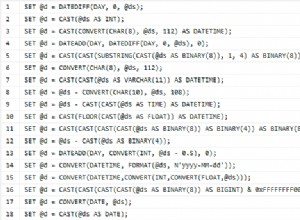
एक स्टैंडअलोन के साथ VALUES अभिव्यक्ति PostgreSQL को पता नहीं है कि डेटा प्रकार क्या होना चाहिए। सरल संख्यात्मक शाब्दिकों के साथ सिस्टम मिलान प्रकारों को ग्रहण करने में प्रसन्न होता है। लेकिन अन्य इनपुट के साथ (जैसे NULL ) आपको स्पष्ट रूप से कास्ट करने की आवश्यकता होगी - जैसा कि आप पहले ही पता लगा चुके हैं।
आप pg_catalog के बारे में पूछ सकते हैं (तेज़, लेकिन PostgreSQL-विशिष्ट) या information_schema (धीमा, लेकिन मानक SQL) उपयुक्त प्रकारों के साथ अपने कथन का पता लगाने और तैयार करने के लिए।
या आप इनमें से किसी एक सरल "ट्रिक" का उपयोग कर सकते हैं (मैंने पिछली . के लिए सर्वश्रेष्ठ सहेजा है ):
0. LIMIT 0 with के साथ पंक्ति चुनें , पंक्तियों को UNION ALL VALUES . के साथ जोड़ें
UPDATE foo f
SET x = t.x
, y = t.y
FROM (
(SELECT pkid, x, y FROM foo LIMIT 0) -- parenthesis needed with LIMIT
UNION ALL
VALUES
(1, 20, NULL) -- no type casts here
, (2, 50, NULL)
) t -- column names and types are already defined
WHERE f.pkid = t.pkid;
सबक्वेरी का पहला उप-चयन:
(SELECT x, y, pkid FROM foo LIMIT 0)
कॉलम के लिए नाम और प्रकार मिलते हैं, लेकिन LIMIT 0 इसे वास्तविक पंक्ति जोड़ने से रोकता है। बाद की पंक्तियों को अब अच्छी तरह से परिभाषित पंक्ति प्रकार के लिए मजबूर किया जाता है - और तुरंत जाँच की जाती है कि क्या वे प्रकार से मेल खाते हैं। आपके मूल रूप में एक सूक्ष्म अतिरिक्त सुधार होना चाहिए।
सभी . के लिए मान प्रदान करते समय तालिका के कॉलम इस संक्षिप्त सिंटैक्स का उपयोग पहली पंक्ति के लिए किया जा सकता है:
(TABLE foo LIMIT 0)
प्रमुख सीमा :पोस्टग्रेज फ्री-स्टैंडिंग VALUES . के इनपुट अक्षर को कास्ट करता है अभिव्यक्ति को तुरंत "सर्वोत्तम-प्रयास" प्रकार के लिए। जब यह बाद में दिए गए प्रकार के पहले SELECT . को कास्ट करने का प्रयास करता है , कुछ प्रकारों के लिए पहले से ही बहुत देर हो सकती है यदि कल्पित प्रकार और लक्ष्य प्रकार के बीच कोई पंजीकृत असाइनमेंट कास्ट नहीं है। उदाहरण:text -> timestamp या text -> json ।
प्रो:
- न्यूनतम ओवरहेड।
- पठनीय, सरल और तेज़।
- आपको केवल तालिका के प्रासंगिक कॉलम नाम जानने की आवश्यकता है।
कॉन:
- टाइप रिजोल्यूशन कुछ प्रकार के लिए विफल हो सकता है।
LIMIT 0 with के साथ पंक्ति चुनें , पंक्तियों को UNION ALL SELECT . के साथ जोड़ें UPDATE foo f
SET x = t.x
, y = t.y
FROM (
(SELECT pkid, x, y FROM foo LIMIT 0) -- parenthesis needed with LIMIT
UNION ALL SELECT 1, 20, NULL
UNION ALL SELECT 2, 50, NULL
) t -- column names and types are already defined
WHERE f.pkid = t.pkid;
प्रो:
- पसंद 0. , लेकिन असफल प्रकार के समाधान से बचा जाता है।
कॉन:
UNION ALL SELECTVALUES. से धीमा है पंक्तियों की लंबी सूचियों के लिए अभिव्यक्ति, जैसा कि आपने अपने परीक्षण में पाया।- प्रति पंक्ति क्रिया वाक्य रचना।
VALUES प्रति-स्तंभ प्रकार के साथ व्यंजक ...
FROM (
VALUES
((SELECT pkid FROM foo LIMIT 0)
, (SELECT x FROM foo LIMIT 0)
, (SELECT y FROM foo LIMIT 0)) -- get type for each col individually
, (1, 20, NULL)
, (2, 50, NULL)
) t (pkid, x, y) -- columns names not defined yet, only types.
...
0. . के विपरीत यह समयपूर्व प्रकार के समाधान से बचा जाता है।
VALUES . में पहली पंक्ति अभिव्यक्ति NULL . की एक पंक्ति है वे मान जो बाद की सभी पंक्तियों के प्रकार को परिभाषित करते हैं। इस प्रमुख शोर पंक्ति को WHERE f.pkid = t.pkid द्वारा फ़िल्टर किया जाता है बाद में, इसलिए यह कभी भी दिन के उजाले को नहीं देखता है। अन्य उद्देश्यों के लिए आप OFFSET 1 . के साथ जोड़ी गई पहली पंक्ति को समाप्त कर सकते हैं एक सबक्वेरी में।
प्रो:
- आमतौर पर 1. . से तेज (या यहां तक कि 0. )
- कई स्तंभों वाली तालिकाओं के लिए संक्षिप्त सिंटैक्स और केवल कुछ ही प्रासंगिक हैं।
- आपको केवल तालिका के प्रासंगिक कॉलम नाम जानने की आवश्यकता है।
कॉन:
- केवल कुछ पंक्तियों के लिए वर्बोज़ सिंटैक्स
- कम पठनीय (आईएमओ)।
VALUES पंक्ति प्रकार के साथ अभिव्यक्ति UPDATE foo f
SET x = (t.r).x -- parenthesis needed to make syntax unambiguous
, y = (t.r).y
FROM (
VALUES
('(1,20,)'::foo) -- columns need to be in default order of table
,('(2,50,)') -- nothing after the last comma for NULL
) t (r) -- column name for row type
WHERE f.pkid = (t.r).pkid;
आप स्पष्ट रूप से तालिका का नाम जानते हैं। यदि आप स्तंभों की संख्या और उनका क्रम भी जानते हैं तो आप इसके साथ काम कर सकते हैं।
PostgreSQL में प्रत्येक तालिका के लिए एक पंक्ति प्रकार स्वचालित रूप से पंजीकृत होता है। यदि आप अपने व्यंजक में स्तंभों की संख्या से मेल खाते हैं, तो आप तालिका के पंक्ति प्रकार पर कास्ट कर सकते हैं ('(1,50,)'::foo ) इस प्रकार स्तंभ प्रकारों को परोक्ष रूप से निर्दिष्ट करना। NULL . दर्ज करने के लिए अल्पविराम के पीछे कुछ भी न रखें मूल्य। प्रत्येक अप्रासंगिक अनुगामी स्तंभ के लिए अल्पविराम जोड़ें।
अगले चरण में आप प्रदर्शित सिंटैक्स के साथ अलग-अलग स्तंभों तक पहुंच सकते हैं। फ़ील्ड चयन के बारे में अधिक जानकारी मैनुअल में।
या आप जोड़ सकते हैं NULL मानों की एक पंक्ति और वास्तविक डेटा के लिए एक समान सिंटैक्स का उपयोग करें:
...
VALUES
((NULL::foo)) -- row of NULL values
, ('(1,20,)') -- uniform ROW value syntax for all
, ('(2,50,)')
...
प्रो:
- सबसे तेज़ (कम से कम मेरे परीक्षणों में कुछ पंक्तियों और स्तंभों के साथ)।
- कुछ पंक्तियों या तालिकाओं के लिए सबसे छोटा सिंटैक्स जहां आपको सभी स्तंभों की आवश्यकता होती है।
- आपको तालिका के स्तंभों की वर्तनी बताने की आवश्यकता नहीं है - सभी स्तंभों में स्वतः मिलान नाम होता है।
कॉन:
- रिकॉर्ड/पंक्ति/संयुक्त प्रकार से फ़ील्ड चयन के लिए इतना प्रसिद्ध सिंटैक्स नहीं है।
- आपको डिफ़ॉल्ट क्रम में प्रासंगिक स्तंभों की संख्या और स्थिति जानने की आवश्यकता है।
VALUES विघटित . के साथ व्यंजक पंक्ति प्रकार जैसे 3. , लेकिन मानक सिंटैक्स में विघटित पंक्तियों के साथ:
UPDATE foo f
SET x = t.x
, y = t.y
FROM (
VALUES
(('(1,20,)'::foo).*) -- decomposed row of values
, (2, 50, NULL)
) t(pkid, x, y) -- arbitrary column names (I made them match)
WHERE f.pkid = t.pkid; -- eliminates 1st row with NULL values
या, NULL मानों की एक अग्रणी पंक्ति के साथ फिर से:
...
VALUES
((NULL::foo).*) -- row of NULL values
, (1, 20, NULL) -- uniform syntax for all
, (2, 50, NULL)
...
पेशेवरों और विपक्ष जैसे 3. , लेकिन अधिक सामान्य रूप से ज्ञात सिंटैक्स के साथ।
और आपको कॉलम नामों की वर्तनी की आवश्यकता है (यदि आपको उनकी आवश्यकता है)।
5. VALUES पंक्ति प्रकार से प्राप्त प्रकार के साथ अभिव्यक्ति
जैसे अनरिल ने टिप्पणी की, हम 2. . के गुणों को जोड़ सकते हैं और 4. कॉलम का केवल एक सबसेट प्रदान करने के लिए:
UPDATE foo f
SET ( x, y)
= (t.x, t.y) -- short notation, see below
FROM (
VALUES
((NULL::foo).pkid, (NULL::foo).x, (NULL::foo).y) -- subset of columns
, (1, 20, NULL)
, (2, 50, NULL)
) t(pkid, x, y) -- arbitrary column names (I made them match)
WHERE f.pkid = t.pkid;
पेशेवरों और विपक्ष जैसे 4. , लेकिन हम कॉलम के किसी भी सबसेट के साथ काम कर सकते हैं और पूरी सूची जानने की जरूरत नहीं है।
UPDATE के लिए संक्षिप्त सिंटैक्स भी प्रदर्शित कर रहा है स्वयं जो कई कॉलम वाले मामलों के लिए सुविधाजनक है। संबंधित:
- सभी स्तंभों का बल्क अपडेट
4. और 5. मेरे पसंदीदा हैं।
db<>फिडल यहाँ - सभी का प्रदर्शन