सारांश:
मैंने नीचे दिए गए परीक्षण डेटा सेट का उपयोग करके प्रत्येक क्वेरी को 10 बार चलाया ..
- एक बहुत बड़ा सबक्वेरी परिणाम सेट (100000 पंक्तियाँ)
- डुप्लिकेट पंक्तियां
- शून्य पंक्तियां
उपरोक्त सभी परिदृश्यों के लिए, दोनों IN और EXISTS समान तरीके से किया गया।
प्रदर्शन V3 डेटाबेस के बारे में कुछ जानकारी परीक्षण के लिए उपयोग किया जाता है। 20000 ग्राहकों के पास 1000000 ऑर्डर हैं, इसलिए प्रत्येक ग्राहक को ऑर्डर तालिका में यादृच्छिक रूप से डुप्लिकेट (10 से 100 की सीमा में) किया जाता है।
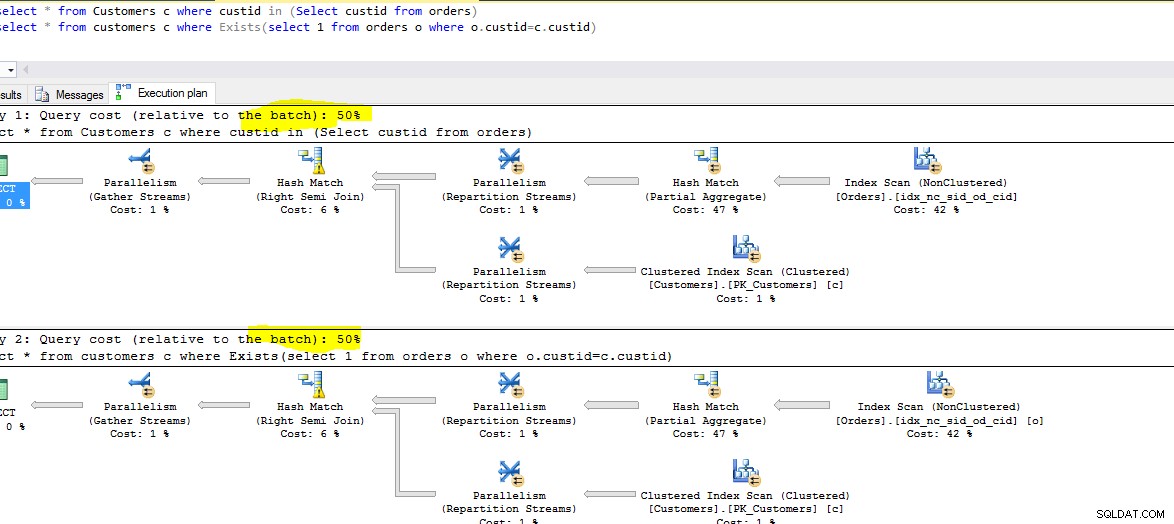
निष्पादन लागत, समय:
नीचे चल रहे दोनों प्रश्नों का स्क्रीनशॉट है। प्रत्येक क्वेरी सापेक्ष लागत का निरीक्षण करें।
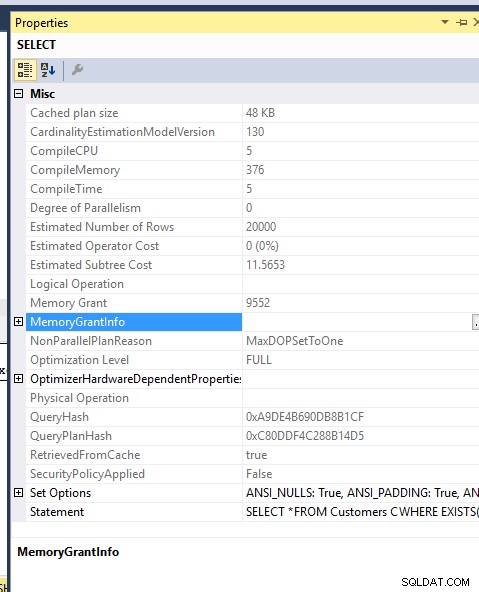
स्मृति लागत:
दो प्रश्नों के लिए मेमोरी ग्रांट भी समान है..मैंने MDOP 1 को बाध्य किया ताकि उन्हें TEMPDB तक न फैलाया जा सके..
CPU समय ,पढ़ता है:
अस्तित्व के लिए:
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 469 ms, elapsed time = 595 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
IN के लिए:
(20000 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 547 ms, elapsed time = 669 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
प्रत्येक मामले में, ऑप्टिमाइज़र प्रश्नों को पुनर्व्यवस्थित करने के लिए पर्याप्त स्मार्ट है।
मैं EXISTS . का उपयोग करता हूं केवल हालांकि (मेरी राय)। EXISTS use का उपयोग करने के लिए एक उपयोग का मामला जब आप दूसरी तालिका परिणाम सेट वापस नहीं करना चाहते हैं।
मार्टिन स्मिथ के प्रश्नों के अनुसार अपडेट करें:
मैंने पहली तालिका से पंक्तियों को प्राप्त करने का सबसे प्रभावी तरीका खोजने के लिए नीचे दिए गए प्रश्नों को चलाया, जिसके लिए दूसरी तालिका में एक संदर्भ मौजूद है।
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
SELECT *
FROM Customers C
WHERE EXISTS(SELECT 1 FROM Orders o WHERE o.custid = c.custid)
SELECT *
FROM Customers c
WHERE custid IN (SELECT custid FROM Orders)
दूसरे INNER JOIN . के अपवाद के साथ उपरोक्त सभी क्वेरीज़ की लागत समान है , बाकी के लिए समान होने की योजना बनाएं।
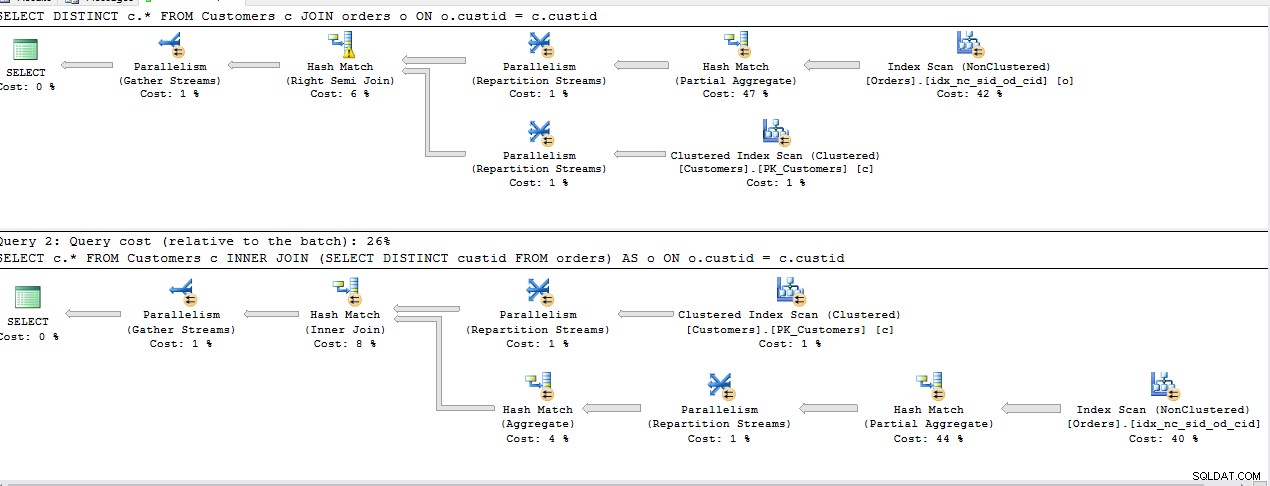
स्मृति अनुदान:
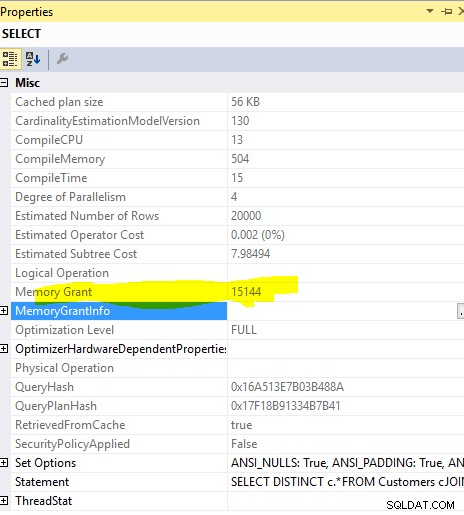
यह प्रश्न
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
आवश्यक स्मृति अनुदान
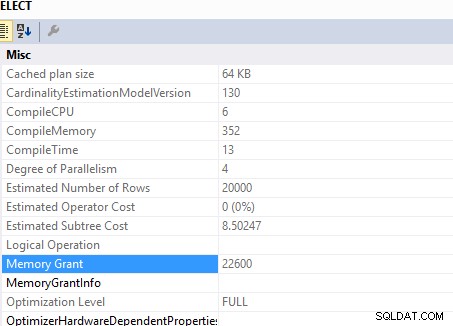
यह प्रश्न
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
आवश्यक स्मृति अनुदान ..
CPU समय, पढ़ता है:
प्रश्न के लिए:
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 48, logical reads 1344, physical reads 96, read-ahead reads 1248, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms, elapsed time = 781 ms.
प्रश्न के लिए:
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1499 ms, elapsed time = 403 ms.