SQL सर्वर ऑप्टिमाइज़र में अनावश्यक जुड़ावों को हटाने के लिए तर्क शामिल हैं, लेकिन प्रतिबंध हैं, और जुड़ने के लिए बिल्कुल बेमानी . संक्षेप में, एक जुड़ाव के चार प्रभाव हो सकते हैं:
- यह अतिरिक्त कॉलम जोड़ सकता है (शामिल तालिका से)
- यह अतिरिक्त पंक्तियों को जोड़ सकता है (शामिल तालिका स्रोत पंक्ति से एक से अधिक बार मेल खा सकती है)
- यह पंक्तियों को हटा सकता है (शामिल तालिका का मिलान नहीं हो सकता है)
- यह
NULLका परिचय दे सकता है s (RIGHT. के लिए याFULL JOIN)
एक अनावश्यक जुड़ाव को सफलतापूर्वक हटाने के लिए, क्वेरी (या दृश्य) को सभी चार संभावनाओं के लिए जिम्मेदार होना चाहिए। जब यह सही ढंग से किया जाता है, तो प्रभाव आश्चर्यजनक हो सकता है। उदाहरण के लिए:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
अनुकूलक निम्नलिखित क्वेरी को सफलतापूर्वक सरल बना सकता है:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
प्रति:

रॉब फ़ार्ले ने इन विचारों के बारे में मूल एमवीपी डीप डाइव्स बुक में गहराई से लिखा है। , और एक विषय पर उनके प्रस्तुतिकरण की रिकॉर्डिंग है। SQLBits पर।
मुख्य प्रतिबंध हैं कि विदेशी कुंजी संबंध एक ही कुंजी पर आधारित होनी चाहिए सरलीकरण प्रक्रिया में योगदान करने के लिए, और इस तरह के एक दृश्य के खिलाफ प्रश्नों के संकलन का समय काफी लंबा हो सकता है, खासकर जब जुड़ने की संख्या बढ़ जाती है। 100-तालिका दृश्य लिखना काफी चुनौतीपूर्ण हो सकता है जो सभी शब्दार्थों को बिल्कुल सही करता है। मैं एक वैकल्पिक समाधान खोजने के लिए इच्छुक हूं, शायद डायनामिक SQL का उपयोग करके। ।
उस ने कहा, आपकी असामान्य तालिका के विशेष गुणों का मतलब यह हो सकता है कि दृश्य को इकट्ठा करना काफी आसान है, केवल लागू की आवश्यकता है FOREIGN KEYs गैर-NULL सक्षम संदर्भित कॉलम, और उपयुक्त UNIQUE योजना में 100 फिजिकल जॉइन ऑपरेटरों के ओवरहेड के बिना, इस समाधान को आपकी आशा के अनुरूप काम करने के लिए बाधाएं।
उदाहरण
सौ के बजाय दस टेबल का उपयोग करना:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
पैरेंट टेबल की परिभाषा (पेज-संपीड़न के साथ):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
दृश्य:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
आँकड़ों को हैक करें ताकि अनुकूलक को लगे कि तालिका बहुत बड़ी है:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
उदाहरण उपयोगकर्ता क्वेरी:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
हमें यह निष्पादन योजना देता है:
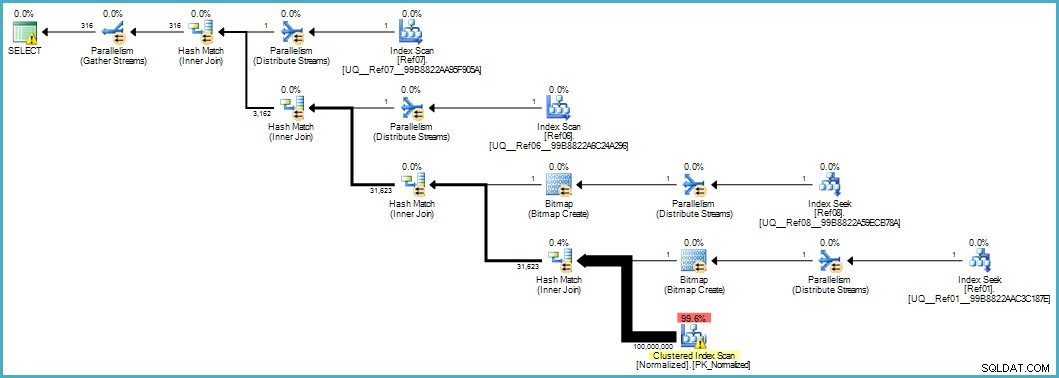
सामान्यीकृत तालिका का स्कैन खराब दिखता है, लेकिन दोनों ब्लूम-फ़िल्टर बिटमैप्स को स्टोरेज इंजन द्वारा स्कैन के दौरान लागू किया जाता है (इसलिए जो पंक्तियाँ मेल नहीं खा सकती हैं वे क्वेरी प्रोसेसर तक भी सतह पर नहीं आती हैं)। यह आपके मामले में स्वीकार्य प्रदर्शन देने के लिए पर्याप्त हो सकता है, और मूल तालिका को उसके अतिप्रवाहित स्तंभों के साथ स्कैन करने से निश्चित रूप से बेहतर है।
यदि आप किसी चरण में SQL Server 2012 एंटरप्राइज़ में अपग्रेड करने में सक्षम हैं, तो आपके पास एक और विकल्प है:सामान्यीकृत तालिका पर कॉलम-स्टोर इंडेक्स बनाना:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
निष्पादन योजना है:
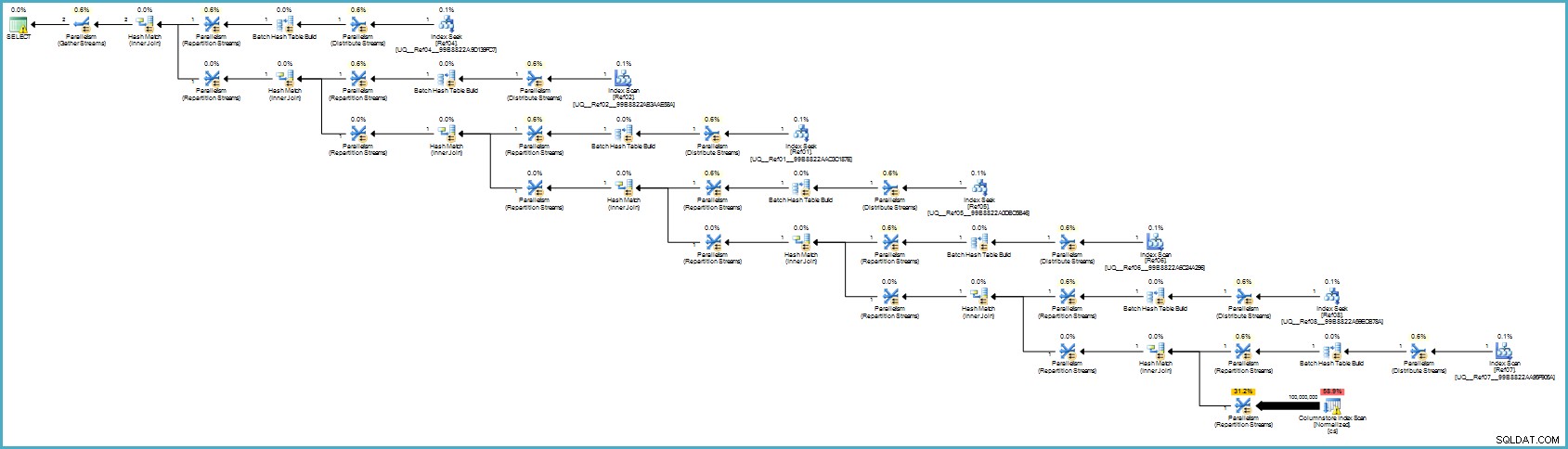
यह शायद आपके लिए बदतर लग रहा है, लेकिन कॉलम स्टोरेज असाधारण संपीड़न प्रदान करता है, और संपूर्ण निष्पादन योजना बैच मोड में सभी योगदान कॉलम के लिए फ़िल्टर के साथ चलती है। यदि सर्वर के पास पर्याप्त थ्रेड और मेमोरी उपलब्ध है, तो यह विकल्प वास्तव में उड़ सकता है।
आखिरकार, मुझे यकीन नहीं है कि टेबल की संख्या और खराब निष्पादन योजना प्राप्त करने की संभावना या अत्यधिक संकलन समय की आवश्यकता पर विचार करने के लिए यह सामान्यीकरण सही दृष्टिकोण है। मैं शायद पहले (उचित डेटा प्रकार और इसी तरह) denormalized तालिका की स्कीमा को सही कर दूंगा, संभवतः डेटा संपीड़न लागू कर सकता हूं ... सामान्य चीजें।
यदि डेटा वास्तव में एक स्टार-स्कीमा में है, तो शायद इसे अलग-अलग तालिकाओं में दोहराए जाने वाले डेटा तत्वों को विभाजित करने की तुलना में अधिक डिज़ाइन कार्य की आवश्यकता है।



