डेटाबेस इंडेक्सिंग विशेष डेटा संरचनाओं का उपयोग है जिसका उद्देश्य डेटा पृष्ठों तक सीधे पहुंच प्राप्त करके प्रदर्शन में सुधार करना है। एक डेटाबेस इंडेक्स एक मुद्रित पुस्तक के इंडेक्स सेक्शन की तरह काम करता है:इंडेक्स सेक्शन में देखकर, उन पेज (पेजों) की पहचान करना बहुत तेज़ होता है जिनमें वह शब्द होता है जिसमें हम रुचि रखते हैं। हम आसानी से पृष्ठों का पता लगा सकते हैं और उन्हें सीधे एक्सेस कर सकते हैं . यह पुस्तक के पृष्ठों को क्रमिक रूप से स्कैन करने के बजाय है, जब तक कि हमें वह शब्द नहीं मिल जाता जिसकी हम तलाश कर रहे हैं।
डीबीए के हाथों में इंडेक्स एक आवश्यक उपकरण हैं। अनुक्रमणिका का उपयोग विभिन्न डेटा डोमेन के लिए शानदार प्रदर्शन लाभ प्रदान कर सकता है। PostgreSQL अपनी महान एक्स्टेंसिबिलिटी और कोर और थर्ड पार्टी एडऑन दोनों के समृद्ध संग्रह के लिए जाना जाता है, और अनुक्रमण इस नियम का अपवाद नहीं है। पोस्टग्रेएसक्यूएल इंडेक्स मामलों के एक समृद्ध स्पेक्ट्रम को कवर करते हैं, स्केलर प्रकारों पर सबसे सरल बी-ट्री इंडेक्स से भू-स्थानिक जीआईएसटी इंडेक्स से एफटीएस या जेसन या सरणी जीआईएन इंडेक्स तक।
इंडेक्स, हालांकि, जितने अद्भुत लगते हैं (और वास्तव में हैं!) मुफ्त में नहीं आते हैं। एक निश्चित दंड है जो अनुक्रमित तालिका पर लिखने के साथ जाता है। इसलिए डीबीए, एक विशिष्ट सूचकांक बनाने के लिए उसके विकल्पों की जांच करने से पहले, पहले यह सुनिश्चित कर लेना चाहिए कि उक्त सूचकांक पहली जगह में समझ में आता है, जिसका अर्थ है कि इसके निर्माण से लाभ लेखन पर प्रदर्शन हानि से अधिक होगा।
PostgreSQL बेसिक इंडेक्स टर्मिनोलॉजी
PostgreSQL में अनुक्रमणिका के प्रकारों और उनके उपयोग का वर्णन करने से पहले, आइए कुछ शब्दावली पर एक नज़र डालें कि कोई भी DBA दस्तावेज़ों को पढ़ते समय जल्दी या बाद में सामने आएगा।
- इंडेक्स एक्सेस विधि (इसे पहुंच विधि . भी कहा जाता है ):सूचकांक प्रकार (बी-पेड़, जीआईएसटी, जीआईएन, आदि)
- प्रकार: अनुक्रमित कॉलम का डेटा प्रकार
- ऑपरेटर: दो डेटा प्रकारों के बीच एक फ़ंक्शन
- संचालक परिवार: क्रॉस डेटा टाइप ऑपरेटर, समान व्यवहार वाले प्रकार के ऑपरेटरों को समूहीकृत करके
- संचालक वर्ग (सूचकांक रणनीति . के रूप में भी उल्लेख किया गया है ):एक कॉलम के लिए इंडेक्स द्वारा उपयोग किए जाने वाले ऑपरेटरों को परिभाषित करता है
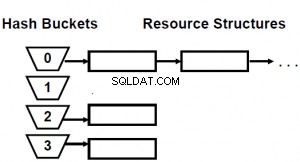
PostgreSQL के सिस्टम कैटलॉग में, एक्सेस विधियों को pg_am में, ऑपरेटर कक्षाओं को pg_opclass में, ऑपरेटर परिवारों को pg_opfamily में संग्रहीत किया जाता है। उपरोक्त की निर्भरता नीचे दिए गए चित्र में दिखाई गई है:

PostgreSQL में इंडेक्स के प्रकार
PostgreSQL निम्नलिखित इंडेक्स प्रकार प्रदान करता है:
- बी-पेड़: सॉर्ट किए जा सकने वाले प्रकारों के लिए लागू डिफ़ॉल्ट अनुक्रमणिका
- हैश: केवल समानता को संभालता है
- जिस्ट: गैर-स्केलर डेटा प्रकारों के लिए उपयुक्त (जैसे ज्यामितीय आकार, fts, सरणियाँ)
- SP-GiST: अंतरिक्ष विभाजित जीआईएसटी, गैर-संतुलित संरचनाओं (क्वाडट्री, के-डी ट्री, रेडिक्स ट्री) को संभालने के लिए जीआईएसटी का एक विकास
- GIN: जटिल प्रकारों के लिए उपयुक्त (जैसे jsonb, fts, arrays )
- BRIN: एक अपेक्षाकृत नए प्रकार का सूचकांक जो डेटा का समर्थन करता है जिसे प्रत्येक ब्लॉक में न्यूनतम/अधिकतम मान संग्रहीत करके क्रमबद्ध किया जा सकता है
कम हम कुछ वास्तविक दुनिया के उदाहरणों से अपने हाथों को गंदा करने की कोशिश करेंगे। दिए गए सभी उदाहरण FreeBSD 11.1 पर PostgreSQL 10.0 (10 और 9 psql क्लाइंट दोनों के साथ) के साथ किए गए हैं।
बी-पेड़ अनुक्रमणिका
मान लें कि हमारे पास निम्न तालिका है:
create table part (
id serial primary key,
partno varchar(20) NOT NULL UNIQUE,
partname varchar(80) NOT NULL,
partdescr text,
machine_id int NOT NULL
);
testdb=# \d part
Table "public.part"
Column | Type | Modifiers
------------+-----------------------+---------------------------------------------------
id | integer | not null default nextval('part_id_seq'::regclass)
partno | character varying(20)| not null
partname | character varying(80)| not null
partdescr | text |
machine_id | integer | not null
Indexes:
"part_pkey" PRIMARY KEY, btree (id)
"part_partno_key" UNIQUE CONSTRAINT, btree (partno)जब हम इस सामान्य तालिका को परिभाषित करते हैं, तो PostgreSQL पर्दे के पीछे दो अद्वितीय बी-ट्री इंडेक्स बनाता है:part_pkey और part_partno_key। तो PostgreSQL में प्रत्येक अद्वितीय बाधा को एक अद्वितीय INDEX के साथ कार्यान्वित किया जाता है। आइए हमारी तालिका को डेटा की एक लाख पंक्तियों से भर दें:
testdb=# with populate_qry as (select gs from generate_series(1,1000000) as gs )
insert into part (partno, partname,machine_id) SELECT 'PNo:'||gs, 'Part '||gs,0 from populate_qry;
INSERT 0 1000000आइए अब हमारी मेज पर कुछ प्रश्न करने का प्रयास करते हैं। पहले हम psql क्लाइंट को \time:
. लिखकर क्वेरी टाइम रिपोर्ट करने के लिए कहते हैंtestdb=# select * from part where id=100000;
id | partno | partname | partdescr | machine_id
--------+------------+-------------+-----------+------------
100000 | PNo:100000 | Part 100000 | | 0
(1 row)
Time: 0,284 mstestdb=# select * from part where partno='PNo:100000';
id | partno | partname | partdescr | machine_id
--------+------------+-------------+-----------+------------
100000 | PNo:100000 | Part 100000 | | 0
(1 row)
Time: 0,319 msहम देखते हैं कि हमारे परिणाम प्राप्त करने में मिलीसेकंड के केवल अंश लगते हैं। हमें इसकी उम्मीद थी क्योंकि उपरोक्त प्रश्नों में उपयोग किए गए दोनों कॉलमों के लिए, हमने पहले ही उपयुक्त इंडेक्स को परिभाषित कर दिया है। अब कॉलम partname पर क्वेरी करने का प्रयास करते हैं, जिसके लिए कोई अनुक्रमणिका मौजूद नहीं है।
testdb=# select * from part where partname='Part 100000';
id | partno | partname | partdescr | machine_id
--------+------------+-------------+-----------+------------
100000 | PNo:100000 | Part 100000 | | 0
(1 row)
Time: 89,173 msयहां हम स्पष्ट रूप से देखते हैं कि गैर अनुक्रमित कॉलम के लिए, प्रदर्शन में काफी गिरावट आई है। अब उस कॉलम पर एक इंडेक्स बनाते हैं, और क्वेरी को दोहराते हैं:
testdb=# create index part_partname_idx ON part(partname);
CREATE INDEX
Time: 15734,829 ms (00:15,735)
testdb=# select * from part where partname='Part 100000';
id | partno | partname | partdescr | machine_id
--------+------------+-------------+-----------+------------
100000 | PNo:100000 | Part 100000 | | 0
(1 row)
Time: 0,525 msहमारा नया इंडेक्स part_partname_idx भी एक बी-ट्री इंडेक्स (डिफ़ॉल्ट) है। पहले हम ध्यान दें कि दस लाख पंक्तियों की तालिका पर सूचकांक निर्माण में लगभग 16 सेकंड का महत्वपूर्ण समय लगा। फिर हम देखते हैं कि हमारी क्वेरी स्पीड को 89 एमएस से बढ़ाकर 0.525 एमएस कर दिया गया था। बी-ट्री इंडेक्स, समानता के लिए जाँच के अलावा, अन्य ऑपरेटरों से जुड़े प्रश्नों में भी मदद कर सकते हैं, जैसे कि <,<=,>=,>। आइए <=और>=
. के साथ प्रयास करेंtestdb=# select count(*) from part where partname>='Part 9999900';
count
-------
9
(1 row)
Time: 0,359 mstestdb=# select count(*) from part where partname<='Part 9999900';
count
--------
999991
(1 row)
Time: 355,618 msपहली क्वेरी दूसरे की तुलना में बहुत तेज़ है, EXPLAIN (या EXPLAIN ANALYZE) कीवर्ड का उपयोग करके हम देख सकते हैं कि वास्तविक इंडेक्स का उपयोग किया गया है या नहीं:
testdb=# explain select count(*) from part where partname>='Part 9999900';
QUERY PLAN
-----------------------------------------------------------------------------------------
Aggregate (cost=8.45..8.46 rows=1 width=8)
-> Index Only Scan using part_partname_idx on part (cost=0.42..8.44 rows=1 width=0)
Index Cond: (partname >= 'Part 9999900'::text)
(3 rows)
Time: 0,671 mstestdb=# explain select count(*) from part where partname<='Part 9999900';
QUERY PLAN
----------------------------------------------------------------------------------------
Finalize Aggregate (cost=14603.22..14603.23 rows=1 width=8)
-> Gather (cost=14603.00..14603.21 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=13603.00..13603.01 rows=1 width=8)
-> Parallel Seq Scan on part (cost=0.00..12561.33 rows=416667 width=0)
Filter: ((partname)::text <= 'Part 9999900'::text)
(6 rows)
Time: 0,461 msपहले मामले में, क्वेरी प्लानर part_partname_idx अनुक्रमणिका का उपयोग करना चुनता है। हम यह भी देखते हैं कि इसके परिणामस्वरूप केवल-इंडेक्स स्कैन होगा जिसका अर्थ है कि डेटा तालिकाओं तक कोई पहुंच नहीं है। दूसरे मामले में योजनाकार यह निर्धारित करता है कि सूचकांक का उपयोग करने का कोई मतलब नहीं है क्योंकि लौटाए गए परिणाम तालिका का एक बड़ा हिस्सा हैं, इस मामले में अनुक्रमिक स्कैन को तेज माना जाता है।
हैश इंडेक्स
WAL लेखन की कमी के कारण होने वाले कारणों के कारण PgSQL 9.6 तक और इसमें शामिल हैश इंडेक्स का उपयोग हतोत्साहित किया गया था। PgSQL 10.0 के रूप में उन मुद्दों को ठीक कर दिया गया था, लेकिन फिर भी हैश इंडेक्स का उपयोग करने के लिए बहुत कम समझ में आया। PgSQL 11 में इसके बड़े भाइयों (B-tree, GiST, GIN) के साथ हैश इंडेक्स को प्रथम श्रेणी इंडेक्स विधि बनाने के प्रयास हैं। तो, इसे ध्यान में रखते हुए, आइए वास्तव में एक हैश इंडेक्स को क्रियान्वित करने का प्रयास करें।
हम अपनी पार्ट टेबल को एक नए कॉलम पार्टटाइप के साथ समृद्ध करेंगे और इसे समान वितरण के मूल्यों के साथ पॉप्युलेट करेंगे, और फिर एक क्वेरी चलाएंगे जो 'स्टीयरिंग' के बराबर पार्टटाइप के लिए परीक्षण करती है:
testdb=# alter table part add parttype varchar(100) CHECK (parttype in ('Engine','Suspension','Driveline','Brakes','Steering','General')) NOT NULL DEFAULT 'General';
ALTER TABLE
Time: 42690,557 ms (00:42,691)
testdb=# with catqry as (select id,(random()*6)::int % 6 as cat from part)
update part SET parttype = CASE WHEN cat=1 THEN 'Engine' WHEN cat=2 THEN 'Suspension' WHEN cat=3 THEN 'Driveline' WHEN cat=4 THEN 'Brakes' WHEN cat=5 THEN 'Steering' ELSE 'General' END FROM catqry WHERE part.id=catqry.id;
UPDATE 1000000
Time: 46345,386 ms (00:46,345)
testdb=# select count(*) from part where id % 500 = 0 AND parttype = 'Steering';
count
-------
322
(1 row)
Time: 93,361 msअब हम इस नए कॉलम के लिए एक हैश इंडेक्स बनाते हैं, और पिछली क्वेरी को फिर से आजमाते हैं:
testdb=# create index part_parttype_idx ON part USING hash(parttype);
CREATE INDEX
Time: 95525,395 ms (01:35,525)
testdb=# analyze ;
ANALYZE
Time: 1986,642 ms (00:01,987)
testdb=# select count(*) from part where id % 500 = 0 AND parttype = 'Steering';
count
-------
322
(1 row)
Time: 63,634 msहम हैश इंडेक्स का उपयोग करने के बाद सुधार पर ध्यान देते हैं। अब हम पूर्णांकों पर हैश इंडेक्स के प्रदर्शन की तुलना समतुल्य बी-ट्री इंडेक्स से करेंगे।
testdb=# update part set machine_id = id;
UPDATE 1000000
Time: 392548,917 ms (06:32,549)
testdb=# select * from part where id=500000;
id | partno | partname | partdescr | machine_id | parttype
--------+------------+-------------+-----------+------------+------------
500000 | PNo:500000 | Part 500000 | | 500000 | Suspension
(1 row)
Time: 0,316 mstestdb=# select * from part where machine_id=500000;
id | partno | partname | partdescr | machine_id | parttype
--------+------------+-------------+-----------+------------+------------
500000 | PNo:500000 | Part 500000 | | 500000 | Suspension
(1 row)
Time: 97,037 mstestdb=# create index part_machine_id_idx ON part USING hash(machine_id);
CREATE INDEX
Time: 4756,249 ms (00:04,756)
testdb=#
testdb=# select * from part where machine_id=500000;
id | partno | partname | partdescr | machine_id | parttype
--------+------------+-------------+-----------+------------+------------
500000 | PNo:500000 | Part 500000 | | 500000 | Suspension
(1 row)
Time: 0,297 msजैसा कि हम देखते हैं, हैश इंडेक्स के उपयोग के साथ, समानता की जांच करने वाले प्रश्नों की गति बी-ट्री इंडेक्स की गति के बहुत करीब है। कहा जाता है कि हैश इंडेक्स बी-पेड़ों की तुलना में समानता के लिए मामूली रूप से तेज़ होते हैं, वास्तव में हमें प्रत्येक क्वेरी को दो या तीन बार आज़माना पड़ता था जब तक कि हैश इंडेक्स बी-ट्री समकक्ष से बेहतर परिणाम नहीं देता।
आज श्वेतपत्र डाउनलोड करें क्लस्टरकंट्रोल के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, मॉनिटर करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंGiST इंडेक्स
जीआईएसटी (सामान्यीकृत खोज वृक्ष) एक तरह के सूचकांक से अधिक है, बल्कि कई अनुक्रमण रणनीतियों के निर्माण के लिए एक बुनियादी ढांचा है। डिफ़ॉल्ट PostgreSQL वितरण ज्यामितीय डेटा प्रकार, tsquery और tsvector के लिए समर्थन प्रदान करता है। योगदान में कई अन्य ऑपरेटर वर्गों के कार्यान्वयन हैं। डॉक्स और कॉन्ट्रिब डीआईआर को पढ़कर, पाठक देखेंगे कि जीआईएसटी और जीआईएन उपयोग के मामलों के बीच एक बड़ा ओवरलैप है:मुख्य मामलों के नाम के लिए इंट एरेज़, फुल टेक्स्ट सर्च। उन मामलों में GIN तेज़ है, और आधिकारिक दस्तावेज़ीकरण स्पष्ट रूप से यह बताता है। हालांकि, जीआईएसटी व्यापक ज्यामितीय डेटा प्रकार का समर्थन प्रदान करता है। साथ ही, इस लेखन के समय, जीआईएसटी (और एसपी-जीआईएसटी) एकमात्र सार्थक तरीका है जिसका उपयोग बहिष्करण बाधाओं के साथ किया जा सकता है। हम इस पर एक उदाहरण देखेंगे। मान लीजिए (मैकेनिकल इंजीनियरिंग के क्षेत्र में रहते हुए) कि हमें एक विशेष मशीन प्रकार के लिए मशीनों के प्रकार भिन्नताओं को परिभाषित करने की आवश्यकता है, जो एक निश्चित अवधि के लिए मान्य हैं; और यह कि किसी विशेष भिन्नता के लिए, उसी मशीन प्रकार के लिए कोई अन्य भिन्नता मौजूद नहीं हो सकती है, जिसकी समयावधि विशेष भिन्नता अवधि के साथ ओवरलैप (संघर्ष) करती है।
create table machine_type (
id SERIAL PRIMARY KEY,
mtname varchar(50) not null,
mtvar varchar(20) not null,
start_date date not null,
end_date date,
CONSTRAINT machine_type_uk UNIQUE (mtname,mtvar)
);ऊपर हम PostgreSQL को बताते हैं कि प्रत्येक मशीन प्रकार के नाम (mtname) के लिए केवल एक भिन्नता (mtvar) हो सकती है। Start_date उस अवधि की आरंभ तिथि को दर्शाता है जिसमें यह मशीन प्रकार भिन्नता मान्य है, और end_date इस अवधि की समाप्ति तिथि को दर्शाता है। Null end_date का अर्थ है कि मशीन प्रकार भिन्नता वर्तमान में मान्य है। अब हम गैर-अतिव्यापी आवश्यकता को एक बाधा के साथ व्यक्त करना चाहते हैं। ऐसा करने का तरीका एक बहिष्करण बाधा के साथ है:
testdb=# alter table machine_type ADD CONSTRAINT machine_type_per EXCLUDE USING GIST (mtname WITH =,daterange(start_date,end_date) WITH &&);EXCLUDE PostgreSQL सिंटैक्स हमें विभिन्न प्रकार के कई कॉलम और प्रत्येक के लिए एक अलग ऑपरेटर के साथ निर्दिष्ट करने की अनुमति देता है। &&दिनांक सीमाओं के लिए ओवरलैपिंग ऑपरेटर है, और =वर्चर के लिए सामान्य समानता ऑपरेटर है। लेकिन जब तक हम एंटर दबाते हैं PostgreSQL एक संदेश के साथ शिकायत करता है:
ERROR: data type character varying has no default operator class for access method "gist"
HINT: You must specify an operator class for the index or define a default operator class for the data type.यहाँ जो कमी है वह है वर्चर के लिए GiST opclass समर्थन। बशर्ते हमने btree_gist एक्सटेंशन को सफलतापूर्वक बनाया और इंस्टॉल किया हो, हम एक्सटेंशन बनाने के साथ आगे बढ़ सकते हैं:
testdb=# create extension btree_gist ;
CREATE EXTENSIONऔर फिर बाधा उत्पन्न करने और उसका परीक्षण करने का पुनः प्रयास करें:
testdb=# alter table machine_type ADD CONSTRAINT machine_type_per EXCLUDE USING GIST (mtname WITH =,daterange(start_date,end_date) WITH &&);
ALTER TABLE
testdb=# insert into machine_type (mtname,mtvar,start_date,end_date) VALUES('Subaru EJ20','SH','2008-01-01','2013-01-01');
INSERT 0 1
testdb=# insert into machine_type (mtname,mtvar,start_date,end_date) VALUES('Subaru EJ20','SG','2002-01-01','2009-01-01');
ERROR: conflicting key value violates exclusion constraint "machine_type_per"
DETAIL: Key (mtname, daterange(start_date, end_date))=(Subaru EJ20, [2002-01-01,2009-01-01)) conflicts with existing key (mtname, daterange(start_date, end_date))=(Subaru EJ20, [2008-01-01,2013-01-01)).
testdb=# insert into machine_type (mtname,mtvar,start_date,end_date) VALUES('Subaru EJ20','SG','2002-01-01','2008-01-01');
INSERT 0 1
testdb=# insert into machine_type (mtname,mtvar,start_date,end_date) VALUES('Subaru EJ20','SJ','2013-01-01',null);
INSERT 0 1
testdb=# insert into machine_type (mtname,mtvar,start_date,end_date) VALUES('Subaru EJ20','SJ2','2018-01-01',null);
ERROR: conflicting key value violates exclusion constraint "machine_type_per"
DETAIL: Key (mtname, daterange(start_date, end_date))=(Subaru EJ20, [2018-01-01,)) conflicts with existing key (mtname, daterange(start_date, end_date))=(Subaru EJ20, [2013-01-01,)).SP-GiST इंडेक्स
SP-GiST, जो अंतरिक्ष-विभाजित GiST के लिए खड़ा है, जैसे GiST, एक बुनियादी ढांचा है जो गैर-संतुलित डिस्क-आधारित डेटा संरचनाओं के क्षेत्र में कई अलग-अलग रणनीतियों के विकास को सक्षम बनाता है। डिफ़ॉल्ट PgSQL वितरण द्वि-आयामी बिंदुओं, (किसी भी प्रकार) श्रेणियों, पाठ और इनसेट प्रकारों के लिए समर्थन प्रदान करता है। जीआईएसटी की तरह, एसपी-जीआईएसटी का उपयोग बहिष्करण बाधाओं में किया जा सकता है, ठीक उसी तरह जैसे पिछले अध्याय में दिखाया गया है।
GIN अनुक्रमणिका
GIN (सामान्यीकृत उलटा सूचकांक) जैसे GiST और SP-GiST कई अनुक्रमण रणनीतियाँ प्रदान कर सकते हैं। जब हम समग्र प्रकार के स्तंभों को अनुक्रमित करना चाहते हैं तो GIN उपयुक्त होता है। डिफ़ॉल्ट PostgreSQL वितरण किसी भी सरणी प्रकार, jsonb और पूर्ण पाठ खोज (tsvector) के लिए समर्थन प्रदान करता है। योगदान में कई अन्य ऑपरेटर वर्गों के कार्यान्वयन हैं। Jsonb, PostgreSQL की एक अत्यधिक प्रशंसित विशेषता (और अपेक्षाकृत हाल ही में (9.4+) विकास) अनुक्रमणिका समर्थन के लिए GIN पर निर्भर है। GIN का एक अन्य सामान्य उपयोग पूर्ण पाठ खोज के लिए अनुक्रमण है। PgSQL में पूर्ण पाठ खोज अपने आप में एक लेख के योग्य है, इसलिए हम यहां केवल अनुक्रमण भाग को कवर करेंगे। सबसे पहले, partdescr कॉलम को नॉट अशक्त मान देकर और सार्थक मान के साथ एक पंक्ति को अपडेट करके, अपनी तालिका के लिए कुछ तैयारी करें:
testdb=# update part set partdescr ='';
UPDATE 1000000
Time: 383407,114 ms (06:23,407)
testdb=# update part set partdescr = 'thermostat for the cooling system' where id=500000;
UPDATE 1
Time: 2,405 msफिर हम नए अपडेट किए गए कॉलम पर टेक्स्ट सर्च करते हैं:
testdb=# select * from part where partdescr @@ 'thermostat';
id | partno | partname | partdescr | machine_id | parttype
--------+------------+-------------+-----------------------------------+------------+------------
500000 | PNo:500000 | Part 500000 | thermostat for the cooling system | 500000 | Suspension
(1 row)
Time: 2015,690 ms (00:02,016)यह काफी धीमा है, हमारे परिणाम लाने के लिए लगभग 2 सेकंड। आइए अब टाइप tsvector पर GIN इंडेक्स बनाने की कोशिश करें, और इंडेक्स-फ्रेंडली सिंटैक्स का उपयोग करके क्वेरी को दोहराएं:
testdb=# CREATE INDEX part_partdescr_idx ON part USING gin(to_tsvector('english',partdescr));
CREATE INDEX
Time: 1431,550 ms (00:01,432)
testdb=# select * from part where to_tsvector('english',partdescr) @@ to_tsquery('thermostat');
id | partno | partname | partdescr | machine_id | parttype
--------+------------+-------------+-----------------------------------+------------+------------
500000 | PNo:500000 | Part 500000 | thermostat for the cooling system | 500000 | Suspension
(1 row)
Time: 0,952 msऔर हमें 2000 गुना गति मिलती है। साथ ही हम यह भी नोट कर सकते हैं कि सूचकांक को बनाने में अपेक्षाकृत कम समय लगा। आप उपरोक्त उदाहरण में GIN के बजाय GiST का उपयोग करके प्रयोग कर सकते हैं, और दोनों एक्सेस विधियों के लिए रीड, राइट और इंडेक्स निर्माण के प्रदर्शन को माप सकते हैं।
BRIN अनुक्रमणिका
BRIN (ब्लॉक रेंज इंडेक्स) PostgreSQL के इंडेक्स प्रकारों के सेट में सबसे नया जोड़ है, क्योंकि इसे PostgreSQL 9.5 में पेश किया गया था, जिसमें मानक कोर फीचर के रूप में केवल कुछ साल थे। ब्रिन "ब्लॉक रेंज" नामक पृष्ठों के एक सेट के लिए सारांश जानकारी संग्रहीत करके बहुत बड़ी तालिकाओं पर काम करता है। BRIN अनुक्रमणिका हानिपूर्ण हैं (जैसे GiST) और इसके लिए PostgreSQL के क्वेरी निष्पादक में अतिरिक्त तर्क की आवश्यकता होती है, और अतिरिक्त रखरखाव की भी आवश्यकता होती है। आइए देखते हैं BRIN काम कर रहा है:
testdb=# select count(*) from part where machine_id BETWEEN 5000 AND 10000;
count
-------
5001
(1 row)
Time: 100,376 mstestdb=# create index part_machine_id_idx_brin ON part USING BRIN(machine_id);
CREATE INDEX
Time: 569,318 ms
testdb=# select count(*) from part where machine_id BETWEEN 5000 AND 10000;
count
-------
5001
(1 row)
Time: 5,461 msयहां हम BRIN इंडेक्स के उपयोग से औसतन ~ 18-गुना गति देखते हैं। हालांकि, ब्रिन का असली घर बड़े डेटा के क्षेत्र में है, इसलिए हम भविष्य में वास्तविक दुनिया के परिदृश्यों में इस अपेक्षाकृत नई तकनीक का परीक्षण करने की उम्मीद करते हैं।