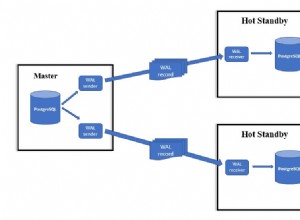
AWS PostgreSQL सेवाएं RDS छत्र के अंतर्गत आती हैं, जो सभी ज्ञात डेटाबेस इंजनों के लिए Amazon की DaaS पेशकश है।
प्रबंधित डेटाबेस सेवाएं कुछ ऐसे लाभ प्रदान करती हैं जो बुनियादी ढांचे के रखरखाव और अत्यधिक उपलब्ध कॉन्फ़िगरेशन से स्वतंत्रता चाहने वाले ग्राहक को आकर्षित कर रहे हैं। हमेशा की तरह, सभी समाधान के लिए एक आकार फिट नहीं है। वर्तमान में उपलब्ध विकल्पों को नीचे हाइलाइट किया गया है:
Aurora PostgreSQL
Amazon Aurora FAQ पृष्ठ महत्वपूर्ण विवरण प्रदान करता है जिन पर उत्पाद में गोता लगाने से पहले विचार करने की आवश्यकता होती है। उदाहरण के लिए, हम सीखते हैं कि स्टोरेज लेयर वर्चुअलाइज्ड है और एसएसडी द्वारा समर्थित एक मालिकाना वर्चुअलाइज्ड स्टोरेज सिस्टम पर बैठता है।
कीमत
मूल्य निर्धारण के संदर्भ में, यह ध्यान दिया जाना चाहिए कि AWS फ्री टियर में Aurora PostgreSQL उपलब्ध नहीं है।
संगतता
वही FAQ पृष्ठ यह स्पष्ट करता है कि Amazon 100% PostgreSQL संगतता का दावा नहीं करता है। अधिकांश (मेरा जोर) आवेदनों का ठीक रहेगा, उदा। AWS PostgreSQL फ्लेवर वायर-संगत है PostgreSQL 9.6 के साथ। परिणामस्वरूप, Wireshark PostgreSQL Dissector ठीक काम करेगा।
प्रदर्शन
प्रदर्शन भी इंस्टेंस प्रकार से जुड़ा होता है, उदाहरण के लिए कनेक्शन की अधिकतम संख्या डिफ़ॉल्ट रूप से इंस्टेंस आकार के आधार पर कॉन्फ़िगर की जाती है।
जब संगतता की बात आती है तो यह भी महत्वपूर्ण है कि पृष्ठ का आकार 8KiB पर रखा गया है जो कि PostgreSQL डिफ़ॉल्ट पृष्ठ आकार है। पृष्ठों की बात करें तो यह अक्सर पूछे जाने वाले प्रश्नों को उद्धृत करने योग्य है:"पारंपरिक डेटाबेस इंजनों के विपरीत Amazon Aurora कभी भी संशोधित डेटाबेस पृष्ठों को स्टोरेज लेयर पर नहीं धकेलता है, जिसके परिणामस्वरूप IO खपत बचत होती है। यह इसलिए संभव हुआ है क्योंकि अमेज़ॅन ने पेज कैश को प्रबंधित करने के तरीके को बदल दिया है, जिससे डेटाबेस की विफलता के मामले में यह मेमोरी में बना रहता है। यह सुविधा क्रैश के बाद डेटाबेस को फिर से शुरू करने में भी लाभ देती है, जिससे पुनर्प्राप्ति लॉग को फिर से चलाने की पारंपरिक विधि की तुलना में बहुत तेज़ी से हो सकती है।
ऊपर दिए गए अक्सर पूछे जाने वाले प्रश्नों के अनुसार, Aurora PostgreSQL पोस्टग्रेएसक्यूएल के प्रदर्शन का तीन गुना डिलीवर करता है चयन और अद्यतन संचालन पर। अमेज़ॅन के पोस्टग्रेएसक्यूएल बेंचमार्क श्वेत पत्र के अनुसार प्रदर्शन को मापने के लिए उपयोग किए जाने वाले उपकरण पीजीबेंच और सिसबेंच थे। उदाहरण प्रकार, क्षेत्र चयन और नेटवर्क प्रदर्शन पर प्रदर्शन निर्भरता उल्लेखनीय है। आश्चर्य है कि INSERT का उल्लेख क्यों नहीं किया गया? ऐसा इसलिए है क्योंकि PostgreSQL ACID अनुपालन ("C") के लिए आवश्यक है कि एक अपडेट के बाद एक इंसर्ट के बाद डिलीट का उपयोग करके एक अपडेटेड रिकॉर्ड बनाया जाए।
प्रदर्शन में सुधार का पूरा लाभ उठाने के लिए, अमेज़ॅन अनुशंसा करता है कि अनुप्रयोगों को समवर्ती प्रश्नों और लेनदेन की बड़ी संख्या का उपयोग करके डेटाबेस के साथ बातचीत करने के लिए डिज़ाइन किया गया है। . इस महत्वपूर्ण कारक को अक्सर अनदेखा कर दिया जाता है, जिसके कारण कार्यान्वयन पर दोषारोपण खराब प्रदर्शन होता है।
सीमाएं
प्रवास की योजना बनाते समय कुछ सीमाओं पर विचार किया जाना चाहिए:
-
विशाल_पृष्ठों को संशोधित नहीं किया जा सकता, हालांकि यह डिफ़ॉल्ट रूप से चालू रहता है:
template1=> select aurora_version(); aurora_version ---------------- 1.0.11 (1 row) template1=> show huge_pages ; huge_pages ------------ on (1 row) - pg_hba का उपयोग नहीं किया जा सकता क्योंकि इसके लिए सर्वर पुनरारंभ की आवश्यकता होती है। एक साइड नोट के रूप में, यह अमेज़ॅन के दस्तावेज़ीकरण में एक टाइपो होना चाहिए, क्योंकि PostgreSQL को केवल पुनः लोड करने की आवश्यकता है। pg_hba पर निर्भर होने के बजाय, व्यवस्थापकों को AWS सुरक्षा समूह और PostgreSQL GRANT का उपयोग करने की आवश्यकता होगी।
- PITR विवरण 5 मिनट है।
- वर्तमान में PostgreSQL के लिए क्रॉस-रीजन प्रतिकृति उपलब्ध नहीं है।
- टेबल का अधिकतम आकार 64TiB है
- अधिकतम 15 प्रतिकृतियां पढ़ें
मापनीयता
डेटाबेस इंस्टेंस को ऊपर और नीचे स्केल करना वर्तमान में एक मैन्युअल प्रक्रिया है, जिसे एडब्ल्यूएस कंसोल या सीएलआई के माध्यम से किया जा सकता है, हालांकि स्वचालित स्केलिंग काम में है, हालांकि, अमेज़ॅन ऑरोरा एफएक्यू के अनुसार यह केवल MySQL के लिए उपलब्ध होगा।
 इवेंट लॉग स्केलिंग कंप्यूटिंग संसाधन
इवेंट लॉग स्केलिंग कंप्यूटिंग संसाधन क्षैतिज रूप से स्केल करने के लिए अनुप्रयोगों को एडब्ल्यूएस एसडीके एपीआई का लाभ उठाना चाहिए, उदाहरण के लिए तेजी से विफलता प्राप्त करने के लिए।
उच्च उपलब्धता
उच्च उपलब्धता की ओर बढ़ते हुए, प्राथमिक नोड विफलता के मामले में, Aurora PostgreSQL एक DNS A रिकॉर्ड के रूप में एक क्लस्टर समापन बिंदु प्रदान करता है, जो मास्टर बनने के लिए चयनित प्रतिकृति को इंगित करने के लिए स्वचालित रूप से आंतरिक रूप से अद्यतन किया जाता है।
बैकअप
उल्लेखनीय है कि यदि डेटाबेस हटा दिया जाता है, तो कोई भी मैन्युअल बैकअप स्नैपशॉट रखा जाएगा, जबकि स्वचालित स्नैपशॉट हटा दिए जाएंगे।
प्रतिकृति
चूंकि प्रतिकृतियां प्राथमिक उदाहरण के समान अंतर्निहित भंडारण साझा करती हैं, इसलिए प्रतिकृति अंतराल, सैद्धांतिक रूप से, मिलीसेकंड की सीमा में है।
विफलता अवधि को कम करने के लिए अमेज़ॅन पढ़ने की प्रतिकृतियों की अनुशंसा करता है। स्टैंडबाय पर एक पठन प्रतिकृति के साथ विफलता प्रक्रिया में लगभग 30 सेकंड लगते हैं, जबकि प्रतिकृति के बिना 15 मिनट तक की अपेक्षा की जाती है।
अन्य अच्छी खबर यह है कि तार्किक प्रतिकृति भी समर्थित है, जैसा कि पृष्ठ 22 पर दिखाया गया है।
हालाँकि Amazon Aurora FAQ प्रतिकृति पर विवरण प्रदान नहीं करता है जैसा कि यह MySQL के लिए करता है, Aurora PostgreSQL सर्वोत्तम अभ्यास प्रतिकृति स्थिति को सत्यापित करने के लिए एक उपयोगी क्वेरी प्रदान करता है:
select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp from
aurora_replica_status();उपरोक्त क्वेरी उत्पन्न करती है:
-[ RECORD 1 ]--------------+-------------------------------------
server_id | testdb
session_id | 9e268c62-9392-11e8-87fc-a926fa8340fe
highest_lsn_rcvd | 46640889
cur_replay_latency_in_usec | 8830
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:54-07
-[ RECORD 2 ]--------------+-------------------------------------
server_id | testdb-us-east-1b
session_id | MASTER_SESSION_ID
highest_lsn_rcvd |
cur_replay_latency_in_usec |
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:55-07चूंकि प्रतिकृति इतना महत्वपूर्ण विषय है, इसलिए यह pgbench परीक्षण स्थापित करने के लायक था जैसा कि ऊपर संदर्भित बेंचमार्क श्वेत पत्र में उल्लिखित है:
[example@sqldat.com ~]$ whoami
ec2-user
[example@sqldat.com ~]$ tail -n 2 .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
export PATH=$PATH:/usr/local/pgsql/bin/
[example@sqldat.com ~]$ which pgbench
/usr/local/pgsql/bin/pgbench
[example@sqldat.com ~]$ pgbench --version
pgbench (PostgreSQL) 9.6.8संकेत: एक pgpass फ़ाइल बनाकर और होस्ट, डेटाबेस, और उपयोगकर्ता पर्यावरण चर जैसे निर्यात करके अनावश्यक टाइपिंग से बचें:
[example@sqldat.com ~]# tail -n 3 ~/.bashrc export
PGUSER=dbadmin
export PGHOST=c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGDATABASE=template1
[example@sqldat.com ~]# cat ~/.pgpass
*:*:*:dbadmin:passwordडेटा इनिशियलाइज़ेशन कमांड चलाएँ:
[example@sqldat.com ~]$ pgbench -i --fillfactor=90 --scale=10000 postgresजब डेटा इनिशियलाइज़ेशन चल रहा हो, तो निम्न स्क्रिप्ट के भीतर से कॉल किए गए उपरोक्त SQL का उपयोग करके प्रतिकृति लैग को कैप्चर करें:
while : ; do
psql -t -q \
-c 'select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp
from aurora_replica_status();' postgres
sleep 1
doneनिम्न कमांड के माध्यम से स्क्रीनलॉग आउटपुट को फ़िल्टर करना:
[example@sqldat.com ~]# awk -F '|' '{print $4,$5,$6}' screenlog.2 | sort -k1,1 -n | tail
513116 2018-07-30 04:30:44.394729+00 2018-07-30 04:30:43+00
529294 2018-07-30 04:20:54.261741+00 2018-07-30 04:20:53+00
544139 2018-07-30 04:41:57.538566+00 2018-07-30 04:41:57+00
1001902 2018-07-30 04:42:54.80136+00 2018-07-30 04:42:53+00
2376951 2018-07-30 04:38:06.621681+00 2018-07-30 04:38:06+00
2376951 2018-07-30 04:38:07.672919+00 2018-07-30 04:38:07+00
5365719 2018-07-30 04:36:51.608983+00 2018-07-30 04:36:50+00
5365719 2018-07-30 04:36:52.912731+00 2018-07-30 04:36:51+00
6308586 2018-07-30 04:45:22.951966+00 2018-07-30 04:45:21+00
8210986 2018-07-30 04:46:14.575385+00 2018-07-30 04:46:13+00यह पता चला है कि प्रतिकृति 8 सेकंड तक पिछड़ गई!
संबंधित नोट पर, AWS CloudWatch मीट्रिक AuroraReplicaLagMaximum उपरोक्त SQL कमांड के परिणामों से सहमत नहीं है। मैं जानना चाहता हूं क्यों, इसलिए प्रतिक्रिया की अत्यधिक सराहना की जाती है।
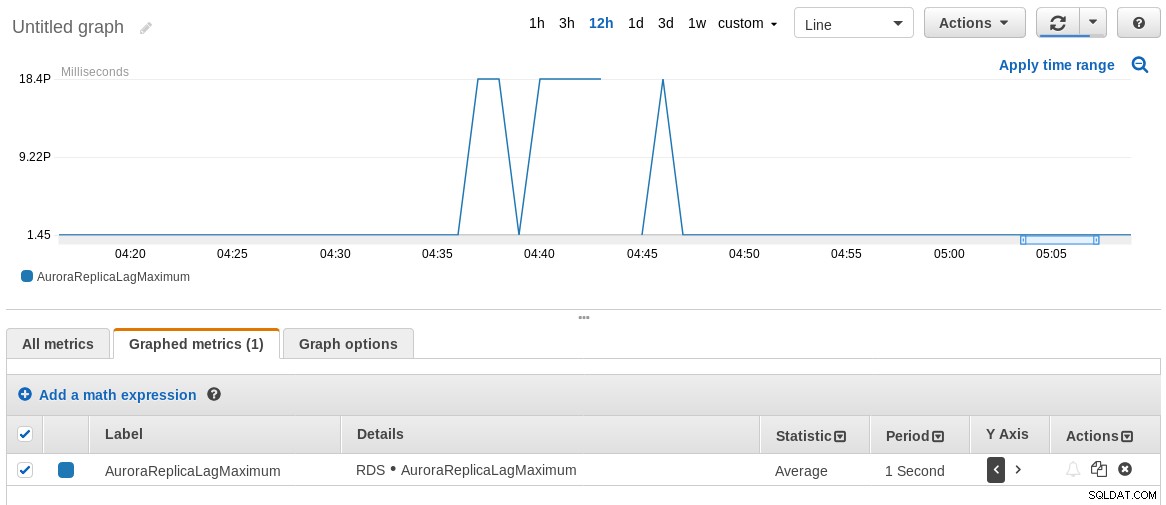 RDS CloudWatch मैक्स रेप्लिका लैग ग्राफ
RDS CloudWatch मैक्स रेप्लिका लैग ग्राफ सुरक्षा
-
एन्क्रिप्शन उपलब्ध है और डेटाबेस बनाते समय इसे सक्षम किया जाना चाहिए, क्योंकि इसे बाद में बदला नहीं जा सकता है।
समस्या निवारण
यह छोटा खंड एक महत्वपूर्ण बिट है सुनिश्चित करें कि PostgreSQL work_mem उचित रूप से ट्यून किया गया है ताकि सॉर्टिंग ऑपरेशन डिस्क पर डेटा न लिखें।
सेटअप
एडब्ल्यूएस कंसोल में बस सेटअप विज़ार्ड का पालन करें:
-
अमेज़ॅन आरडीएसखोलें प्रबंधन कंसोल।
 RDS प्रबंधन कंसोल
RDS प्रबंधन कंसोल -
अमेज़ॅन औरोरा चुनें और PostgreSQL संस्करण।
 Aurora PostgreSQL विज़ार्ड
Aurora PostgreSQL विज़ार्ड -
DB विवरण निर्दिष्ट करें और Aurora PostgreSQL पासवर्ड सीमाओं पर ध्यान दें:
Master Password must be at least eight characters long, as in "mypassword". Can be any printable ASCII character except "/", """, or "@". Aurora PostgreSQL विज़ार्ड डेटाबेस विवरण
Aurora PostgreSQL विज़ार्ड डेटाबेस विवरण -
डेटाबेस विकल्प कॉन्फ़िगर करें:
- इस लेखन के समय केवल PostgreSQL 9.6 उपलब्ध है। यदि आपको बीटा पूर्वावलोकन सहित हाल के संस्करणों के लिए समर्थन की आवश्यकता है, तो Amazon RDS पर PostgreSQL का उपयोग करें।
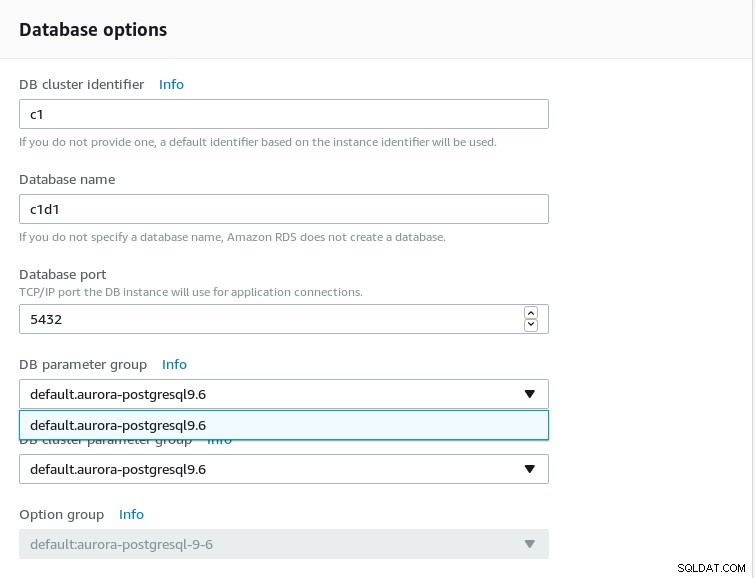
-
फ़ेलओवर प्राथमिकता को कॉन्फ़िगर करें, और प्रतिकृतियों की संख्या का चयन करें।
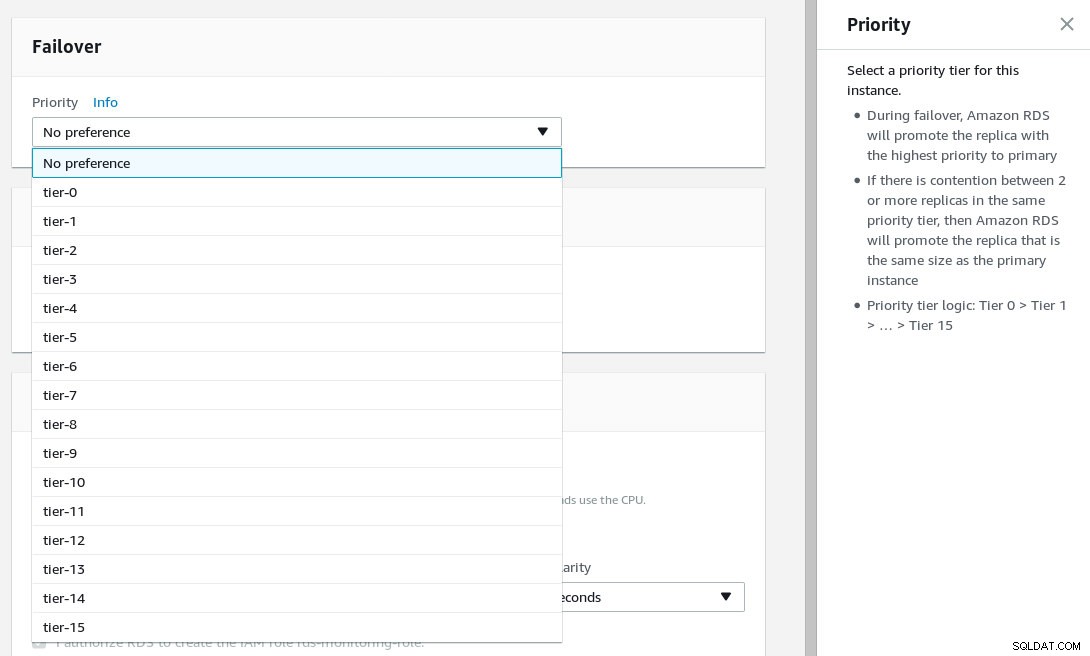 फ़ोटो विवरण
फ़ोटो विवरण -
बैकअप प्रतिधारण सेट करें (अधिकतम 35 दिन है)।
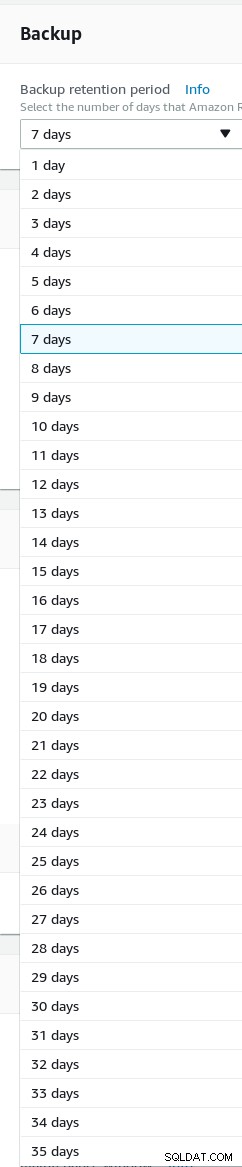 Aurora PostgreSQL विज़ार्ड बैकअप प्रतिधारण
Aurora PostgreSQL विज़ार्ड बैकअप प्रतिधारण -
रखरखाव अनुसूची का चयन करें। स्वचालित लघु संस्करण उन्नयन उपलब्ध हैं, हालांकि एडब्ल्यूएस समर्थन के साथ यह सत्यापित करना महत्वपूर्ण है कि पोस्टग्रेएसक्यूएल परियोजना किसी भी जरूरी अपडेट को जारी करने की स्थिति में उनके पैच शेड्यूल को तेज किया जा सकता है या नहीं। उदाहरण के तौर पर, AWS को 2018-05-10 अपडेट को आगे बढ़ाने में दो महीने से अधिक समय लगा।
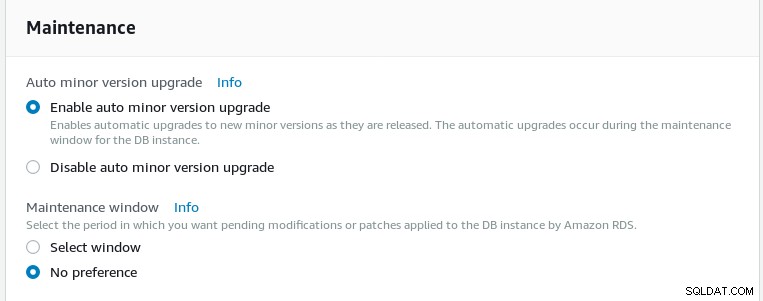 Aurora PostgreSQL विज़ार्ड अनुरक्षण शेड्यूल
Aurora PostgreSQL विज़ार्ड अनुरक्षण शेड्यूल -
यदि डेटाबेस को सफलतापूर्वक बनाया गया है तो इसे कैसे कनेक्ट किया जाए, इसके निर्देशों का एक लिंक प्रदर्शित किया जाएगा:
 Aurora PostgreSQL विज़ार्ड सेटअप पूर्ण
Aurora PostgreSQL विज़ार्ड सेटअप पूर्ण
डेटाबेस से कनेक्ट हो रहा है
इन्फ्रास्ट्रक्चर सेटअप के आधार पर उपलब्ध कनेक्शन विकल्पों के लिए विस्तृत निर्देशों की समीक्षा करें। सबसे सरल परिदृश्य में कनेक्शन एक सार्वजनिक EC2 उदाहरण के माध्यम से किया जाता है।
नोट:क्लाइंट को PostgreSQL 9.6.3 या इसके बाद के संस्करण के साथ संगत होना चाहिए।
[example@sqldat.com ~]# psql -U dbadmin -h c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com template1
Password for user dbadmin:
psql (9.6.8, server 9.6.3)
SSL connection (protocol: TLSv1.2, cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.निगरानी
अमेज़ॅन डेटाबेस की निगरानी के लिए विभिन्न मेट्रिक्स प्रदान करता है, उदाहरण मेट्रिक्स दिखाने के नीचे एक उदाहरण:
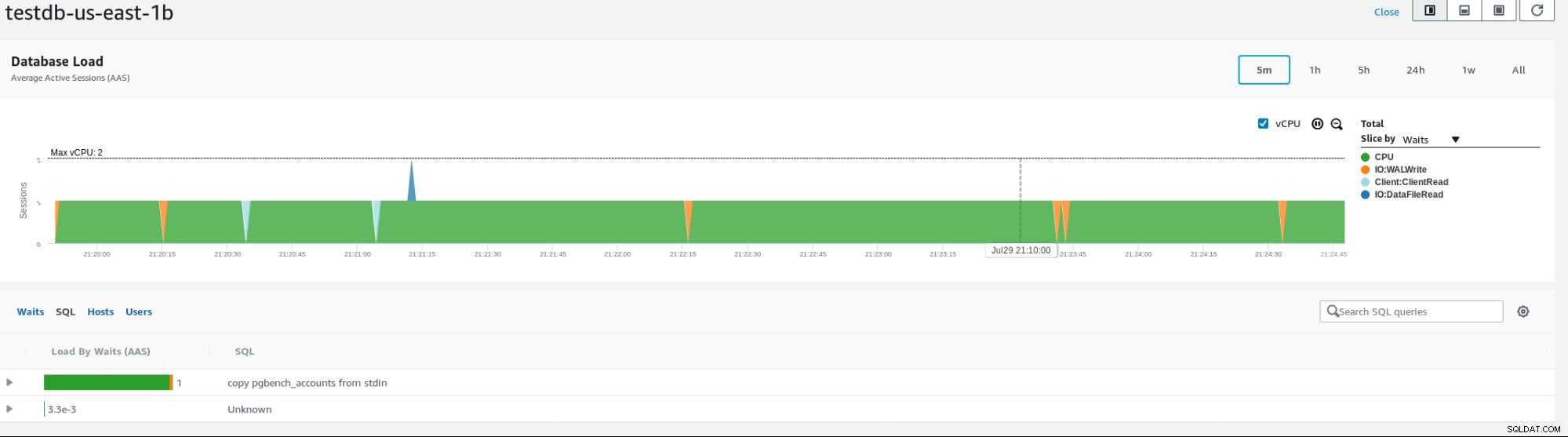 RDS इंस्टेंस मेट्रिक्स आज व्हाइटपेपर डाउनलोड करें ClusterControl के साथ पोस्टग्रेएसक्यूएल मैनेजमेंट एंड ऑटोमेशन जानें कि परिनियोजन, मॉनिटर करने के लिए आपको क्या जानना चाहिए, PostgreSQL को प्रबंधित और स्केल करें श्वेतपत्र डाउनलोड करें
RDS इंस्टेंस मेट्रिक्स आज व्हाइटपेपर डाउनलोड करें ClusterControl के साथ पोस्टग्रेएसक्यूएल मैनेजमेंट एंड ऑटोमेशन जानें कि परिनियोजन, मॉनिटर करने के लिए आपको क्या जानना चाहिए, PostgreSQL को प्रबंधित और स्केल करें श्वेतपत्र डाउनलोड करें PostgreSQL के लिए RDS
यह कॉन्फ़िगरेशन विकल्पों के संदर्भ में अधिक ग्रैन्युलैरिटी की अनुमति देने वाला एक ऑफ़र है। उदाहरण के लिए, ऑरोरा के विपरीत जो एक मालिकाना भंडारण प्रणाली का उपयोग करता है, आरडीएस ईबीएस संस्करणों का उपयोग करके विन्यास योग्य भंडारण प्रदान करता है जो या तो सामान्य प्रयोजन एसएसडी (जीपी 2), या प्रोविजन आईओपीएस, या चुंबकीय (अनुशंसित नहीं) हो सकता है।
बड़े इंस्टालेशन की सहायता के लिए, औरोरा ऑफ़रिंग में कस्टमाइज़ेशन उपलब्ध नहीं होने की आवश्यकता है, अमेज़ॅन ने हाल ही में सर्वोत्तम अभ्यास अनुशंसाएं जारी की हैं, जो केवल आरडीएस के लिए उपलब्ध हैं।
उच्च उपलब्धता को मैन्युअल रूप से कॉन्फ़िगर किया जाना चाहिए (या किसी भी ज्ञात एडब्ल्यूएस उपकरण का उपयोग करके स्वचालित) और मल्टी-एजेड परिनियोजन सेट करने की अनुशंसा की जाती है।
प्रतिकृति को PostgreSQL मूल प्रतिकृति का उपयोग करके कार्यान्वित किया जाता है।
PostgreSQL DB उदाहरणों के लिए कुछ सीमाएँ हैं जिन पर विचार करने की आवश्यकता है।
उपरोक्त नोटों को ध्यान में रखते हुए, यहां एक RDS PostgreSQL मल्टी-एजेड वातावरण स्थापित करने के लिए एक पूर्वाभ्यास है:
-
RDS प्रबंधन कंसोल . से विज़ार्ड प्रारंभ करें
 RDS PostgreSQL विज़ार्ड
RDS PostgreSQL विज़ार्ड -
उत्पादन और विकास सेटअप के बीच चयन करें।
 RDS PostgreSQL विज़ार्ड डेटाबेस उपयोग केस चयन
RDS PostgreSQL विज़ार्ड डेटाबेस उपयोग केस चयन -
अपने नए डेटाबेस क्लस्टर के बारे में विवरण दर्ज करें।
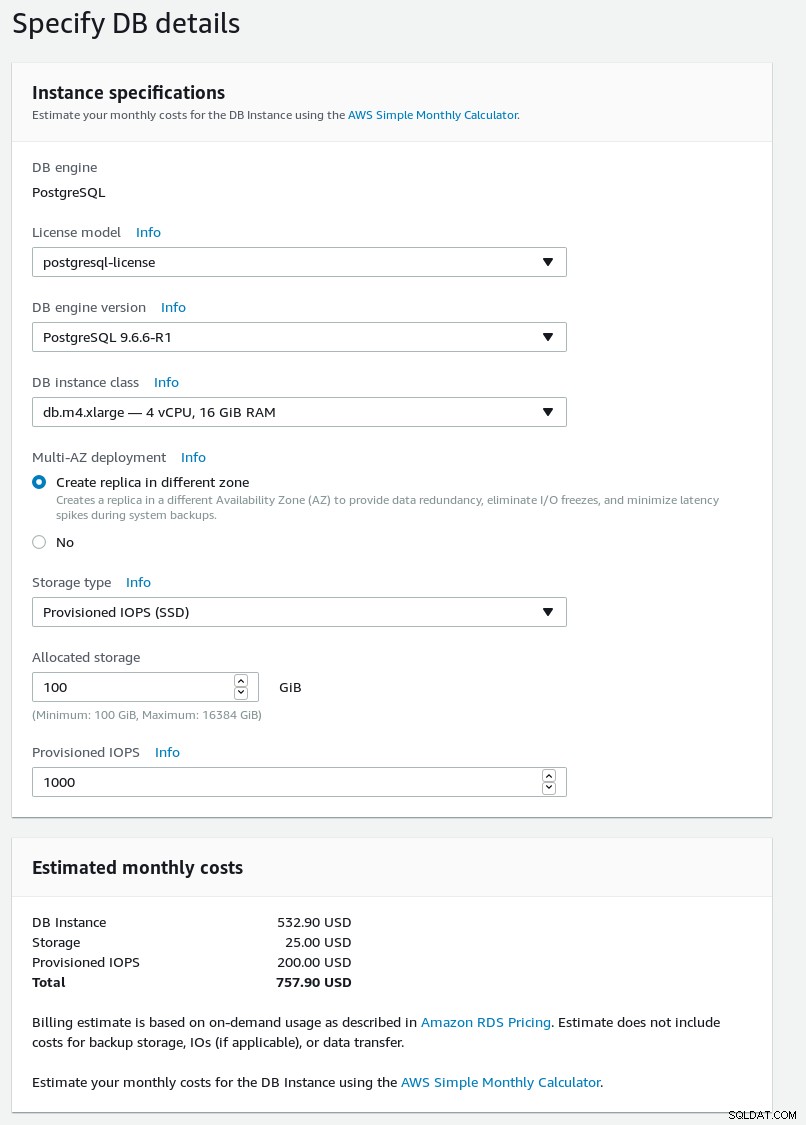 RDS PostgreSQL विज़ार्ड DB विवरण
RDS PostgreSQL विज़ार्ड DB विवरण 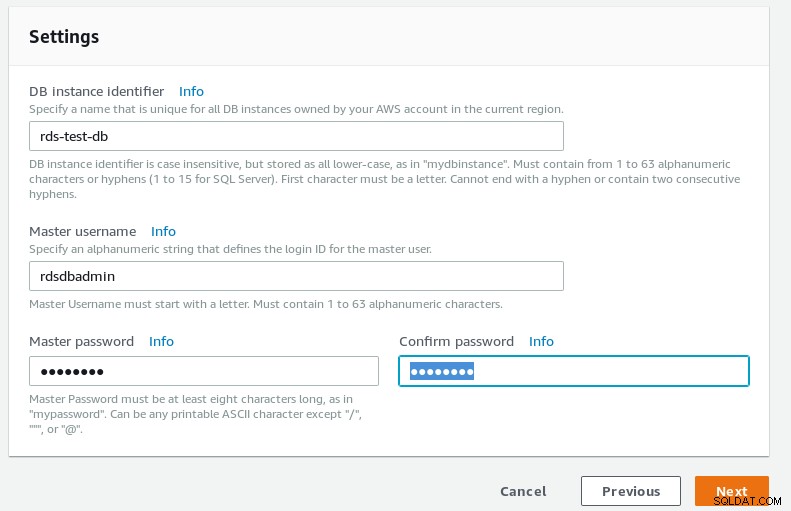 RDS PostgreSQL विज़ार्ड डेटाबेस सेटिंग्स
RDS PostgreSQL विज़ार्ड डेटाबेस सेटिंग्स -
अगले पेज पर नेटवर्किंग, सुरक्षा और रखरखाव शेड्यूल सेट करें:
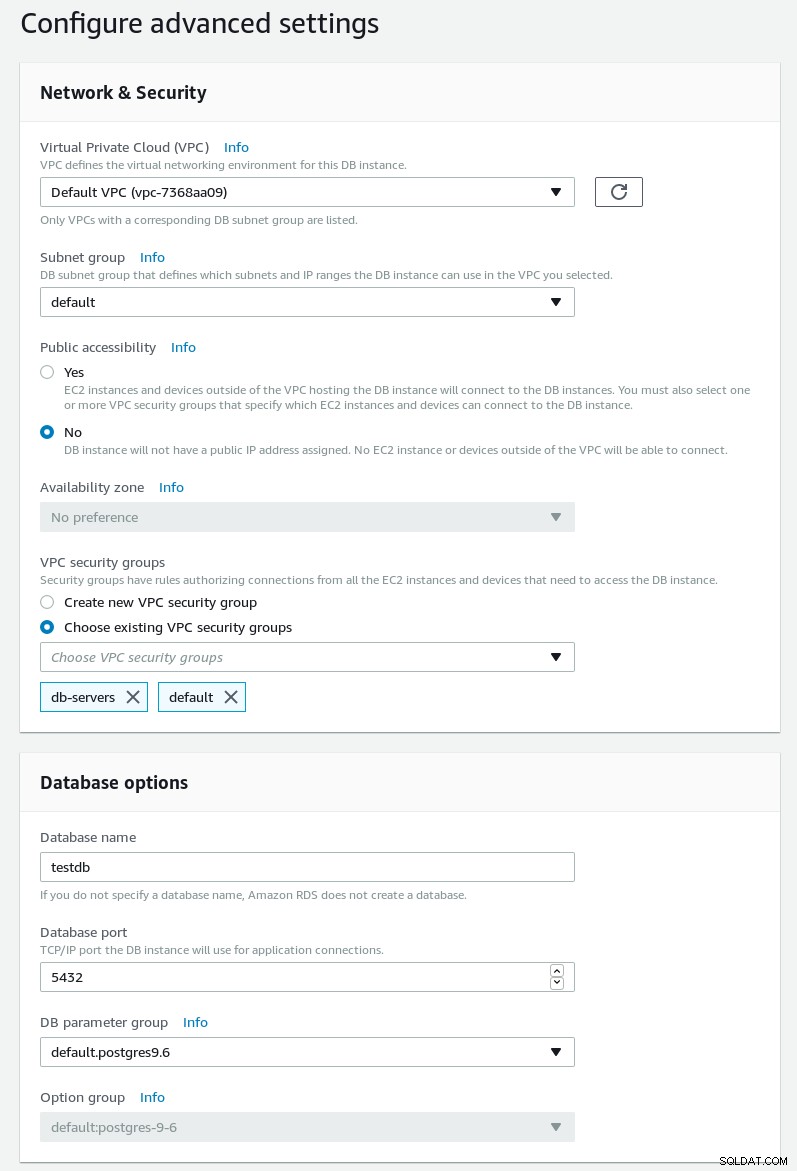 RDS PostgreSQL विज़ार्ड उन्नत सेटिंग्स
RDS PostgreSQL विज़ार्ड उन्नत सेटिंग्स 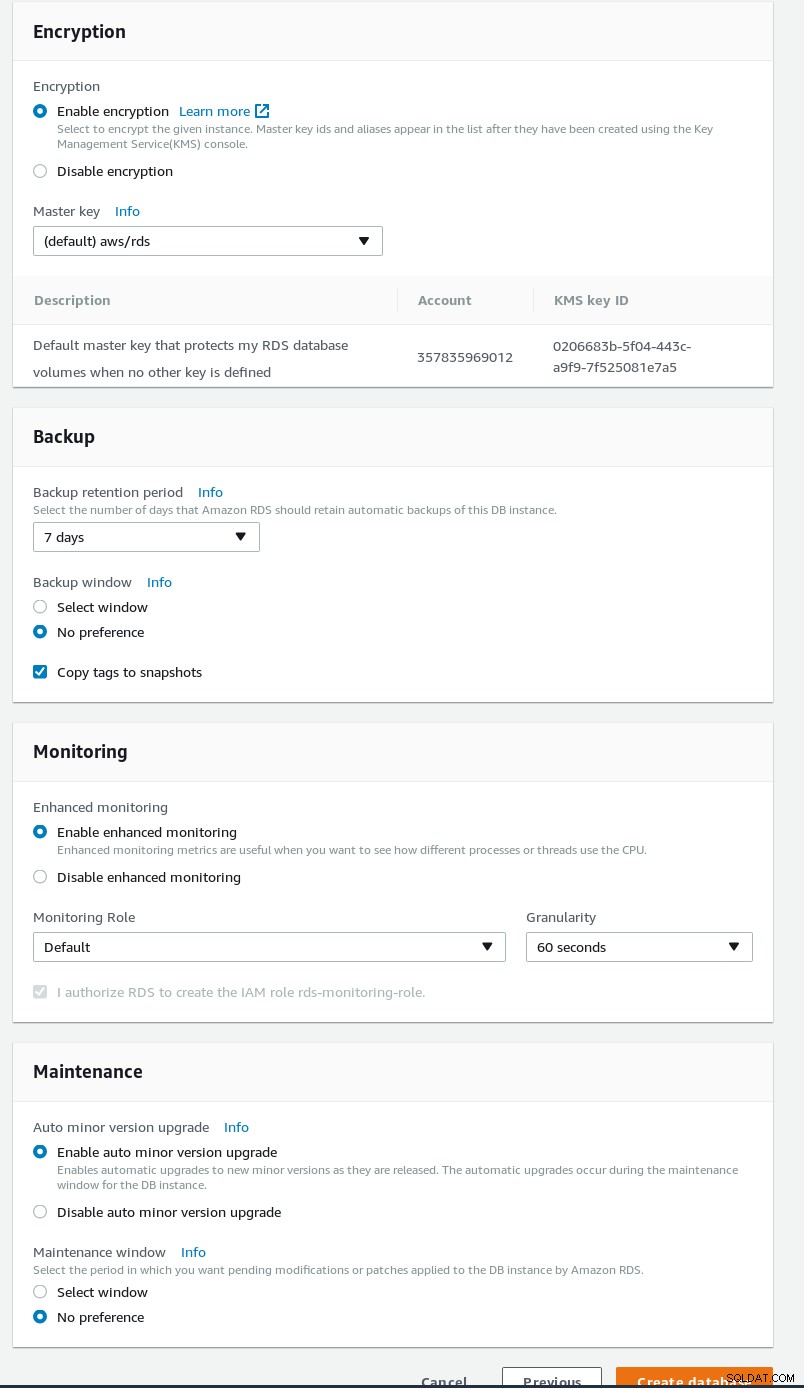 RDS PostgreSQL विज़ार्ड सुरक्षा और रखरखाव
RDS PostgreSQL विज़ार्ड सुरक्षा और रखरखाव
निष्कर्ष
PostgreSQL के लिए Amazon RDS सेवाओं में RDS PostgreSQL और Aurora PostgreSQL शामिल हैं, दोनों प्रबंधित DaaS प्रसाद हैं। बहुत सारी सुविधाओं और ठोस बैकएंड स्टोरेज के साथ पैक किए गए पारंपरिक सेटअप पर उनकी कुछ सीमाएं हैं, हालांकि, सावधानीपूर्वक योजना के साथ ये पेशकश एक संतुलित संतुलित लागत-कार्यक्षमता अनुपात प्रदान कर सकती हैं। PostgreSQL के लिए Amazon RDS उन उपयोगकर्ताओं के लिए लक्षित है, जिन्हें अपने वातावरण को कॉन्फ़िगर करने के लिए अधिक विकल्पों की आवश्यकता होती है, और आमतौर पर यह अधिक महंगा होता है। अधिकांश उपयोगकर्ताओं को Aurora PostgreSQL के साथ शुरुआत करने और अधिक जटिल कॉन्फ़िगरेशन में अपना काम करने से लाभ होगा।