डिस्क पर जाने की तुलना में मेमोरी से पढ़ना हमेशा अधिक प्रदर्शनकारी होगा, इसलिए सभी डेटाबेस तकनीकों के लिए आप अधिक से अधिक मेमोरी का उपयोग करना चाहेंगे। यदि आप कॉन्फ़िगरेशन के बारे में सुनिश्चित नहीं हैं, या आपको कोई त्रुटि है, तो यह उच्च मेमोरी उपयोग या यहां तक कि एक आउट-ऑफ-मेमोरी समस्या उत्पन्न कर सकता है।
इस ब्लॉग में, हम देखेंगे कि आपके PostgreSQL मेमोरी उपयोग की जांच कैसे करें और इसे ट्यून करने के लिए आपको किस पैरामीटर को ध्यान में रखना चाहिए। इसके लिए, चलिए PostgreSQL के आर्किटेक्चर का एक सिंहावलोकन देखकर शुरू करते हैं।
PostgreSQL आर्किटेक्चर
PostgreSQL का आर्किटेक्चर तीन मूलभूत भागों पर आधारित है:प्रोसेस, मेमोरी और डिस्क।
स्मृति को दो श्रेणियों में वर्गीकृत किया जा सकता है:
- स्थानीय मेमोरी :यह प्रत्येक बैकएंड प्रक्रिया द्वारा प्रश्नों के प्रसंस्करण के लिए अपने स्वयं के उपयोग के लिए लोड किया जाता है। इसे उप-क्षेत्रों में बांटा गया है:
- वर्क मेम:वर्क मेम का उपयोग ORDER BY और DISTINCT ऑपरेशंस द्वारा टुपल्स को सॉर्ट करने और टेबल्स में शामिल होने के लिए किया जाता है।
- रखरखाव कार्य मेम:कुछ प्रकार के रखरखाव संचालन इस क्षेत्र का उपयोग करते हैं। उदाहरण के लिए, VACUUM, यदि आप autovacuum_work_mem निर्दिष्ट नहीं कर रहे हैं।
- अस्थायी बफ़र्स:इसका उपयोग अस्थायी तालिकाओं को संग्रहीत करने के लिए किया जाता है।
- साझा स्मृति :इसे शुरू होने पर PostgreSQL सर्वर द्वारा आवंटित किया जाता है, और इसका उपयोग सभी प्रक्रियाओं द्वारा किया जाता है। इसे उप-क्षेत्रों में बांटा गया है:
- साझा बफर पूल:जहां PostgreSQL डिस्क से टेबल और इंडेक्स के साथ पेज लोड करता है, सीधे मेमोरी से काम करने के लिए, डिस्क एक्सेस को कम करता है।
- WAL बफर:WAL डेटा PostgreSQL में लेन-देन लॉग है और इसमें डेटाबेस में परिवर्तन शामिल हैं। वाल बफर वह क्षेत्र है जहां वाल फाइलों में डिस्क पर लिखने से पहले वाल डेटा अस्थायी रूप से संग्रहीत किया जाता है। यह हर कुछ पूर्वनिर्धारित समय पर किया जाता है जिसे चेकपॉइंट कहा जाता है। सर्वर के विफल होने की स्थिति में जानकारी के नुकसान से बचने के लिए यह बहुत महत्वपूर्ण है।
- कमिट लॉग:यह समवर्ती नियंत्रण के लिए सभी लेनदेन की स्थिति को सहेजता है।
कैसे पता करें कि क्या हो रहा है
यदि आप उच्च स्मृति उपयोग कर रहे हैं, तो सबसे पहले, आपको पुष्टि करनी चाहिए कि कौन सी प्रक्रिया खपत उत्पन्न कर रही है।
“शीर्ष” Linux कमांड का उपयोग करना
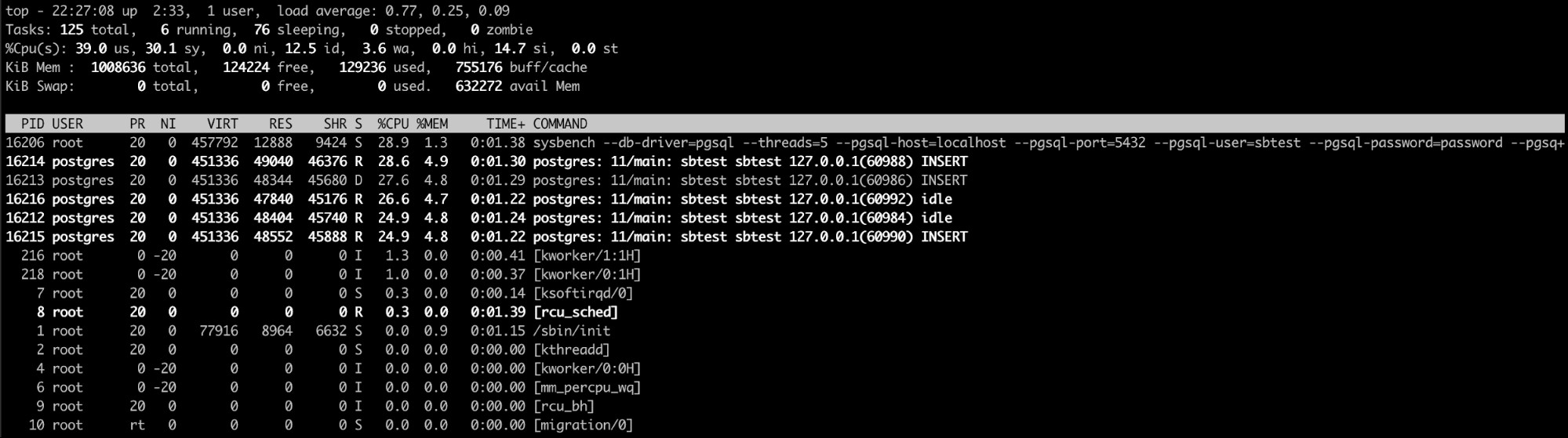
शीर्ष linux कमांड शायद यहां सबसे अच्छा विकल्प है (या यहां तक कि समान एक htop की तरह)। इस कमांड से, आप उन प्रक्रियाओं/प्रक्रियाओं को देख सकते हैं जो बहुत अधिक मेमोरी की खपत कर रही हैं।
जब आप पुष्टि करते हैं कि इस समस्या के लिए PostgreSQL जिम्मेदार है, तो अगला चरण यह जांचना है कि क्यों।
PostgreSQL लॉग का उपयोग करना
पोस्टग्रेएसक्यूएल और सिस्टम लॉग दोनों की जांच करना निश्चित रूप से आपके डेटाबेस/सिस्टम में क्या हो रहा है, इसके बारे में अधिक जानकारी प्राप्त करने का एक अच्छा तरीका है। आप जैसे संदेश देख सकते हैं:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childयदि आपके पास पर्याप्त खाली मेमोरी नहीं है।
या यहां तक कि कई डेटाबेस संदेश त्रुटियां जैसे:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedजब आप डेटाबेस की तरफ कुछ अनपेक्षित व्यवहार कर रहे हों। इसलिए, लॉग इन प्रकार के मुद्दों और इससे भी अधिक का पता लगाने के लिए उपयोगी होते हैं। आप "FATAL", "ERROR" या "Kill" जैसे कार्यों की तलाश में लॉग फ़ाइलों को पार्स करके इस निगरानी को स्वचालित कर सकते हैं, इसलिए ऐसा होने पर आपको एक अलर्ट प्राप्त होगा।
Pg_top का उपयोग करना
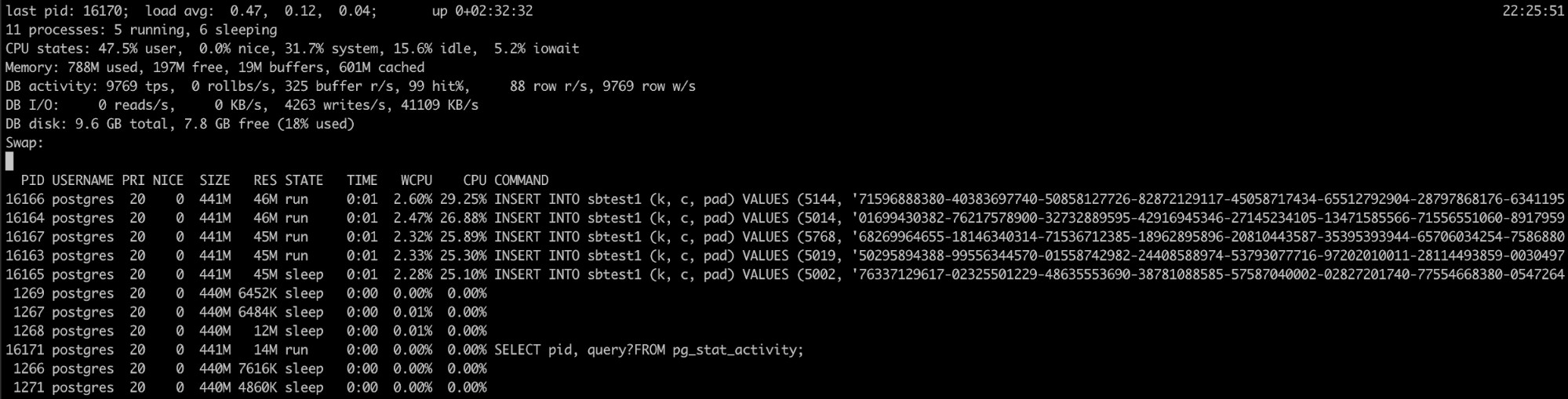
यदि आप जानते हैं कि PostgreSQL प्रक्रिया में उच्च मेमोरी उपयोग हो रहा है, लेकिन लॉग ने मदद नहीं की, आपके पास एक और टूल है जो यहां उपयोगी हो सकता है, pg_top।
यह टूल शीर्ष linux टूल के समान है, लेकिन यह विशेष रूप से PostgreSQL के लिए है। तो, इसका उपयोग करके, आपको अपने डेटाबेस के बारे में अधिक विस्तृत जानकारी होगी, और यदि आप कुछ गलत पाते हैं तो आप प्रश्नों को मार भी सकते हैं, या व्याख्या कार्य चला सकते हैं। आप इस टूल के बारे में अधिक जानकारी यहाँ प्राप्त कर सकते हैं।
लेकिन क्या होता है यदि आप किसी त्रुटि का पता नहीं लगा पाते हैं, और डेटाबेस अभी भी बहुत अधिक RAM का उपयोग कर रहा है। तो, आपको शायद डेटाबेस कॉन्फ़िगरेशन की जांच करने की आवश्यकता होगी।
किस कॉन्फ़िगरेशन पैरामीटर को ध्यान में रखना चाहिए
यदि सब कुछ ठीक दिखता है लेकिन आपको अभी भी उच्च उपयोग की समस्या है, तो आपको यह पुष्टि करने के लिए कॉन्फ़िगरेशन की जांच करनी चाहिए कि क्या यह सही है। तो, निम्नलिखित पैरामीटर हैं जिन्हें आपको इस मामले में ध्यान में रखना चाहिए।
shared_buffers
यह मेमोरी की वह मात्रा है जो डेटाबेस सर्वर साझा मेमोरी बफ़र्स के लिए उपयोग करता है। यदि यह मान बहुत कम है, तो डेटाबेस अधिक डिस्क का उपयोग करेगा, जिससे अधिक धीमापन होगा, लेकिन यदि यह बहुत अधिक है, तो उच्च मेमोरी उपयोग उत्पन्न कर सकता है। दस्तावेज़ीकरण के अनुसार, यदि आपके पास 1GB या अधिक RAM वाला एक समर्पित डेटाबेस सर्वर है, तो साझा_बफ़र्स के लिए एक उचित प्रारंभिक मान आपके सिस्टम की मेमोरी का 25% है।
work_mem
यह डिस्क पर अस्थायी फ़ाइलों को लिखने से पहले ORDER BY, DISTINCT और JOIN द्वारा उपयोग की जाने वाली मेमोरी की मात्रा को निर्दिष्ट करता है। Shared_buffers की तरह, यदि हम इस पैरामीटर को बहुत कम कॉन्फ़िगर करते हैं, तो हम डिस्क में अधिक संचालन कर सकते हैं, लेकिन बहुत अधिक मेमोरी उपयोग के लिए खतरनाक है। डिफ़ॉल्ट मान 4 एमबी है।
max_connections
Work_mem भी max_connections मान के साथ हाथ से जाता है, क्योंकि प्रत्येक कनेक्शन एक ही समय में इन कार्यों को निष्पादित करेगा, और प्रत्येक ऑपरेशन को इस मान द्वारा निर्दिष्ट की गई मेमोरी का उपयोग करने की अनुमति दी जाएगी। अस्थायी फ़ाइलों में डेटा लिखना शुरू करता है। यह पैरामीटर हमारे डेटाबेस में एक साथ कनेक्शन की अधिकतम संख्या निर्धारित करता है, यदि हम उच्च संख्या में कनेक्शन कॉन्फ़िगर करते हैं, और इसे ध्यान में नहीं रखते हैं, तो आप संसाधन समस्याएँ शुरू कर सकते हैं। डिफ़ॉल्ट मान 100 है।
temp_buffers
अस्थायी बफ़र्स का उपयोग प्रत्येक सत्र में उपयोग की जाने वाली अस्थायी तालिकाओं को संग्रहीत करने के लिए किया जाता है। यह पैरामीटर इस कार्य के लिए अधिकतम मात्रा में मेमोरी सेट करता है। डिफ़ॉल्ट मान 8 एमबी है।
रखरखाव_कार्य_मेम
यह अधिकतम मेमोरी है जिसे वैक्यूमिंग, इंडेक्स या विदेशी कुंजी जोड़ने जैसे ऑपरेशन उपभोग कर सकते हैं। अच्छी बात यह है कि एक सत्र में इस प्रकार का केवल एक ही ऑपरेशन चलाया जा सकता है, और सिस्टम में एक ही समय में इनमें से कई को चलाना सबसे आम बात नहीं है। डिफ़ॉल्ट मान 64 एमबी है।
autovacuum_work_mem
वैक्यूम डिफ़ॉल्ट रूप से मेंटेनेंस_वर्क_मेम का उपयोग करता है, लेकिन हम इस पैरामीटर का उपयोग करके इसे अलग कर सकते हैं। हम यहां प्रत्येक ऑटोवैक्यूम कार्यकर्ता द्वारा उपयोग की जाने वाली मेमोरी की अधिकतम मात्रा निर्दिष्ट कर सकते हैं।
wal_buffers
WAL डेटा के लिए उपयोग की गई साझा मेमोरी की मात्रा जो अभी तक डिस्क पर नहीं लिखी गई है। डिफ़ॉल्ट सेटिंग शेयर्ड_बफ़र्स का 3% है, लेकिन 64kB से कम नहीं है और न ही एक WAL सेगमेंट के आकार से अधिक है, आमतौर पर 16MB।
निष्कर्ष
उच्च स्मृति उपयोग के विभिन्न कारण हैं, और मूल समस्या का पता लगाना एक समय लेने वाला कार्य हो सकता है। इस ब्लॉग में, हमने आपके PostgreSQL मेमोरी उपयोग की जांच करने के विभिन्न तरीकों का उल्लेख किया है और अत्यधिक मेमोरी उपयोग से बचने के लिए इसे ट्यून करने के लिए आपको किस पैरामीटर को ध्यान में रखना चाहिए।



