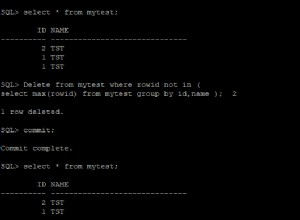
टेस्ट केस
सबसे पहले, एक sqlfiddle . में अपने डेटा को प्रस्तुत करने का एक अधिक उपयोगी तरीका - या उससे भी बेहतर , इसके साथ खेलने के लिए तैयार:
CREATE TEMP TABLE data(
system_measured int
, time_of_measurement int
, measurement int
);
INSERT INTO data VALUES
(1, 1, 5)
,(1, 2, 150)
,(1, 3, 5)
,(1, 4, 5)
,(2, 1, 5)
,(2, 2, 5)
,(2, 3, 5)
,(2, 4, 5)
,(2, 5, 150)
,(2, 6, 5)
,(2, 7, 5)
,(2, 8, 5);
सरल क्वेरी
चूंकि यह स्पष्ट नहीं है, मैं केवल ऊपर दिए गए के रूप में मान रहा हूं।
WITH x AS (
SELECT *, CASE WHEN lag(measurement) OVER (PARTITION BY system_measured
ORDER BY time_of_measurement) = measurement
THEN 0 ELSE 1 END AS step
FROM data
)
, y AS (
SELECT *, sum(step) OVER(PARTITION BY system_measured
ORDER BY time_of_measurement) AS grp
FROM x
)
SELECT * ,row_number() OVER (PARTITION BY system_measured, grp
ORDER BY time_of_measurement) - 1 AS repeat_ct
FROM y
ORDER BY system_measured, time_of_measurement;
अब, जबकि शुद्ध SQL का उपयोग करना अच्छा और चमकदार है, यह बहुत . होगा plpgsql फ़ंक्शन के साथ तेज़, क्योंकि यह इसे एकल टेबल स्कैन में कर सकता है जहाँ इस क्वेरी को कम से कम तीन स्कैन की आवश्यकता होती है।
plpgsql फ़ंक्शन के साथ तेज़:
CREATE OR REPLACE FUNCTION x.f_repeat_ct()
RETURNS TABLE (
system_measured int
, time_of_measurement int
, measurement int, repeat_ct int
) LANGUAGE plpgsql AS
$func$
DECLARE
r data; -- table name serves as record type
r0 data;
BEGIN
-- SET LOCAL work_mem = '1000 MB'; -- uncomment an adapt if needed, see below!
repeat_ct := 0; -- init
FOR r IN
SELECT * FROM data d ORDER BY d.system_measured, d.time_of_measurement
LOOP
IF r.system_measured = r0.system_measured
AND r.measurement = r0.measurement THEN
repeat_ct := repeat_ct + 1; -- start new array
ELSE
repeat_ct := 0; -- start new count
END IF;
RETURN QUERY SELECT r.*, repeat_ct;
r0 := r; -- remember last row
END LOOP;
END
$func$;
कॉल करें:
SELECT * FROM x.f_repeat_ct();
इस तरह के plpgsql फ़ंक्शन में हर समय अपने कॉलम नामों को टेबल-क्वालिफाई करना सुनिश्चित करें, क्योंकि हम आउटपुट पैरामीटर के समान नामों का उपयोग करते हैं, जो योग्य नहीं होने पर प्राथमिकता लेंगे।
अरबों पंक्तियां
अगर आपके पास अरबों हैं पंक्तियों की , आप इस ऑपरेशन को विभाजित करना चाह सकते हैं। मैं यहां मैनुअल को उद्धृत करता हूं:
<ब्लॉकक्वॉट>
नोट:RETURN NEXT . का वर्तमान कार्यान्वयन और RETURN QUERY जैसा कि ऊपर चर्चा की गई है, फ़ंक्शन से लौटने से पहले पूरे परिणाम सेट को संग्रहीत करता है। इसका मतलब यह है कि यदि कोई PL/pgSQL फ़ंक्शन बहुत बड़ा परिणाम सेट उत्पन्न करता है, तो प्रदर्शन खराब हो सकता है:मेमोरी थकावट से बचने के लिए डेटा डिस्क पर लिखा जाएगा, लेकिन फ़ंक्शन स्वयं तब तक वापस नहीं आएगा जब तक कि संपूर्ण परिणाम सेट उत्पन्न नहीं हो जाता। पीएल/पीजीएसक्यूएल का भविष्य संस्करण उपयोगकर्ताओं को सेट-रिटर्निंग फ़ंक्शंस को परिभाषित करने की अनुमति दे सकता है जिसमें यह सीमा नहीं है। वर्तमान में, जिस बिंदु पर डिस्क पर डेटा लिखा जाना शुरू होता है, उसे वर्क_मेमकॉन्फ़िगरेशन चर द्वारा नियंत्रित किया जाता है। जिन व्यवस्थापकों के पास स्मृति में बड़े परिणाम सेट को संग्रहीत करने के लिए पर्याप्त स्मृति है, उन्हें इस पैरामीटर को बढ़ाने पर विचार करना चाहिए।
एक समय में एक सिस्टम के लिए पंक्तियों की गणना करने पर विचार करें या work_mem . के लिए पर्याप्त उच्च मान सेट करें भार से निपटने के लिए। कार्य_मेम के बारे में अधिक जानकारी के लिए उद्धरण में दिए गए लिंक का अनुसरण करें।
एक तरीका यह होगा कि work_mem . के लिए बहुत अधिक मान सेट किया जाए SET LOCAL . के साथ आपके फ़ंक्शन में, जो केवल वर्तमान लेनदेन के लिए प्रभावी है। मैंने समारोह में एक टिप्पणी पंक्ति जोड़ी। नहीं करें इसे विश्व स्तर पर बहुत अधिक सेट करें, क्योंकि यह आपके सर्वर को न्यूक कर सकता है। मैनुअल पढ़ें।