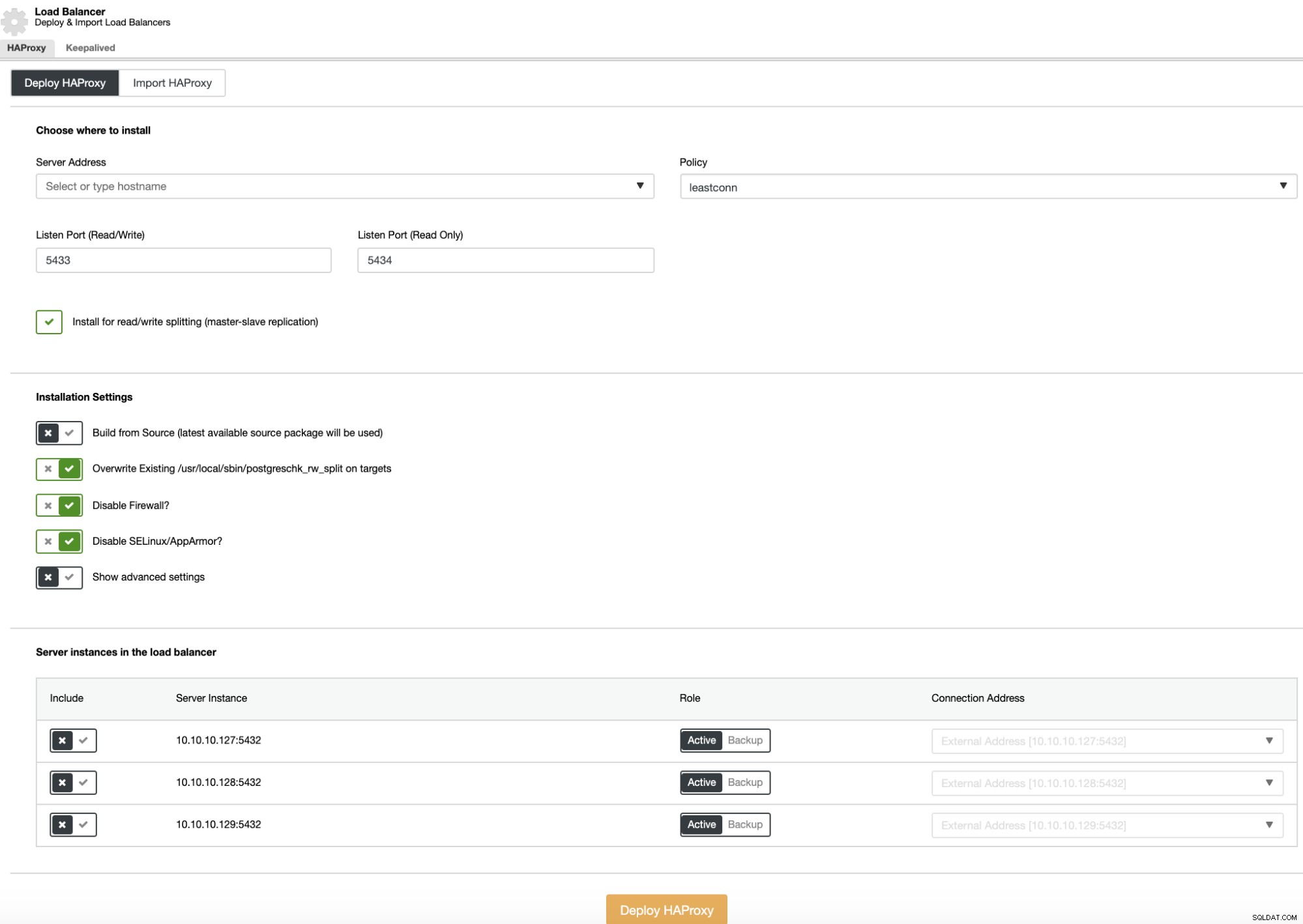
आपको केवल IP पता या होस्टनाम, पोर्ट, नीति और उन नोड्स को जोड़ने की आवश्यकता है जिन्हें आप लोड बैलेंसर कॉन्फ़िगरेशन में जोड़ने जा रहे हैं।
परिनियोजन बनाए रखा
कीपलाइव्ड परिनियोजन करने के लिए, क्लस्टर का चयन करें, क्लस्टर क्रियाओं पर जाएं, "लोड बैलेंसर जोड़ें" चुनें, और फिर "रख-रखाव" अनुभाग पर जाएं।
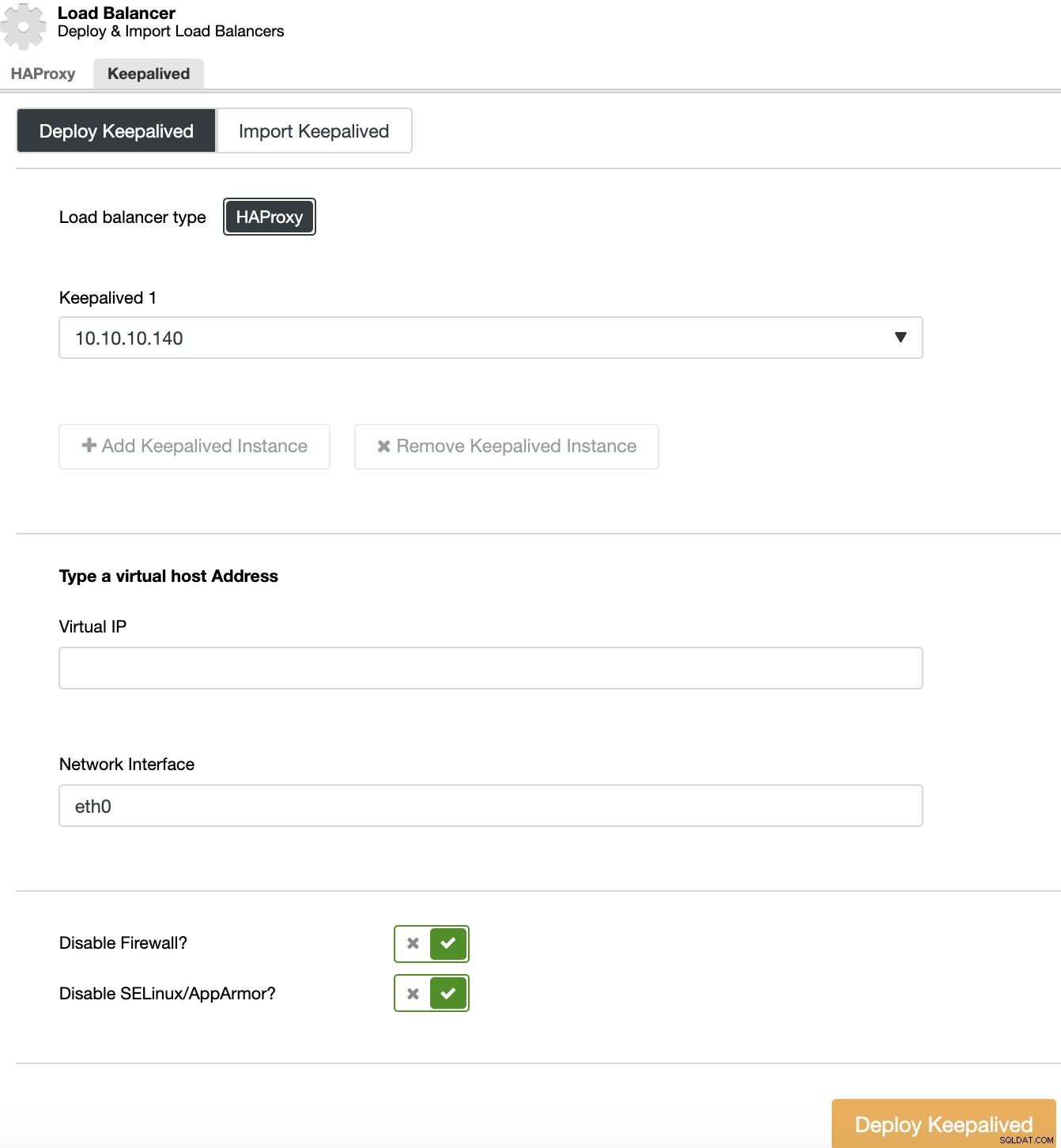
अपने उच्च उपलब्धता वातावरण के लिए, आपको लोड बैलेंसर सर्वर और वर्चुअल आईपी एड्रेस का चयन करना होगा, जिसका उपयोग आपको अपने क्लस्टर तक पहुंचने के लिए करना होगा। Keepalived इस वर्चुअल IP को सक्रिय लोड बैलेंसर में कॉन्फ़िगर करता है और विफलता के मामले में इसे एक लोड बैलेंसर से दूसरे में माइग्रेट करता है, ताकि आपका सेटअप सामान्य रूप से कार्य करना जारी रख सके।
निष्कर्ष
चूँकि आप अभी तक सीधे ClusterControl से PostgreSQL के लिए Percona डिस्ट्रीब्यूशन को परिनियोजित नहीं कर सकते हैं, इस ब्लॉग में, हमने आपको दिखाया कि ClusterControl का उपयोग करके इसे कैसे प्रबंधित किया जा सकता है, और एक उच्च उपलब्धता वातावरण के लिए HAProxy और Keepalived जैसे विभिन्न टूल कैसे जोड़ें। आसान तरीके से।