शायद अब तक आपको अपने प्रश्न का उत्तर मिल गया होगा। यह उत्तर दूसरों की मदद करने के लिए है जो इस प्रश्न पर ठोकर खा सकते हैं। यहां एक संभावित विकल्प दिया गया है जिसका उपयोग SSIS का उपयोग करके डेटा स्थानांतरण को हल करने के लिए किया जा सकता है। मैंने मान लिया था कि आप अभी भी SSIS पैकेज से अपने सर्वर A और B दोनों की ओर इशारा करते हुए कनेक्शन स्ट्रिंग बना सकते हैं। अगर वह धारणा गलत है, तो कृपया मुझे बताएं ताकि मैं इस उत्तर को हटा सकूं। इस उदाहरण में, मैं SQL Server 2008 R2 का उपयोग कर रहा हूं बैक-एंड के रूप में। चूंकि मेरे पास दो सर्वर नहीं हैं, इसलिए मैंने अलग-अलग Schemas . में दो समान तालिकाएं बनाई हैं सर्वरए और सर्वरB .
चरण-दर-चरण प्रक्रिया:
-
Connection manager. में SSIS के अनुभाग में, दो OLE DB कनेक्शन बनाएं, अर्थात् ServerA और सर्वरB . यह उदाहरण एक ही सर्वर को इंगित कर रहा है लेकिन आपके परिदृश्य में, कनेक्शन को आपके दो अलग-अलग सर्वरों को इंगित करने की आवश्यकता होगी। स्क्रीनशॉट देखें #1 । -
दो स्कीमा बनाएं
ServerAऔरServerB. तालिका बनाएंdbo.ItemInfoदोनों स्कीमा में। इन तालिकाओं के लिए स्क्रिप्ट बनाएं स्क्रिप्ट . के अंतर्गत दिए गए हैं खंड। फिर से, ये ऑब्जेक्ट केवल इस उदाहरण के लिए हैं। -
मैंने कुछ नमूना डेटा के साथ दोनों टेबलों को पॉप्युलेट किया है। तालिका
ServerA.ItemInfoइसमें2,222 rowsहैं और तालिकाServerB.ItemInfoइसमें10,000 rowsशामिल हैं . प्रश्न के अनुसार, लापता 7,778 पंक्तियों कोServerB. से स्थानांतरित किया जाना चाहिए करने के लिएServerA. स्क्रीनशॉट देखें #2 । -
SSIS पैकेज के कंट्रोल फ़्लो टैब पर, डेटा फ़्लो टास्क रखें जैसा कि स्क्रीनशॉट #3 में दिखाया गया है .
-
डेटा प्रवाह टैब पर नेविगेट करने के लिए डेटा प्रवाह कार्य पर डबल-क्लिक करें और नीचे बताए अनुसार डेटा प्रवाह कार्य को कॉन्फ़िगर करें। सर्वर B एक
OLE DB Sourceहै; सर्वर A में रिकॉर्ड खोजें एकLookup transformation taskऔर सर्वर ए एकOLE DB Destinationहै । -
कॉन्फ़िगर करें
OLE DB Sourceसर्वर B जैसा कि स्क्रीनशॉट में दिखाया गया है #4 और #5 । -
कॉन्फ़िगर करें
Lookup transformation taskसर्वर A में रिकॉर्ड खोजें जैसा कि स्क्रीनशॉट में दिखाया गया है #6 - #8 . इस उदाहरण में, ItemId अद्वितीय कुंजी है। इसलिए, वह कॉलम है जिसका उपयोग दो तालिकाओं के बीच लापता रिकॉर्ड की खोज के लिए किया जाता है। चूँकि हमें केवल उन पंक्तियों की आवश्यकता है जो सर्वर A . में मौजूद नहीं हैं , हमें विकल्प का चयन करने की आवश्यकता हैRedirect rows to no match output। -
एक
OLE DB Destinationरखें डेटा प्रवाह कार्य पर। जब आप लुकअप रूपांतरण कार्य को OLE DB गंतव्य से जोड़ते हैं, तो आपकोInput Output Selectionके साथ संकेत दिया जाएगा संवाद।Lookup No Match Outputचुनें संवाद से जैसा कि स्क्रीनशॉट #9 . में दिखाया गया है .OLE DB Destinationकॉन्फ़िगर करें सर्वर ए जैसा कि स्क्रीनशॉट में दिखाया गया है #10 और #11 । -
एक बार डेटा प्रवाह कार्य कॉन्फ़िगर हो जाने पर, यह वैसा ही दिखना चाहिए जैसा स्क्रीनशॉट में दिखाया गया है #12 ।
-
पैकेज का नमूना निष्पादन स्क्रीनशॉट #13 . में दिखाया गया है . जैसा कि आप देख सकते हैं, अनुपलब्ध
7,778 rowsServer B. से स्थानांतरित कर दिया गया हैServer A. के लिए . स्क्रीनशॉट देखें #14 पैकेज निष्पादन के बाद तालिका रिकॉर्ड गिनती देखने के लिए। -
चूंकि आवश्यकता केवल लापता रिकॉर्ड डालने की थी, इसलिए इस दृष्टिकोण का उपयोग किया गया है। यदि आप मौजूदा रिकॉर्ड्स को अपडेट करना चाहते हैं और उन रिकॉर्ड्स को हटाना चाहते हैं जो अब मान्य नहीं हैं, तो कृपया उस उदाहरण को देखें जो मैंने इस लिंक। टैब सीमांकित फ़ाइल लोड करने के लिए SQL एकीकरण सेवाएँ? लिंक में उदाहरण दिखाता है कि एक फ्लैट फ़ाइल को SQL में कैसे स्थानांतरित किया जाए, लेकिन यह मौजूदा रिकॉर्ड को अपडेट करता है और अमान्य रिकॉर्ड को हटा देता है। साथ ही, बड़ी संख्या में पंक्तियों को संभालने के लिए उदाहरण को ठीक से ट्यून किया गया है।
आशा है कि यह मदद करता है।
स्क्रिप्ट
।
CREATE SCHEMA [ServerA] AUTHORIZATION [dbo]
GO
CREATE SCHEMA [ServerB] AUTHORIZATION [dbo]
GO
CREATE TABLE [ServerA].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
CREATE TABLE [ServerB].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
स्क्रीनशॉट #1:
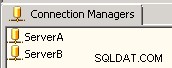
स्क्रीनशॉट #2:

स्क्रीनशॉट #3:

स्क्रीनशॉट #4:

स्क्रीनशॉट #5:

स्क्रीनशॉट #6:

स्क्रीनशॉट #7:

स्क्रीनशॉट #8:

स्क्रीनशॉट #9:

स्क्रीनशॉट #10:

स्क्रीनशॉट #11:

स्क्रीनशॉट #12:
स्क्रीनशॉट #13:

स्क्रीनशॉट #14: