किसी भी डेटाबेस के लिए प्राथमिक आवश्यकताओं में से एक स्केलेबिलिटी हासिल करना है। यह केवल तभी प्राप्त किया जा सकता है जब विवाद (लॉकिंग) को जितना संभव हो कम से कम किया जाए, यदि सभी को एक साथ नहीं हटाया जाए। चूंकि डेटाबेस में होने वाले कुछ प्रमुख लगातार संचालन पढ़ने / लिखने / अद्यतन / हटाने के लिए होते हैं, इसलिए इन परिचालनों को अवरुद्ध किए बिना समवर्ती रूप से जारी रखना बहुत महत्वपूर्ण है। इसे प्राप्त करने के लिए, अधिकांश प्रमुख डेटाबेस बहु-संस्करण संगामिति नियंत्रण, नामक एक संगामिति मॉडल का उपयोग करते हैं। जो विवाद को न्यूनतम स्तर तक कम कर देता है।
एमवीसीसी क्या है
मल्टी वर्जन कंसुरेंसी कंट्रोल (यहां आगे एमवीसीसी) एक ही ऑब्जेक्ट के कई संस्करणों को बनाए रखने के द्वारा ठीक समवर्ती नियंत्रण प्रदान करने के लिए एक एल्गोरिदम है ताकि रीड और राइट ऑपरेशन संघर्ष न करें। यहाँ WRITE का अर्थ है UPDATE और DELETE, क्योंकि नए INSERTed रिकॉर्ड को वैसे भी आइसोलेशन स्तर के अनुसार संरक्षित किया जाएगा। प्रत्येक WRITE ऑपरेशन ऑब्जेक्ट का एक नया संस्करण तैयार करता है और प्रत्येक समवर्ती रीड ऑपरेशन आइसोलेशन स्तर के आधार पर ऑब्जेक्ट के एक अलग संस्करण को पढ़ता है। चूंकि दोनों एक ही ऑब्जेक्ट के विभिन्न संस्करणों पर काम करते हैं और लिखते हैं, इसलिए इनमें से किसी भी ऑपरेशन को पूरी तरह से लॉक करने की आवश्यकता नहीं है और इसलिए दोनों एक साथ काम कर सकते हैं। एकमात्र मामला जहां विवाद अभी भी मौजूद हो सकता है, जब दो समवर्ती लेनदेन एक ही रिकॉर्ड को लिखने का प्रयास करते हैं।
अधिकांश वर्तमान प्रमुख डेटाबेस एमवीसीसी का समर्थन करते हैं। इस एल्गोरिथ्म का इरादा एक ही वस्तु के कई संस्करणों को बनाए रखना है, इसलिए एमवीसीसी का कार्यान्वयन केवल डेटाबेस से डेटाबेस में भिन्न होता है कि कितने संस्करण बनाए और बनाए रखा जाता है। तदनुसार, संबंधित डेटाबेस संचालन और डेटा के संग्रहण में परिवर्तन होता है।
MVCC को लागू करने के लिए सबसे अधिक मान्यता प्राप्त दृष्टिकोण PostgreSQL और Firebird/Interbase द्वारा उपयोग किया जाता है और दूसरा InnoDB और Oracle द्वारा उपयोग किया जाता है। बाद के खंडों में, हम विस्तार से चर्चा करेंगे कि इसे PostgreSQL और InnoDB में कैसे लागू किया गया है।
एमवीसीसी पोस्टग्रेएसक्यूएल में
एकाधिक संस्करणों का समर्थन करने के लिए, PostgreSQL प्रत्येक ऑब्जेक्ट के लिए अतिरिक्त फ़ील्ड बनाए रखता है (PostgreSQL शब्दावली में Tuple) जैसा कि नीचे बताया गया है:
- xmin - टपल को डालने या अपडेट करने वाले लेन-देन की लेन-देन आईडी। अद्यतन के मामले में, इस लेनदेन आईडी के साथ टपल का एक नया संस्करण सौंपा जाता है।
- xmax - लेन-देन की लेन-देन आईडी जिसने टपल को हटा दिया या अपडेट किया। अद्यतन के मामले में, वर्तमान में टपल के मौजूदा संस्करण को यह लेनदेन आईडी सौंपा जाता है। नव निर्मित टपल पर, इस फ़ील्ड का डिफ़ॉल्ट मान शून्य होता है।
PostgreSQL सभी डेटा को प्राथमिक भंडारण में संग्रहीत करता है जिसे HEAP (डिफ़ॉल्ट आकार 8KB का पृष्ठ) कहा जाता है। सभी नए टपल को लेन-देन के रूप में xmin मिलता है जिसने इसे बनाया और पुराने संस्करण टपल (जो अपडेट या डिलीट हो गया) को xmax के साथ सौंपा गया। पुराने संस्करण से नए संस्करण के लिए हमेशा एक लिंक होता है। पुराने संस्करण टपल का उपयोग रोलबैक के मामले में टपल को फिर से बनाने के लिए किया जा सकता है और अलगाव स्तर के आधार पर रीड स्टेटमेंट द्वारा टपल के पुराने संस्करण को पढ़ने के लिए इस्तेमाल किया जा सकता है।
विचार करें कि तालिका के लिए दो टुपल्स हैं, T1 (मान 1 के साथ) और T2 (मान 2 के साथ), नई पंक्तियों का निर्माण नीचे 3 चरणों में प्रदर्शित किया जा सकता है:
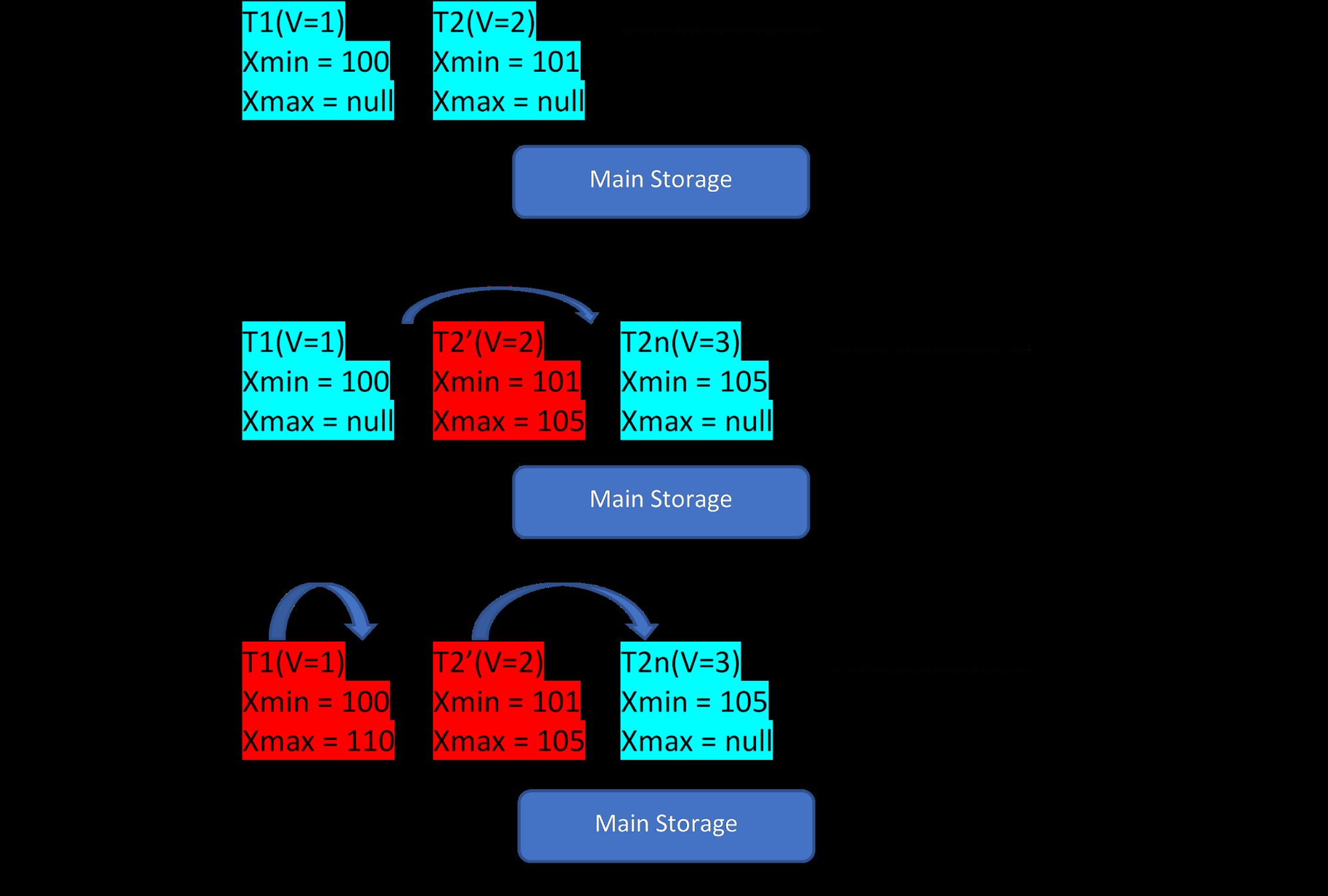 MVCC:PostgreSQL में कई संस्करणों का संग्रहण
MVCC:PostgreSQL में कई संस्करणों का संग्रहण जैसा कि चित्र से देखा जा सकता है, प्रारंभ में डेटाबेस में 1 और 2 मान वाले दो टुपल्स होते हैं।
फिर, दूसरे चरण के अनुसार, मूल्य 2 वाली पंक्ति T2 को 3 मान के साथ अद्यतन किया जाता है। इस बिंदु पर, नए मान के साथ एक नया संस्करण बनाया जाता है और यह उसी भंडारण क्षेत्र में मौजूदा टपल के बगल में संग्रहीत हो जाता है। . इससे पहले, पुराने संस्करण को xmax के साथ असाइन किया जाता है और नवीनतम संस्करण टपल को इंगित करता है।
इसी तरह, तीसरे चरण में, जब मान 1 वाली पंक्ति T1 हटा दी जाती है, तो, मौजूदा पंक्ति वस्तुतः उसी स्थान पर हटा दी जाती है (यानी यह वर्तमान लेनदेन के साथ xmax को असाइन किया गया है)। इसके लिए कोई नया संस्करण नहीं बनाया जाता है।
अगला, आइए देखें कि प्रत्येक ऑपरेशन कैसे कई संस्करण बनाता है और कैसे कुछ वास्तविक उदाहरणों के साथ लॉक किए बिना लेनदेन अलगाव स्तर बनाए रखा जाता है। नीचे दिए गए सभी उदाहरणों में डिफ़ॉल्ट रूप से "पढ़ें प्रतिबद्ध" अलगाव का उपयोग किया जाता है।
सम्मिलित करें
हर बार जब कोई रिकॉर्ड डाला जाता है, तो यह एक नया टपल बनाएगा, जो संबंधित तालिका से संबंधित पृष्ठों में से एक में जुड़ जाता है।
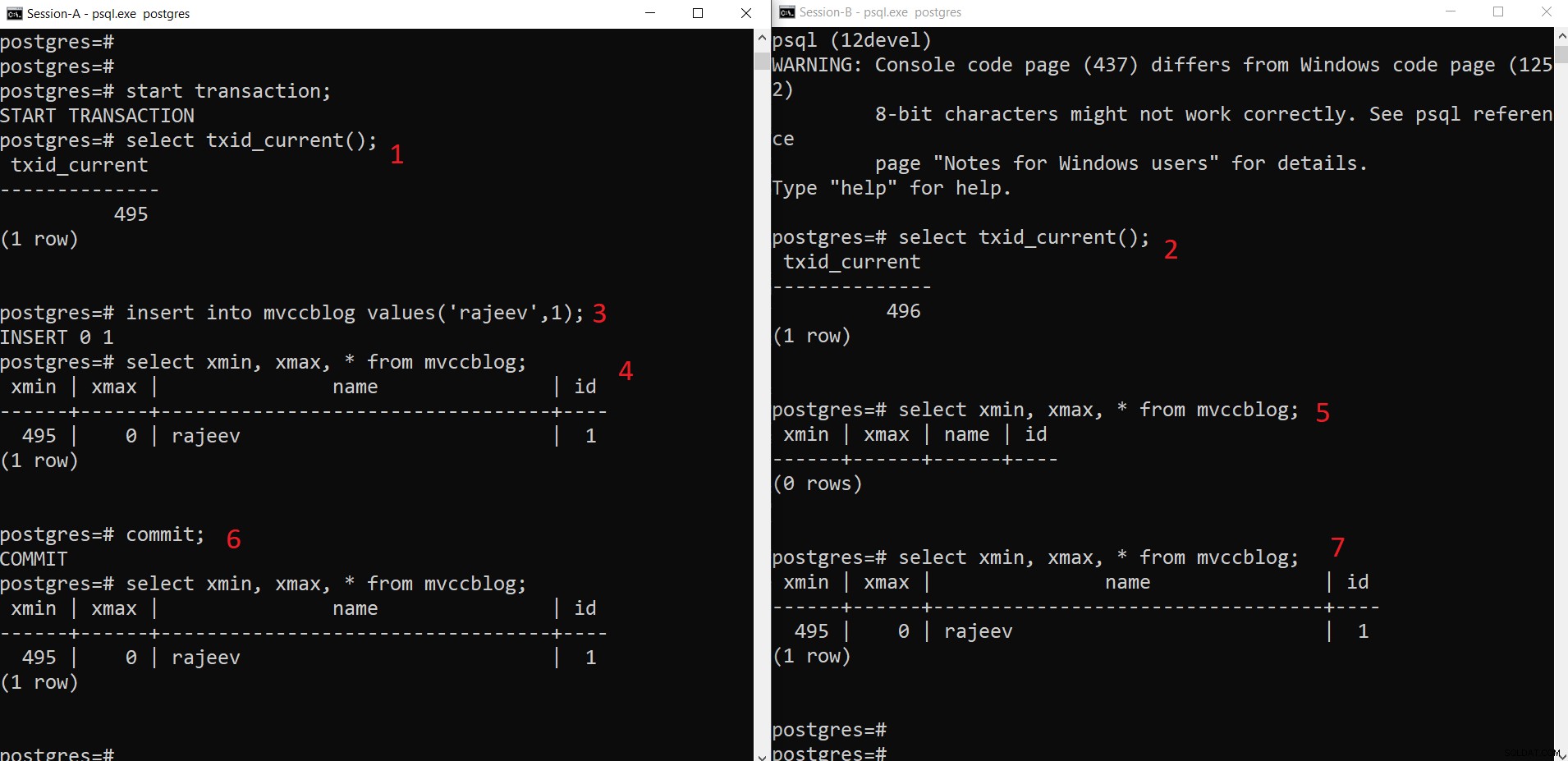 PostgreSQL समवर्ती INSERT ऑपरेशन
PostgreSQL समवर्ती INSERT ऑपरेशन जैसा कि हम यहां चरणबद्ध तरीके से देख सकते हैं:
- सत्र-ए एक लेनदेन शुरू करता है और लेनदेन आईडी 495 प्राप्त करता है।
- सत्र-बी एक लेनदेन शुरू करता है और लेनदेन आईडी 496 प्राप्त करता है।
- सत्र-ए एक नया टपल सम्मिलित करें (HEAP में संग्रहीत हो जाता है)
- अब, xmin के साथ नया टपल वर्तमान लेनदेन आईडी 495 पर सेट हो गया है।
- लेकिन सत्र-बी से वही दिखाई नहीं दे रहा है क्योंकि xmin (यानी 495) अभी भी प्रतिबद्ध नहीं है।
- एक बार प्रतिबद्ध।
- डेटा दोनों सत्रों के लिए दृश्यमान है।
अपडेट करें
PostgreSQL अद्यतन "इन-प्लेस" अपडेट नहीं है यानी यह मौजूदा ऑब्जेक्ट को आवश्यक नए मान के साथ संशोधित नहीं करता है। इसके बजाय, यह वस्तु का एक नया संस्करण बनाता है। तो, UPDATE में मोटे तौर पर नीचे दिए गए चरण शामिल हैं:
- यह वर्तमान वस्तु को हटाए गए के रूप में चिह्नित करता है।
- फिर यह वस्तु का एक नया संस्करण जोड़ता है।
- ऑब्जेक्ट के पुराने संस्करण को नए संस्करण पर रीडायरेक्ट करें।
इसलिए भले ही कई रिकॉर्ड समान रहते हों, HEAP जगह लेता है जैसे कि एक और रिकॉर्ड डाला गया हो।
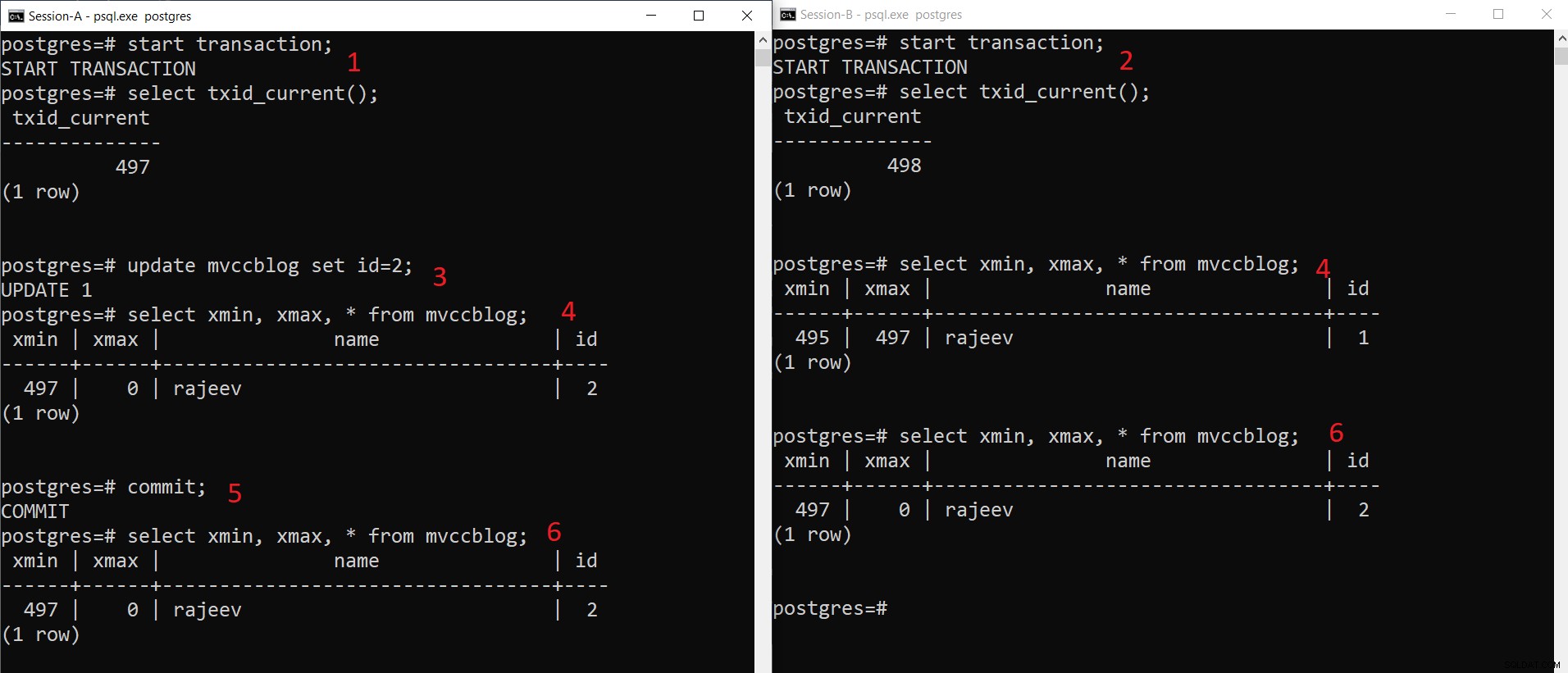 PostgreSQL समवर्ती INSERT ऑपरेशन
PostgreSQL समवर्ती INSERT ऑपरेशन जैसा कि हम यहां चरणबद्ध तरीके से देख सकते हैं:
- सत्र-ए एक लेनदेन शुरू करता है और लेनदेन आईडी 497 प्राप्त करता है।
- सत्र-बी एक लेनदेन शुरू करता है और लेनदेन आईडी 498 प्राप्त करता है।
- सत्र-ए मौजूदा रिकॉर्ड को अपडेट करता है।
- यहां सत्र-ए टपल का एक संस्करण देखता है (अपडेट किया गया टपल) जबकि सत्र-बी दूसरा संस्करण देखता है (पुराना टपल लेकिन xmax 497 पर सेट है)। दोनों टपल संस्करण HEAP स्टोरेज में स्टोर हो जाते हैं (यहां तक कि स्पेस की उपलब्धता के आधार पर एक ही पेज)
- एक बार जब सत्र-ए लेन-देन करता है, तो पुराने टपल की समय सीमा समाप्त हो जाती है क्योंकि पुराने टपल का xmax प्रतिबद्ध है।
- अब दोनों सत्रों में रिकॉर्ड का एक ही संस्करण दिखाई देता है।
हटाएं
डिलीट लगभग UPDATE ऑपरेशन की तरह है, सिवाय इसके कि इसमें नया वर्जन जोड़ने की जरूरत नहीं है। यह केवल वर्तमान वस्तु को UPDATE मामले में बताए अनुसार हटाए गए के रूप में चिह्नित करता है।
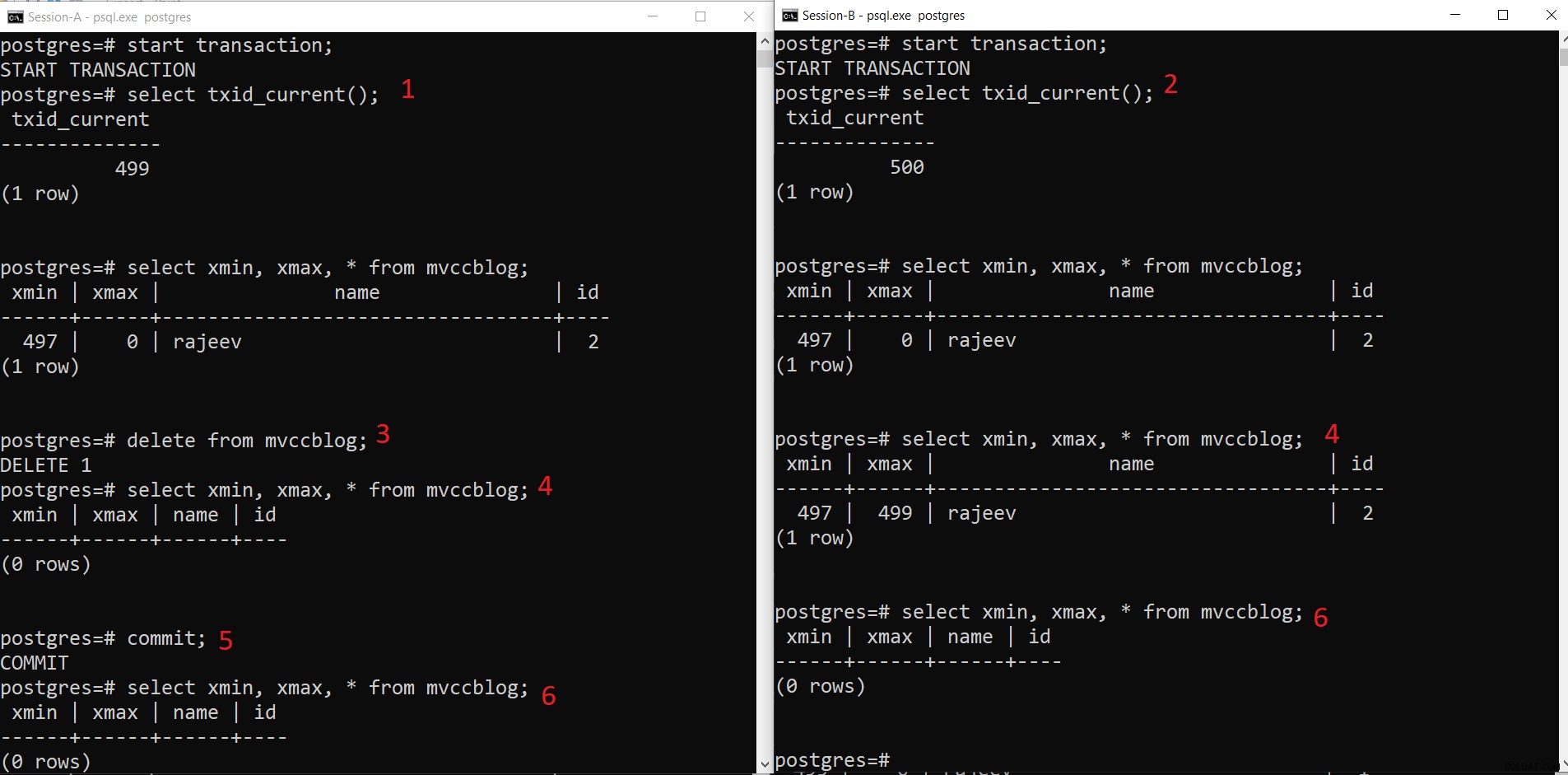 PostgreSQL समवर्ती DELETE ऑपरेशन
PostgreSQL समवर्ती DELETE ऑपरेशन - सत्र-ए एक लेनदेन शुरू करता है और लेनदेन आईडी 499 प्राप्त करता है।
- सत्र-बी एक लेनदेन शुरू करता है और लेनदेन आईडी 500 प्राप्त करता है।
- सत्र-ए मौजूदा रिकॉर्ड को हटा देता है।
- यहां सत्र-ए को वर्तमान लेनदेन से हटाए गए किसी भी टपल के रूप में नहीं दिखता है। जबकि सेशन-बी टुपल का एक पुराना संस्करण देखता है (xmax 499 के रूप में; लेन-देन जिसने इस रिकॉर्ड को हटा दिया)।
- एक बार जब सत्र-ए लेन-देन करता है, तो पुराने टपल की समय सीमा समाप्त हो जाती है क्योंकि पुराने टपल का xmax प्रतिबद्ध है।
- अब दोनों सत्रों में हटाए गए टपल नहीं दिखाई देते हैं।
जैसा कि हम देख सकते हैं, कोई भी ऑपरेशन वस्तु के मौजूदा संस्करण को सीधे नहीं हटाता है और जहाँ भी आवश्यकता होती है वह वस्तु का एक अतिरिक्त संस्करण जोड़ता है।
अब, देखते हैं कि एकाधिक संस्करणों वाले टपल पर सेलेक्ट क्वेरी कैसे निष्पादित होती है:सेलेक्ट को टपल के सभी संस्करणों को पढ़ने की जरूरत है जब तक कि यह आइसोलेशन स्तर के अनुसार उपयुक्त टपल नहीं पाता। मान लीजिए कि टपल T1 था, जो अपडेट हो गया और नया संस्करण T1 'बनाया और जिसने बदले में T1'' अपडेट पर बनाया:
- सिलेक्ट ऑपरेशन इस टेबल के लिए हीप स्टोरेज से होकर गुजरेगा और पहले T1 की जांच करें। यदि T1 xmax लेनदेन प्रतिबद्ध है, तो यह इस टपल के अगले संस्करण में चला जाता है।
- मान लीजिए कि अब T1' tuple xmax भी प्रतिबद्ध है, फिर यह इस टपल के अगले संस्करण में चला जाता है।
- अंत में, यह T1'' को ढूंढता है और देखता है कि xmax प्रतिबद्ध नहीं है (या शून्य) और T1'' xmin आइसोलेशन स्तर के अनुसार वर्तमान लेनदेन के लिए दृश्यमान है। अंत में, यह T1'' टपल को पढ़ेगा।
जैसा कि हम देख सकते हैं, कचरा संग्रहकर्ता (VACUUM) द्वारा समाप्त हो चुके टपल को हटाए जाने तक उपयुक्त दृश्यमान टपल को खोजने के लिए इसे टपल के सभी 3 संस्करणों के माध्यम से पार करने की आवश्यकता है।
MVCC InnoDB में
कई संस्करणों का समर्थन करने के लिए, InnoDB नीचे उल्लिखित प्रत्येक पंक्ति के लिए अतिरिक्त फ़ील्ड रखता है:
- DB_TRX_ID:लेन-देन की लेन-देन आईडी जिसने पंक्ति डाली या अपडेट की।
- DB_ROLL_PTR:इसे रोल पॉइंटर भी कहा जाता है और यह रोलबैक सेगमेंट में लिखे गए लॉग रिकॉर्ड को पूर्ववत करने की ओर इशारा करता है (इस पर और अधिक)।
PostgreSQL की तरह, InnoDB भी सभी ऑपरेशन के हिस्से के रूप में पंक्ति के कई संस्करण बनाता है लेकिन पुराने संस्करण का भंडारण अलग है।
InnoDB के मामले में, बदली हुई पंक्ति के पुराने संस्करण को एक अलग टेबलस्पेस/स्टोरेज (पूर्ववत खंड कहा जाता है) में रखा जाता है। इसलिए PostgreSQL के विपरीत, InnoDB मुख्य संग्रहण क्षेत्र में पंक्तियों का केवल नवीनतम संस्करण रखता है और पुराने संस्करण को पूर्ववत खंड में रखा जाता है। पूर्ववत खंड से पंक्ति संस्करणों का उपयोग रोलबैक के मामले में ऑपरेशन को पूर्ववत करने के लिए किया जाता है और अलगाव स्तर के आधार पर रीड स्टेटमेंट द्वारा पंक्तियों के पुराने संस्करण को पढ़ने के लिए उपयोग किया जाता है।
विचार करें कि तालिका के लिए दो पंक्तियाँ हैं, T1 (मान 1 के साथ) और T2 (मान 2 के साथ), नई पंक्तियों का निर्माण नीचे 3 चरणों में प्रदर्शित किया जा सकता है:
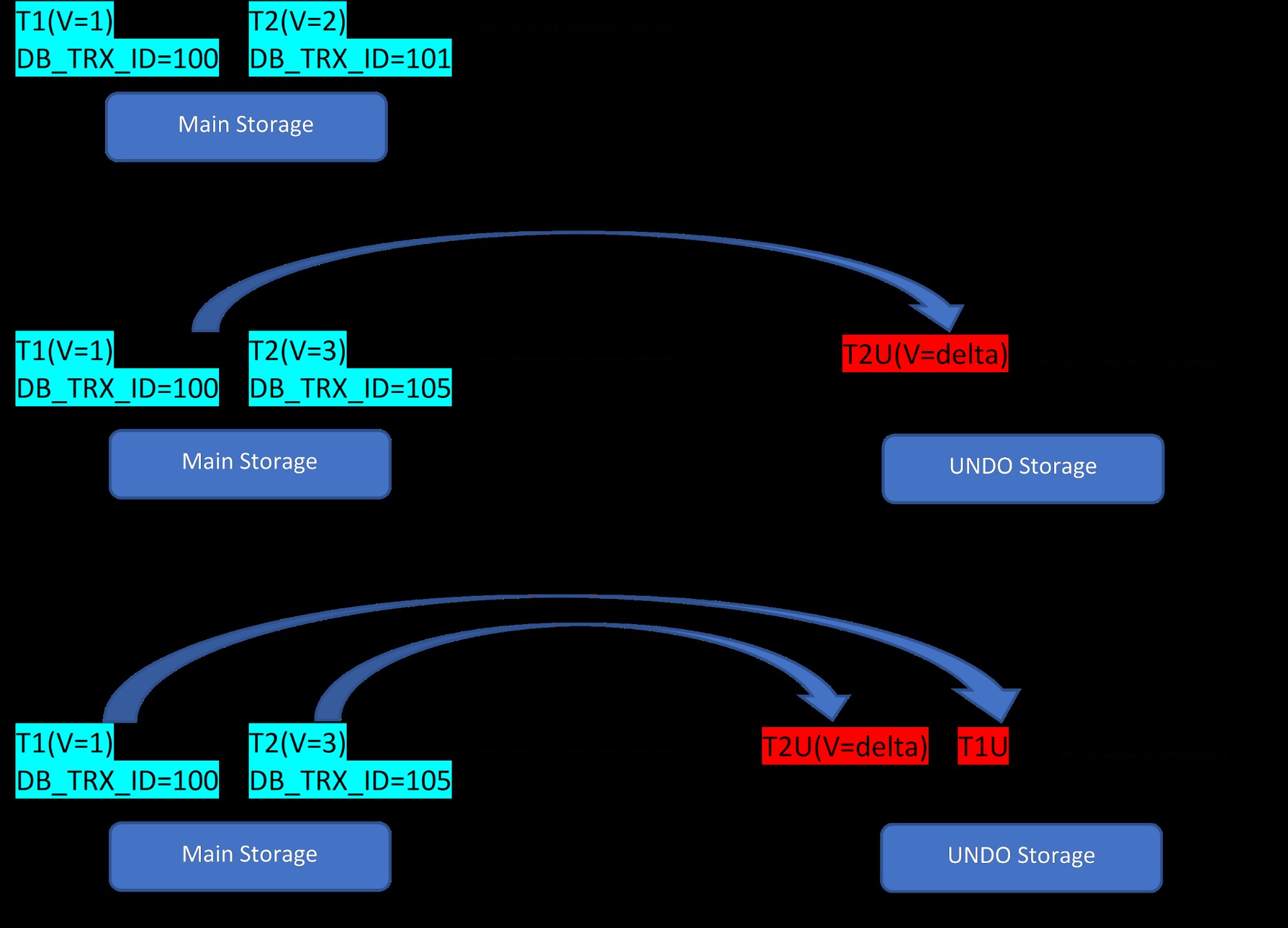 MVCC:InnoDB में कई संस्करणों का संग्रहण
MVCC:InnoDB में कई संस्करणों का संग्रहण जैसा कि चित्र से देखा जा सकता है, प्रारंभ में डेटाबेस में 1 और 2 मान वाली दो पंक्तियाँ होती हैं।
फिर दूसरे चरण के अनुसार, मान 2 वाली पंक्ति T2 को 3 मान के साथ अद्यतन किया जाता है। इस बिंदु पर, नए मान के साथ एक नया संस्करण बनाया जाता है और यह पुराने संस्करण को बदल देता है। इससे पहले, पुराना संस्करण पूर्ववत खंड में संग्रहीत हो जाता है (ध्यान दें कि UNDO खंड संस्करण में केवल एक डेल्टा मान है)। साथ ही, ध्यान दें कि रोलबैक सेगमेंट में नए संस्करण से पुराने संस्करण में एक पॉइंटर है। इसलिए PostgreSQL के विपरीत, InnoDB अपडेट "इन-प्लेस" है।
इसी तरह, तीसरे चरण में, जब मान 1 के साथ पंक्ति T1 हटा दी जाती है, तो मौजूदा पंक्ति मुख्य भंडारण क्षेत्र में वस्तुतः हटा दी जाती है (अर्थात यह पंक्ति में एक विशेष बिट को चिह्नित करती है) और इससे संबंधित एक नया संस्करण इसमें जोड़ा जाता है पूर्ववत करें खंड। फिर से, मुख्य भंडारण से पूर्ववत खंड में एक रोल पॉइंटर होता है।
सभी ऑपरेशन उसी तरह से व्यवहार करते हैं जैसे पोस्टग्रेएसक्यूएल के मामले में जब बाहर से देखा जाता है। एकाधिक संस्करणों का बस आंतरिक संग्रहण भिन्न होता है।
आज श्वेतपत्र डाउनलोड करें क्लस्टरकंट्रोल के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, मॉनिटर करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंMVCC:PostgreSQL बनाम InnoDB
अब, विश्लेषण करते हैं कि उनके MVCC कार्यान्वयन के संदर्भ में PostgreSQL और InnoDB के बीच प्रमुख अंतर क्या हैं:
-
पुराने संस्करण का आकार
PostgreSQL सिर्फ टपल के पुराने संस्करण पर xmax को अपडेट करता है, इसलिए पुराने संस्करण का आकार संबंधित सम्मिलित रिकॉर्ड के समान रहता है। इसका मतलब है कि यदि आपके पास पुराने टपल के 3 संस्करण हैं तो उन सभी का आकार समान होगा (प्रत्येक अपडेट में वास्तविक डेटा आकार में अंतर को छोड़कर)।
जबकि InnoDB के मामले में, पूर्ववत खंड में संग्रहीत ऑब्जेक्ट संस्करण आमतौर पर संबंधित सम्मिलित रिकॉर्ड से छोटा होता है। ऐसा इसलिए है क्योंकि UNDO लॉग में केवल बदले हुए मान (अर्थात अंतर) लिखे जाते हैं।
-
इन्सर्ट ऑपरेशन
InnoDB को INSERT के लिए भी UNDO सेगमेंट में एक अतिरिक्त रिकॉर्ड लिखने की आवश्यकता है जबकि PostgreSQL केवल UPDATE के मामले में नया संस्करण बनाता है।
-
रोलबैक के मामले में पुराने संस्करण को पुनर्स्थापित करना
रोलबैक के मामले में पुराने संस्करण को पुनर्स्थापित करने के लिए PostgreSQL को कुछ विशिष्ट करने की आवश्यकता नहीं है। याद रखें कि पुराने संस्करण में लेन-देन के बराबर xmax है जिसने इस टपल को अपडेट किया है। इसलिए, जब तक यह लेनदेन आईडी प्रतिबद्ध नहीं हो जाती, तब तक इसे समवर्ती स्नैपशॉट के लिए जीवित टपल माना जाता है। एक बार लेन-देन के रोलबैक हो जाने के बाद, संबंधित लेनदेन को सभी लेनदेन के लिए स्वचालित रूप से जीवित माना जाएगा क्योंकि यह एक निरस्त लेनदेन होगा।
जबकि InnoDB के मामले में, रोलबैक होने पर ऑब्जेक्ट के पुराने संस्करण को फिर से बनाना स्पष्ट रूप से आवश्यक है।
-
पुराने संस्करण द्वारा कब्जा किए गए स्थान को पुनः प्राप्त करना
PostgreSQL के मामले में, पुराने संस्करण के कब्जे वाले स्थान को केवल तभी मृत माना जा सकता है जब इस संस्करण को पढ़ने के लिए समानांतर स्नैपशॉट न हो। एक बार पुराना संस्करण समाप्त हो जाने के बाद, VACUUM ऑपरेशन उनके द्वारा कब्जा किए गए स्थान को पुनः प्राप्त कर सकता है। कॉन्फ़िगरेशन के आधार पर VACUUM को मैन्युअल रूप से या पृष्ठभूमि कार्य के रूप में ट्रिगर किया जा सकता है।
InnoDB UNDO लॉग मुख्य रूप से INSERT UNDO और UPDATE UNDO में विभाजित हैं। जैसे ही संबंधित लेन-देन होता है, पहले वाले को छोड़ दिया जाता है। दूसरे को तब तक संरक्षित करने की आवश्यकता है जब तक कि यह किसी अन्य स्नैपशॉट के समानांतर न हो। InnoDB में स्पष्ट VACUUM ऑपरेशन नहीं है, लेकिन एक समान लाइन पर इसमें UNDO लॉग को त्यागने के लिए अतुल्यकालिक PURGE है जो पृष्ठभूमि कार्य के रूप में चलता है।
-
विलंबित निर्वात का प्रभाव
जैसा कि पिछले बिंदु में चर्चा की गई है, PostgreSQL के मामले में विलंबित वैक्यूम का बहुत बड़ा प्रभाव है। इससे तालिका फूलने लगती है और रिकॉर्ड लगातार हटाए जाने के बावजूद भंडारण स्थान में वृद्धि होती है। यह एक ऐसे बिंदु पर भी पहुंच सकता है जहां VACUUM FULL करने की आवश्यकता होती है जो कि बहुत महंगा ऑपरेशन है।
-
सूजन तालिका के मामले में अनुक्रमिक स्कैन
पोस्टग्रेएसक्यूएल अनुक्रमिक स्कैन को किसी ऑब्जेक्ट के सभी पुराने संस्करण से गुजरना चाहिए, भले ही वे सभी मर चुके हों (जब तक वे वैक्यूम का उपयोग करके हटा दिए जाते हैं)। PostgreSQL में यह विशिष्ट और सबसे चर्चित समस्या है। याद रखें कि PostgreSQL एक ही स्टोरेज में टपल के सभी वर्जन को स्टोर करता है।
जबकि InnoDB के मामले में, जब तक इसकी आवश्यकता न हो, इसे पूर्ववत रिकॉर्ड पढ़ने की आवश्यकता नहीं है। यदि सभी पूर्ववत रिकॉर्ड मर जाते हैं, तो यह केवल वस्तुओं के सभी नवीनतम संस्करण को पढ़ने के लिए पर्याप्त होगा।
-
सूचकांक
PostgreSQL इंडेक्स को एक अलग स्टोरेज में स्टोर करता है जो HEAP में वास्तविक डेटा के लिए एक लिंक रखता है। इसलिए PostgreSQL को INDEX भाग को भी अपडेट करना होगा, भले ही INDEX में कोई बदलाव न हुआ हो। हालाँकि बाद में इस समस्या को HOT (हीप ओनली टुपल) अपडेट को लागू करके ठीक किया गया था, लेकिन फिर भी इसकी सीमा है कि यदि एक ही पृष्ठ में एक नया हीप टपल समायोजित नहीं किया जा सकता है, तो यह सामान्य अद्यतन पर वापस आ जाता है।
InnoDB को यह समस्या नहीं है क्योंकि वे संकुल अनुक्रमणिका का उपयोग करते हैं।
निष्कर्ष
PostgreSQL MVCC में विशेष रूप से फूला हुआ भंडारण के मामले में कुछ कमियां हैं यदि आपके कार्यभार में बार-बार अद्यतन/हटाएं हैं। इसलिए यदि आप PostgreSQL का उपयोग करने का निर्णय लेते हैं तो आपको VACUUM को बुद्धिमानी से कॉन्फ़िगर करने में बहुत सावधानी बरतनी चाहिए।
PostgreSQL समुदाय ने भी इसे एक प्रमुख मुद्दे के रूप में स्वीकार किया है और उन्होंने पहले ही UNDO आधारित MVCC दृष्टिकोण (ZHEAP के रूप में अस्थायी नाम) पर काम करना शुरू कर दिया है और हम इसे भविष्य के रिलीज में देख सकते हैं।