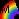अपडेट करें:
मेरे ब्लॉग में यह आलेख मेरे उत्तर और मेरी टिप्पणियों दोनों को अन्य उत्तरों में सारांशित करता है, और वास्तविक निष्पादन योजनाओं को दिखाता है:
SELECT *
FROM a
WHERE a.c IN (SELECT d FROM b)
SELECT a.*
FROM a
JOIN b
ON a.c = b.d
ये प्रश्न समकक्ष नहीं हैं। यदि आपकी तालिका b . है तो वे भिन्न परिणाम प्राप्त कर सकते हैं कुंजी संरक्षित नहीं है (यानी b.d . के मान अद्वितीय नहीं हैं)।
पहली क्वेरी के समतुल्य निम्नलिखित है:
SELECT a.*
FROM a
JOIN (
SELECT DISTINCT d
FROM b
) bo
ON a.c = bo.d
अगर b.d UNIQUE है और इस तरह चिह्नित किया गया है (UNIQUE INDEX . के साथ) या UNIQUE CONSTRAINT ), तो ये प्रश्न समान हैं और संभवतः समान योजनाओं का उपयोग करेंगे, क्योंकि SQL Server इसे ध्यान में रखने के लिए पर्याप्त स्मार्ट है।
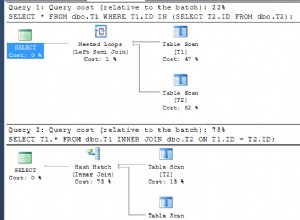
SQL Server इस क्वेरी को चलाने के लिए निम्न विधियों में से एक का उपयोग कर सकते हैं:
-
अगर
a.c. पर कोई इंडेक्स है ,dUNIQUEहै औरba. की तुलना में अपेक्षाकृत छोटा है , तब स्थिति को सबक्वेरी और प्लेनINNER JOINमें प्रचारित किया जाता है उपयोग किया जाता है (b. के साथ) अग्रणी) -
यदि
b.d. पर कोई अनुक्रमणिका है तो औरdUNIQUEनहीं है , तो शर्त भी प्रचारित हो जाती है औरLEFT SEMI JOINप्रयोग किया जाता है। इसका उपयोग उपरोक्त स्थिति के लिए भी किया जा सकता है। -
यदि
b.d. दोनों पर कोई अनुक्रमणिका है तो औरa.cऔर वे बड़े हैं, फिरMERGE SEMI JOINउपयोग किया जाता है -
अगर किसी टेबल पर कोई इंडेक्स नहीं है, तो
b. पर एक हैश टेबल बनाई जाती है औरHASH SEMI JOINउपयोग किया जाता है।
न तो इन विधियों में से प्रत्येक बार पूरी सबक्वेरी का पुनर्मूल्यांकन करता है।
यह कैसे काम करता है, इस बारे में अधिक विवरण के लिए मेरे ब्लॉग में इस प्रविष्टि को देखें:
सभी RDBMS . के लिए लिंक हैं बड़े चार में से।