ROW_NUMBER() का इस्तेमाल करें
. पहले प्रत्येक रिकॉर्ड को एक पंक्ति संख्या निर्दिष्ट करें:
SELECT cca.ClientContactId,
a.Description,
RowNumber = ROW_NUMBER() OVER(PARTITION BY cca.ClientContactId
ORDER BY a.AttributeId)
FROM ClientContactAttributes AS cca
INNER JOIN Attributes AS a
ON a.AttributeId = cca.AttributeId;
फिर आप इस RowNumber . का उपयोग कर सकते हैं कॉलम से PIVOT
आपका डेटा:
WITH Data AS
( SELECT cca.ClientContactId,
a.Description,
RowNumber = ROW_NUMBER() OVER(PARTITION BY cca.ClientContactId
ORDER BY a.AttributeId)
FROM ClientContactAttributes AS cca
INNER JOIN Attributes AS a
ON a.AttributeId = cca.AttributeId
)
SELECT pvt.ClientContactID,
Attribute1 = pvt.[1],
Attribute2 = pvt.[2],
Attribute3 = pvt.[3],
Attribute4 = pvt.[4]
FROM Data
PIVOT
( MAX(Description)
FOR RowNumber IN ([1], [2], [3], [4])
) AS pvt;
संपादित करें
अगर आप नहीं समझे तो मैंने ठीक से जवाब नहीं दिया! मैं कहावत में दृढ़ आस्तिक हूं "एक आदमी को एक मछली दो और तुम उसे एक दिन के लिए खिलाओ; एक आदमी को मछली पकड़ना सिखाओ और तुम उसे जीवन भर खिलाओ"
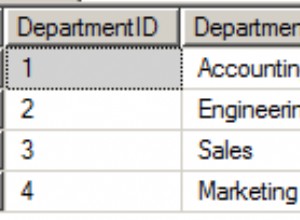
यदि आपकी दो तालिकाओं में निम्न डेटा है:
विशेषताएं '
AttributeId | Description
------------+---------------
1 | Bed
2 | Bath
3 | Beyond
ClientContactAttributes
ClientContactID | AttributeId
----------------+---------------
1 | 1
1 | 2
1 | 3
2 | 1
निम्नलिखित चल रहा है:
SELECT cca.ClientContactId,
a.Description,
RowNumber = ROW_NUMBER() OVER(PARTITION BY cca.ClientContactId
ORDER BY a.AttributeId)
FROM ClientContactAttributes AS cca
INNER JOIN Attributes AS a
ON a.AttributeId = cca.AttributeId;
आपको देंगे:
ClientContactID | Description | RowNumber
----------------+-------------+-----------
1 | Bed | 1
1 | Bath | 2
1 | Beyond | 3
2 | Bed | 1
ROW_NUMBER() फ़ंक्शन बस प्रत्येक समूह को एक अद्वितीय संख्या प्रदान करता है (PARTITION BY . में परिभाषित) क्लॉज), और यह संख्या ORDER BY . द्वारा निर्धारित की जाती है खंड। तो यह पंक्ति:
ROW_NUMBER() OVER(PARTITION BY cca.ClientContactId ORDER BY a.AttributeId)
अनिवार्य रूप से कह रहा है, cca.ClientContactId . के प्रत्येक अद्वितीय मान के लिए मुझे एक अद्वितीय संख्या चाहिए, जो 1 से शुरू हो, जहां attributeId . का न्यूनतम मान हो 1 प्राप्त करता है और वहां से संख्या में वृद्धि होती है:
PIVOT फ़ंक्शन, एक्सेल पिवट टेबल की तरह है, जहाँ आप पंक्तियों को कॉलम में बदलना चाहते हैं। इसके दो मूलभूत भाग हैं, और मैं यहाँ पीछे की ओर काम करूँगा। पहला भाग FOR . है खंड:
FOR RowNumber IN ([1], [2], [3], [4])
यह RowNumber . से मान है कॉलम जिसे आप पंक्तियों में बदलना चाहते हैं। कॉलम नाम प्रदान किए गए मानों के अनुरूप होंगे। दूसरा भाग (पहले तार्किक रूप से पढ़ना), उन मूल्यों को परिभाषित करता है जो इन नव निर्मित स्तंभों में जाएंगे। यह एक समग्र कार्य होना चाहिए, और इस मामले में यह है:
MAX(Description)
चूँकि आप पहले से ही जानते हैं कि RowNumber प्रत्येक ClientContactId . के लिए अद्वितीय है , समग्र कार्य (जो PIVOT` के लिए आवश्यक है) वास्तव में अर्थहीन है, क्योंकि विवरण के लिए केवल एक ही मान है।
उम्मीद है कि यह थोड़ा और समझ में आता है।