समस्या का कारण :
TOKEN SSIS में विधि strtok . के कार्यान्वयन का उपयोग करती है C++ . में कार्य करता है . मैंने यह जानकारी Microsoft® SQL Server® 2012 इंटीग्रेशन सर्विसेज
को पढ़ते हुए एकत्रित की है। मजबूत>
. इसका उल्लेख पृष्ठ पर नोट के रूप में किया गया है 113 (मुझे यह पुस्तक पसंद है! बहुत सारी अच्छी जानकारी। )।
मैंने strtok . के कार्यान्वयन की खोज की समारोह और मुझे निम्नलिखित लिंक मिले।
जानकारी:strtok():C Function -- Documentation Supplement - इस लिंक में कोड नमूना दिखाता है कि फ़ंक्शन लगातार सीमांकक वर्णों को अनदेखा करता है।
निम्नलिखित SO प्रश्नों के उत्तर बताते हैं कि strtok फ़ंक्शन को लगातार सीमांकक को अनदेखा करने के लिए डिज़ाइन किया गया है।
यह जानने की जरूरत है कि strtok() का उपयोग करके दो टोकन विभाजकों के बीच कोई डेटा कब दिखाई नहीं देता है
strtok_s लगातार सीमांकक के साथ व्यवहार
मुझे लगता है कि TOKEN और TOKENCOUNT फ़ंक्शन डिज़ाइन के अनुसार काम कर रहे हैं लेकिन क्या SSIS को ऐसा व्यवहार करना चाहिए, यह Microsoft SSIS टीम के लिए एक प्रश्न हो सकता है।
मूल पोस्ट - उपरोक्त अनुभाग एक अपडेट है:
मैंने आपके डेटा इनपुट के आधार पर एसएसआईएस 2012 में एक साधारण पैकेज बनाया है। जैसा कि आपने अपने प्रश्न में वर्णित किया था, TOKEN कार्य इच्छित व्यवहार नहीं करता है। मैं आपसे सहमत हूं कि फ़ंक्शन काम नहीं कर रहा है। यह पोस्ट नहीं है आपके मूल मुद्दे का उत्तर।
यहाँ अपेक्षाकृत सरल तरीके से व्यंजक लिखने का एक वैकल्पिक तरीका दिया गया है। यह तभी काम करेगा जब आपके इनपुट रिकॉर्ड के अंतिम खंड का हमेशा एक मान होगा (जैसे A1 , B2 , C3 आदि)।
अभिव्यक्ति को फिर से लिखा जा सकता है :
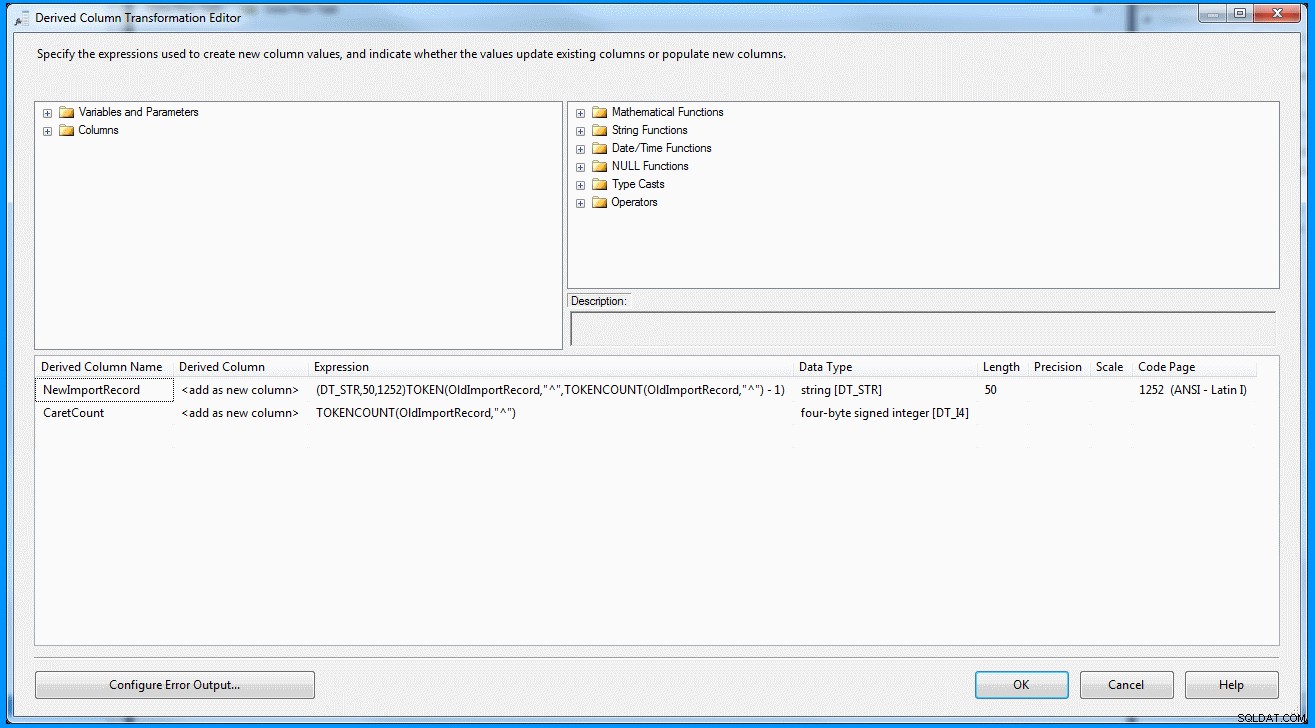
यह कथन इनपुट रिकॉर्ड को पैरामीटर के रूप में, सीमांकक कैरेट (^) को दूसरे पैरामीटर के रूप में लेगा। तीसरा पैरामीटर सीमांकक द्वारा विभाजित किए जाने पर रिकॉर्ड में कुल संख्या खंडों की गणना करता है। यदि आपके पास अंतिम सेगमेंट में डेटा है, तो आपके पास दो सेगमेंट होने की गारंटी है। फिर आप अंतिम खंड प्राप्त करने के लिए 1 घटा सकते हैं।
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
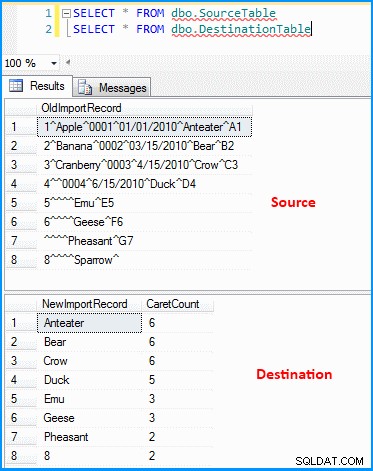
मैंने डेटा प्रवाह कार्य के साथ एक साधारण पैकेज बनाया है। OLE DB स्रोत डेटा और व्युत्पन्न परिवर्तन को पुनः प्राप्त करता है और नीचे दिए गए स्क्रीनशॉट के अनुसार डेटा को विभाजित करता है। आउटपुट तब गंतव्य तालिका में डाला जाता है। आप अंतिम स्क्रीनशॉट में स्रोत और गंतव्य तालिका देख सकते हैं। डेस्टिनेशन टेबल में दो कॉलम होते हैं। पहला कॉलम अंतिम खंड डेटा संग्रहीत करता है और खंड सीमांकक के आधार पर गणना करता है (जो फिर से सही नहीं है)। आप देख सकते हैं कि पिछले रिकॉर्ड ने सही परिणाम नहीं लाए। अगर पिछले रिकॉर्ड का मान 8 नहीं था , तो उपरोक्त व्यंजक विफल हो जाएगा क्योंकि व्यंजक का मूल्यांकन शून्य अनुक्रमणिका पर होगा।
आशा है कि यह आपकी अभिव्यक्ति को सरल बनाने में मदद करता है।
यदि आप किसी और से नहीं सुनते हैं, तो मैं इस समस्या को Microsoft Connect वेबसाइट ।
तालिका बनाएं और स्क्रिप्ट भरें :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
डेटा प्रवाह कार्य के अंदर व्युत्पन्न स्तंभ रूपांतरण :
स्रोत और गंतव्य तालिका में डेटा :