यह ब्लॉग PostgreSQL के लिए एक मल्टी-डेटासेंटर सेटअप को लागू करने का दूसरा भाग है। इस प्रहार में, हम दिखाएंगे कि इस प्रकार के वातावरण में PostgreSQL को कैसे तैनात किया जाए और ClusterControl ऑटो-रिकवरी सुविधा का उपयोग करके मास्टर विफलता के मामले में कैसे विफल किया जाए।
इस बिंदु पर, हम मान लेंगे कि आपके पास डेटा केंद्रों के बीच कनेक्टिविटी है (जैसा कि हमने इस ब्लॉग के पहले भाग में देखा था) और आपके पास इस कार्य के लिए आवश्यक सर्वर हैं (जैसा कि हमने इसमें भी उल्लेख किया है) पिछला भाग)।
एक PostgreSQL क्लस्टर परिनियोजित करें
हम इस कार्य के लिए ClusterControl का उपयोग करेंगे, इसलिए हम मान लेंगे कि आपने इसे स्थापित कर लिया है (इसे उसी लोड बैलेंसर सर्वर पर स्थापित किया जा सकता है, लेकिन यदि आप किसी भिन्न सर्वर का और भी बेहतर उपयोग कर सकते हैं)।
अपने ClusterControl सर्वर पर जाएं, और 'तैनाती' विकल्प चुनें। यदि आपके पास पहले से PostgreSQL इंस्टेंस चल रहा है, तो आपको इसके बजाय 'मौजूदा सर्वर/डेटाबेस आयात करें' का चयन करना होगा।
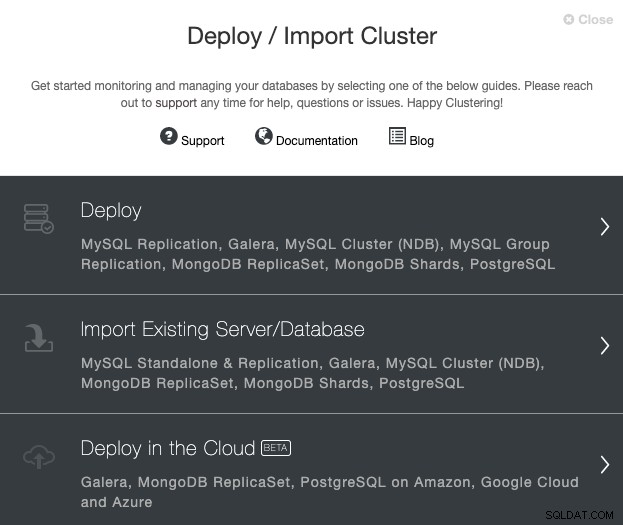
PostgreSQL का चयन करते समय, आपको उपयोगकर्ता, कुंजी या पासवर्ड और पोर्ट निर्दिष्ट करना होगा SSH द्वारा हमारे PostgreSQL होस्ट से कनेक्ट करें। आपको अपने नए क्लस्टर के लिए नाम की भी आवश्यकता है और यदि आप चाहते हैं कि ClusterControl आपके लिए संबंधित सॉफ़्टवेयर और कॉन्फ़िगरेशन स्थापित करे।
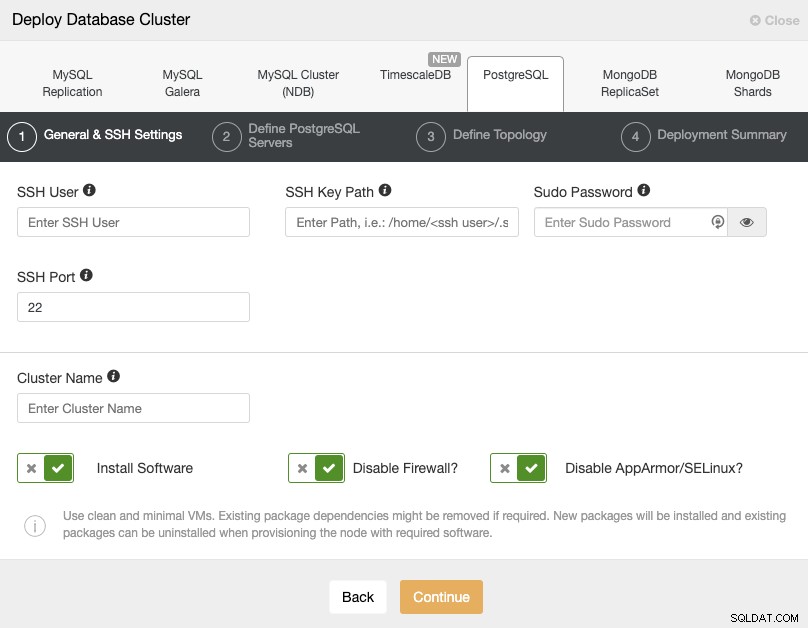
कृपया यहां इस कार्य के लिए ClusterControl उपयोगकर्ता आवश्यकताओं की जांच करें, लेकिन यदि आपने इसका पालन किया है पिछले ब्लॉग में, आपको यहां 'रिमोट' उपयोगकर्ता और सही एसएसएच पोर्ट का उपयोग करना चाहिए (जैसा कि हमने उल्लेख किया है, यदि आप वीपीएन के बजाय सार्वजनिक आईपी पते का उपयोग कर रहे हैं तो एक अलग का उपयोग करने की अनुशंसा की जाती है)।
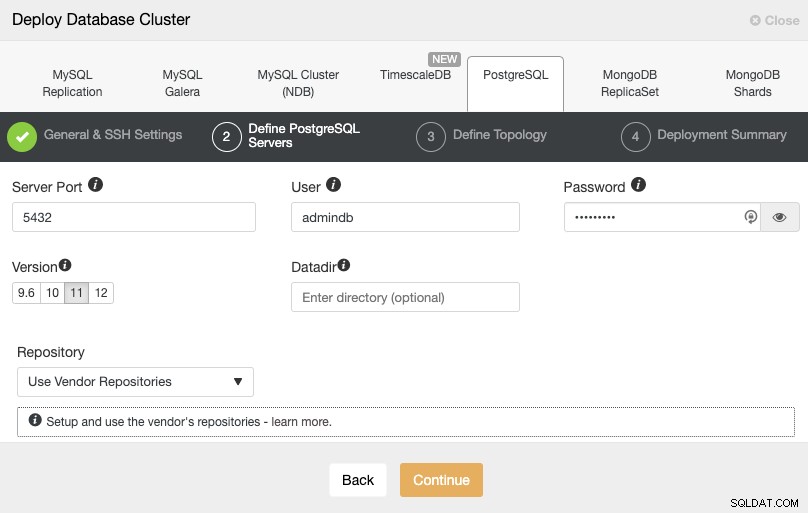
SSH एक्सेस जानकारी सेट करने के बाद, आपको डेटाबेस उपयोगकर्ता को परिभाषित करना होगा, संस्करण और डेटादिर (वैकल्पिक)। आप यह भी निर्दिष्ट कर सकते हैं कि किस भंडार का उपयोग करना है। अगले चरण में, आपको अपने सर्वर को उस क्लस्टर में जोड़ना होगा जिसे आप बनाने जा रहे हैं।
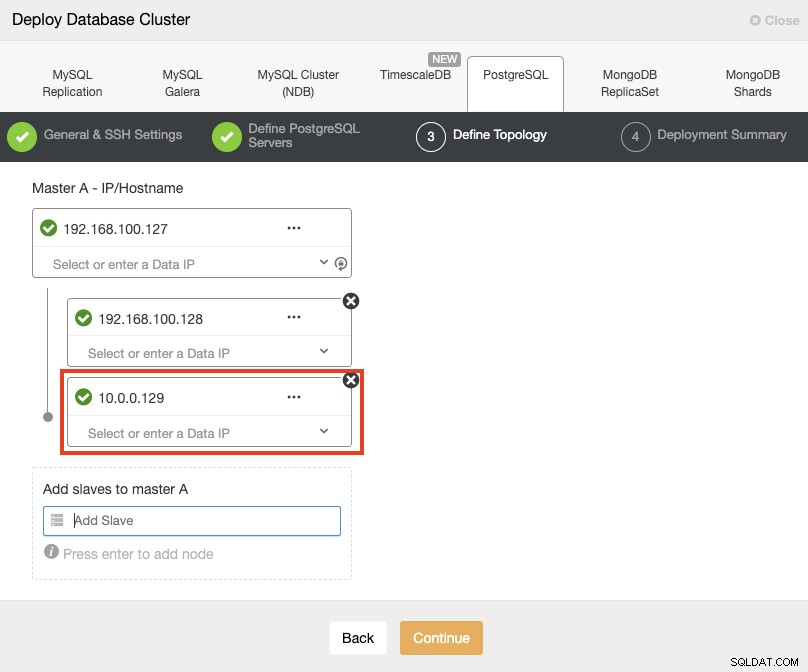
अपने सर्वर जोड़ते समय, आप IP या होस्टनाम दर्ज कर सकते हैं। इस भाग में, आप अपने सर्वर के सार्वजनिक आईपी पते का उपयोग करेंगे, और जैसा कि आप लाल बॉक्स में देख सकते हैं, मैं दूसरे स्टैंडबाय नोड के लिए एक अलग नेटवर्क का उपयोग कर रहा हूं। उपयोग किए जाने वाले नेटवर्क के बारे में ClusterControl की कोई सीमा नहीं है। इसके बारे में केवल एक ही आवश्यकता है कि एसएसएच को नोड तक पहुंच प्राप्त हो।
तो हमारे पिछले उदाहरण का अनुसरण करते हुए, ये IP पता होना चाहिए:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)आखिरी चरण में, आप चुन सकते हैं कि आपकी प्रतिकृति सिंक्रोनस या एसिंक्रोनस होगी या नहीं।
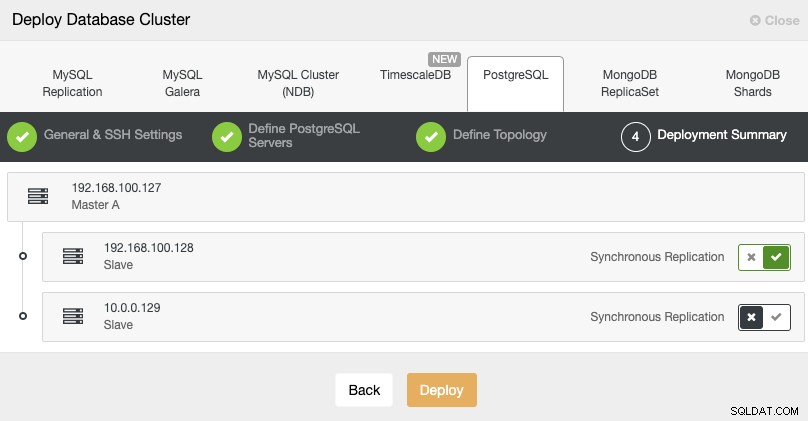
इस मामले में, अपने दूरस्थ नोड के लिए एसिंक्रोनस प्रतिकृति का उपयोग करना महत्वपूर्ण है , यदि नहीं, तो आपका क्लस्टर विलंबता या नेटवर्क समस्याओं से प्रभावित हो सकता है।
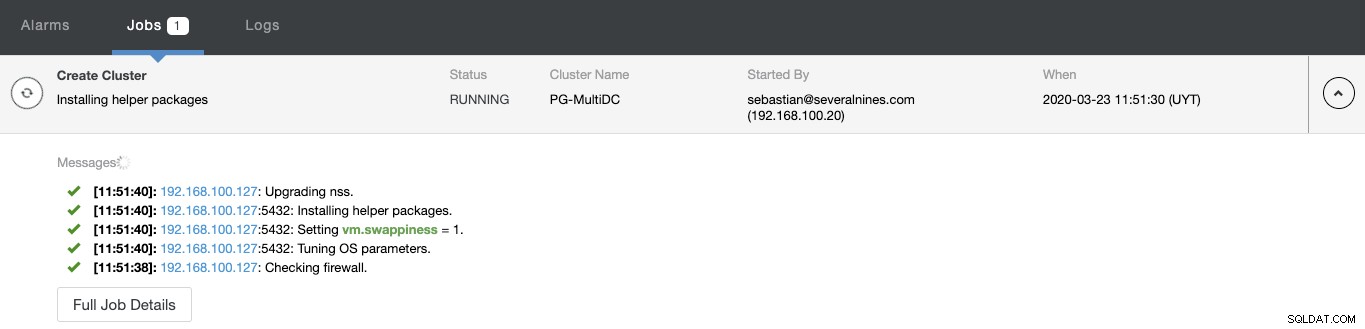
आप ClusterControl गतिविधि मॉनिटर से अपने नए क्लस्टर के निर्माण की स्थिति की निगरानी कर सकते हैं।
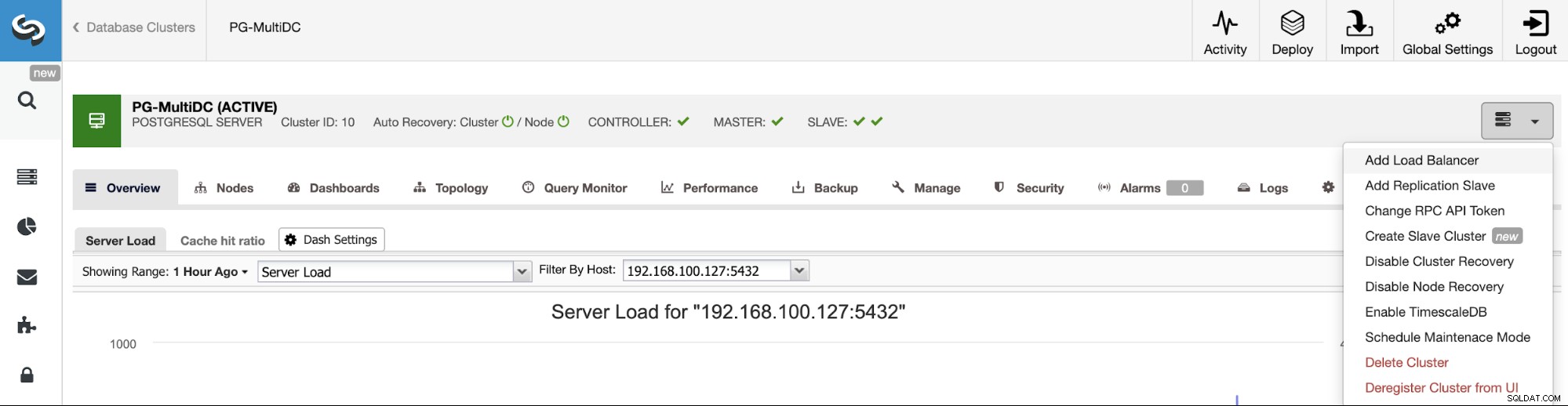
कार्य समाप्त होने के बाद, आप अपना नया PostgreSQL क्लस्टर देख सकते हैं मुख्य क्लस्टर नियंत्रण स्क्रीन।

एक PostgreSQL लोड बैलेंसर (HAProxy) जोड़ना
एक बार जब आप अपना क्लस्टर बना लेते हैं, तो आप उस पर कई कार्य कर सकते हैं, जैसे लोड बैलेंसर (HAProxy) या एक नई प्रतिकृति जोड़ना।
हमारे पिछले उदाहरण का अनुसरण करने के लिए, एक लोड बैलेंसर जोड़ें, जैसा कि हमने उल्लेख किया है, यह आपके HA वातावरण को प्रबंधित करने में आपकी सहायता करेगा। इसके लिए, ClusterControl पर जाएँ -> PostgreSQL क्लस्टर चुनें -> क्लस्टर क्रियाएँ -> लोड बैलेंसर जोड़ें।
यहां आपको वह जानकारी जोड़नी होगी जिसका उपयोग ClusterControl आपके इंस्टॉल और कॉन्फिगर करने के लिए करेगा। हैप्रोक्सी लोड बैलेंसर। यह लोड बैलेंसर उसी क्लस्टरकंट्रोल सर्वर में स्थापित किया जा सकता है, लेकिन यदि आप किसी भिन्न सर्वर का उपयोग कर सकते हैं, तो और भी बेहतर।
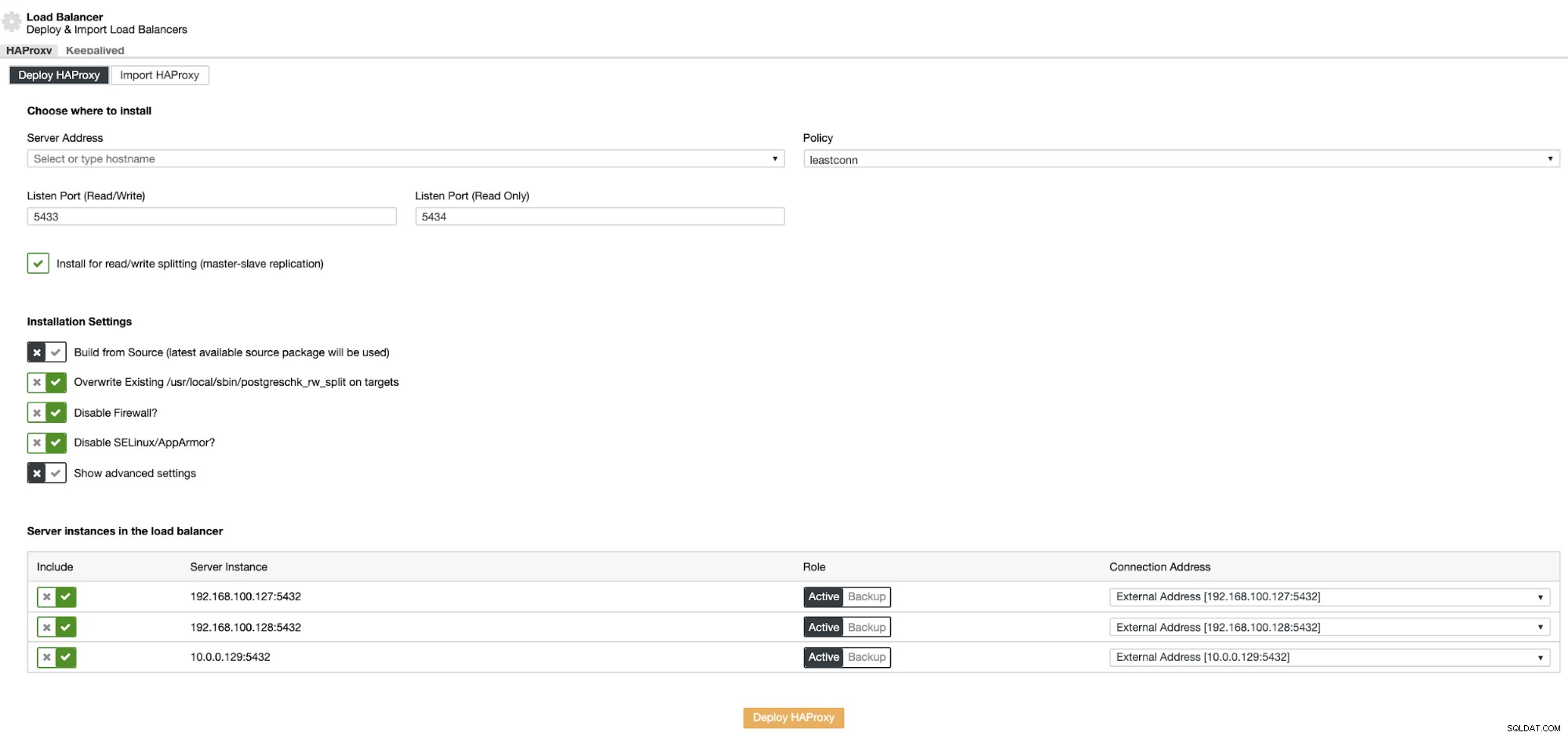
आपको जो जानकारी देनी है वह है:
कार्रवाई:परिनियोजित या आयात करें।
सर्वर पता:आपके HAProxy सर्वर के लिए IP पता (यह वही ClusterControl IP पता हो सकता है)।
सुनो पोर्ट (पढ़ें/लिखें):पठन/लेखन मोड के लिए पोर्ट।
सुनो पोर्ट (केवल पढ़ने के लिए):केवल पढ़ने के लिए पोर्ट।
नीति:यह हो सकती है:
- leastconn:सबसे कम कनेक्शन वाला सर्वर कनेक्शन प्राप्त करता है।
- राउंडरॉबिन:प्रत्येक सर्वर का उपयोग बारी-बारी से, उनके वजन के अनुसार किया जाता है।
- स्रोत:स्रोत आईपी पता हैश किया गया है और चल रहे सर्वर के कुल भार से विभाजित किया गया है ताकि यह निर्दिष्ट किया जा सके कि कौन सा सर्वर अनुरोध प्राप्त करेगा।
पढ़ने/लिखने के विभाजन के लिए स्थापित करें:मास्टर-दास प्रतिकृति के लिए।
बिल्ड फ्रॉम सोर्स:आप पैकेज मैनेजर से इंस्टॉल या सोर्स से बिल्ड चुन सकते हैं।
और आपको यह चुनना होगा कि आप HAProxy कॉन्फ़िगरेशन में कौन से सर्वर जोड़ना चाहते हैं।
इसके अलावा, आप व्यवस्थापक उपयोगकर्ता, बैकएंड नाम, टाइमआउट, और अधिक जैसी उन्नत सेटिंग्स कॉन्फ़िगर कर सकते हैं।
जब आप कॉन्फ़िगरेशन पूरा कर लें और परिनियोजन की पुष्टि करें, तो आप ClusterControl UI पर गतिविधि अनुभाग में प्रगति का अनुसरण कर सकते हैं।
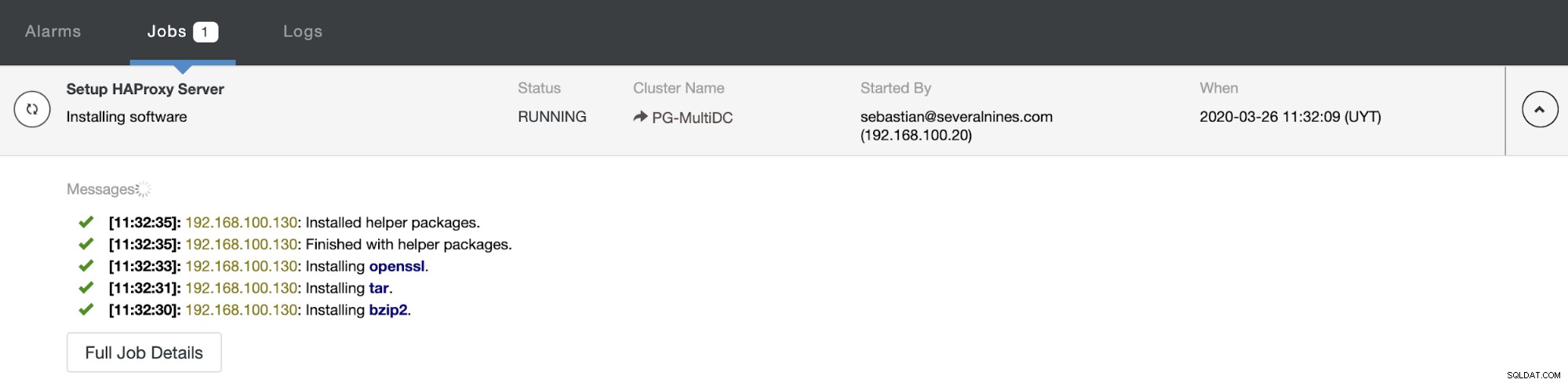
और जब यह पूरा हो जाए, तो आप ClusterControl -> Nodes -> पर जा सकते हैं HAProxy नोड, और वर्तमान स्थिति की जाँच करें।
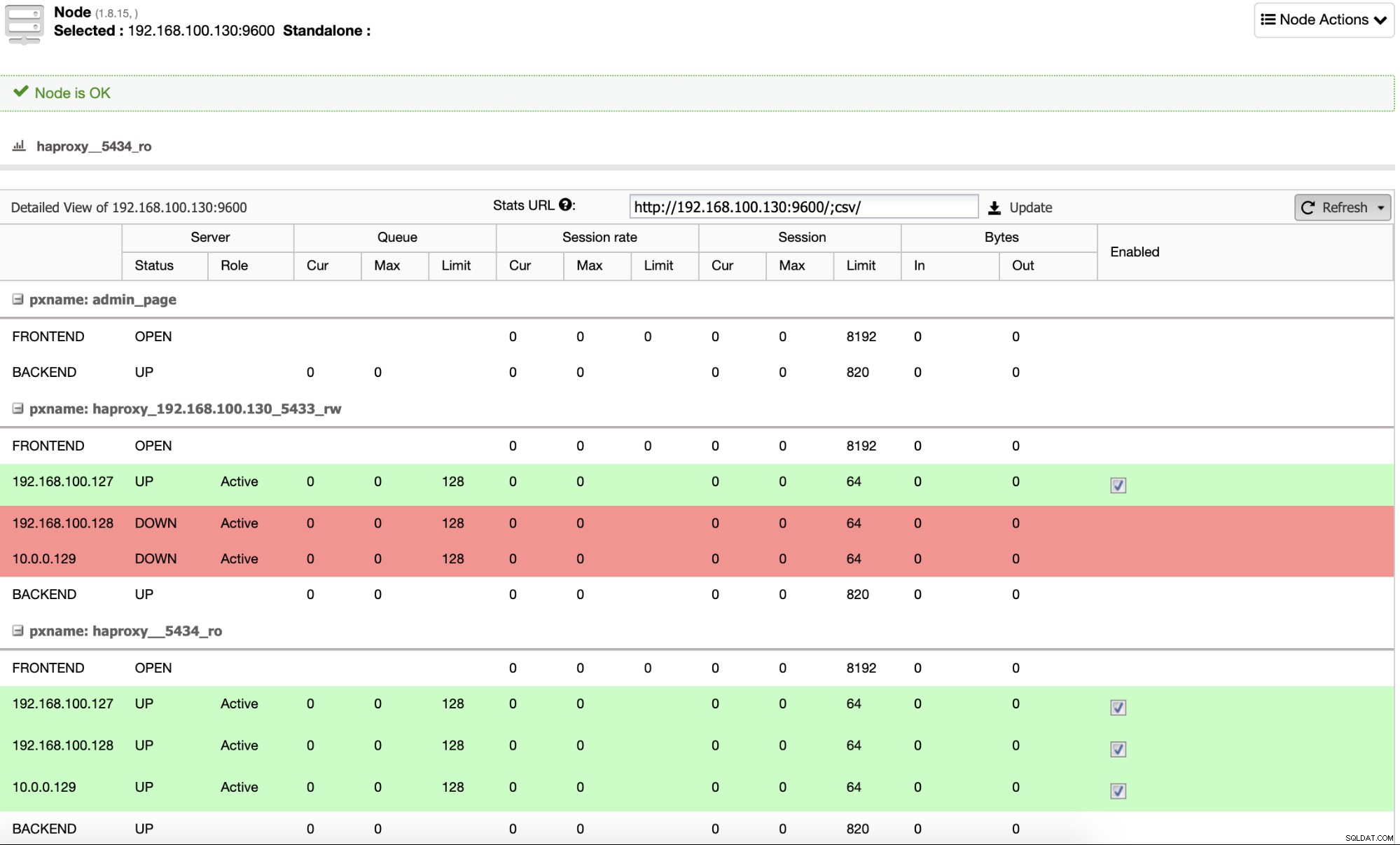
डिफ़ॉल्ट रूप से, ClusterControl HAProxy को दो अलग-अलग पोर्ट के साथ कॉन्फ़िगर करता है, एक रीड के लिए- लिखें, जिसका उपयोग एप्लिकेशन या उपयोगकर्ता के लिए डेटा लिखने (और पढ़ने) के लिए किया जाएगा, और दूसरा रीड-ओनली के लिए, जिसका उपयोग सभी नोड्स के बीच रीड ट्रैफ़िक को संतुलित करने के लिए किया जाएगा। रीड-राइट पोर्ट में, केवल मास्टर नोड सक्षम है, और मास्टर विफलता के मामले में, क्लस्टरकंट्रोल सबसे उन्नत दास को मास्टर करने के लिए बढ़ावा देगा और पुराने मास्टर को अक्षम करने और नए को सक्षम करने के लिए इस पोर्ट को फिर से कॉन्फ़िगर करेगा। इस तरह, आपका एप्लिकेशन अभी भी मास्टर डेटाबेस विफलता के मामले में काम कर सकता है, क्योंकि लोड बैलेंसर द्वारा ट्रैफ़िक को सही नोड पर रीडायरेक्ट किया जाता है।
आप अपने HAProxy सर्वरों को डैशबोर्ड अनुभाग में देख कर भी निगरानी कर सकते हैं।
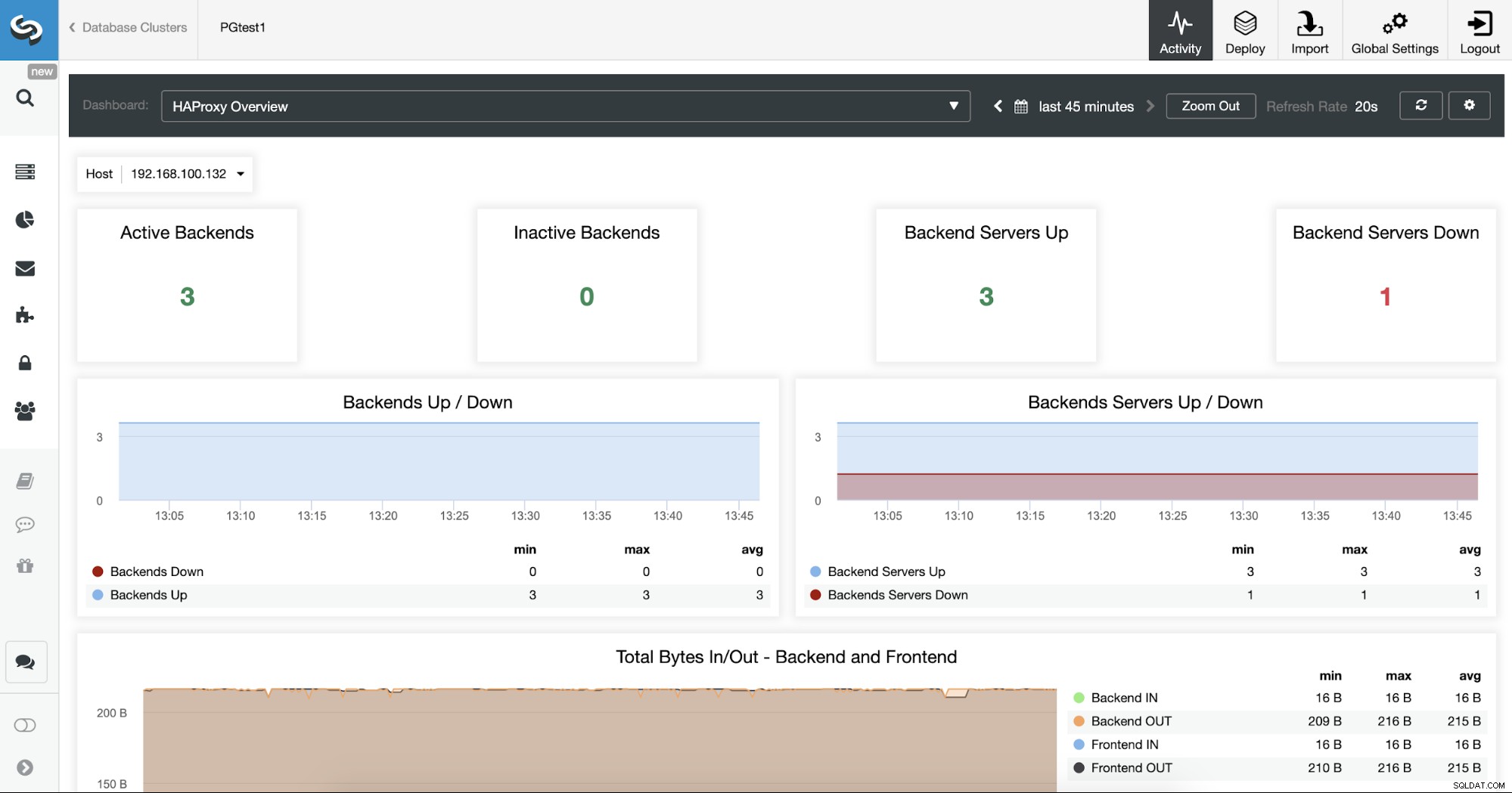
अब, आप अपने HA डिज़ाइन में एक नया HAProxy नोड जोड़कर सुधार कर सकते हैं। दूरस्थ डेटासेंटर और उनके बीच Keepalived सेवा को कॉन्फ़िगर करना। Keepalived आपको एक वर्चुअल आईपी एड्रेस का उपयोग करने की अनुमति देगा जो सक्रिय लोड बैलेंसर नोड को सौंपा गया है। यदि यह नोड विफल हो जाता है, तो यह वर्चुअल आईपी सेकेंडरी HAProxy नोड में माइग्रेट हो जाएगा, इसलिए आपके एप्लिकेशन में इस आईपी को कॉन्फ़िगर करने से आप लोड बैलेंसर समस्या के मामले में सब कुछ काम कर सकते हैं।
यह सभी कॉन्फ़िगरेशन ClusterControl का उपयोग करके निष्पादित किया जा सकता है।
निष्कर्ष
इस दो-भाग वाले ब्लॉग का अनुसरण करके आप एक वीपीएन कॉन्फ़िगरेशन की जटिलता से बचने के लिए डेटासेंटर के बीच उच्च उपलब्धता और एसएसएच कनेक्टिविटी के साथ पोस्टग्रेएसक्यूएल के लिए एक बहु-डेटासेंटर सेटअप लागू कर सकते हैं।
दूरस्थ नोड के लिए अतुल्यकालिक प्रतिकृति का उपयोग करके आप विलंबता और नेटवर्क प्रदर्शन से संबंधित किसी भी समस्या से बचेंगे, और ClusterControl का उपयोग करके विफलता के मामले में (अन्य कई विशेषताओं के बीच) आपके पास स्वचालित (या मैनुअल) विफलता होगी। यह इस टोपोलॉजी तक पहुंचने का सबसे आसान तरीका हो सकता है और हमें उम्मीद है कि यह आपके लिए उपयोगी होगा।