@PaulStock से पूरी तरह सहमत हैं कि समुच्चय स्रोत सिस्टम के लिए सबसे अच्छा छोड़ दिया गया है। एसएसआईएस में एक समुच्चय एक प्रकार की तरह पूरी तरह से अवरुद्ध घटक है और मेरे पास उस बिंदु पर पहले ही अपना तर्क दिया है ।
लेकिन कई बार सोर्स सिस्टम में उन ऑपरेशनों को करने से काम नहीं चलने वाला होता है। सबसे अच्छा मैं साथ आने में सक्षम हूं, मूल रूप से डेटा को डबल प्रोसेस करना है। हाँ, ick लेकिन मैं अप्रभावित के माध्यम से एक कॉलम को पारित करने का कोई तरीका नहीं खोज पाया। न्यूनतम/अधिकतम परिदृश्यों के लिए, मैं इसे एक विकल्प के रूप में चाहता हूं, लेकिन स्पष्ट रूप से योग जैसा कुछ घटक के लिए यह जानना कठिन बना देगा कि यह किस "स्रोत" पंक्ति से जुड़ा होगा।
2005
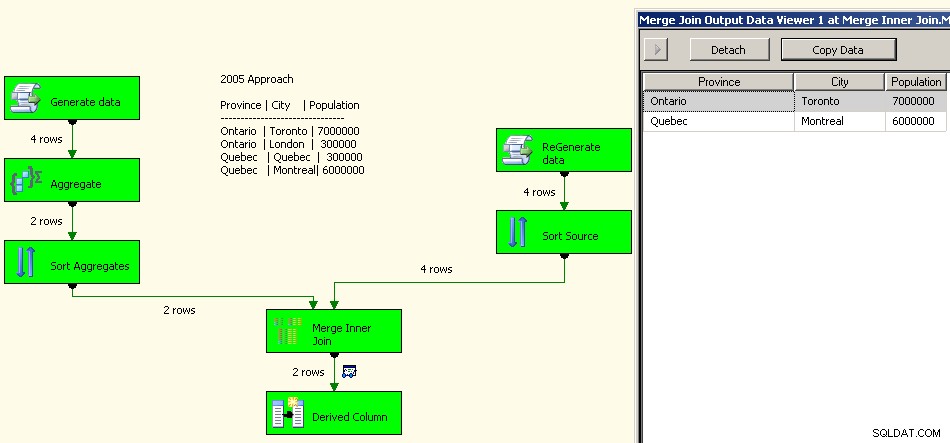
2005 का कार्यान्वयन इस तरह दिखेगा। आपका प्रदर्शन अच्छा नहीं होने वाला है, वास्तव में अच्छे से परिमाण के कुछ क्रम क्योंकि आपके पास अपने स्रोत डेटा को पुन:संसाधित करने के अलावा ये सभी अवरुद्ध परिवर्तन होंगे।
शामिल हों 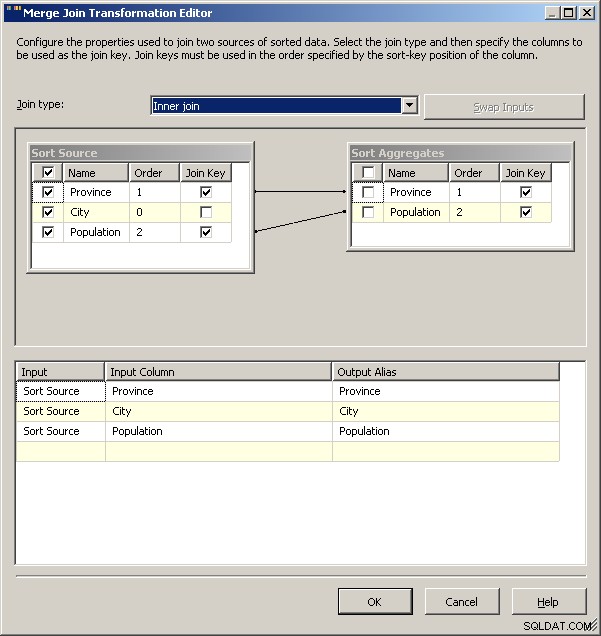
2008
2008 में, आपके पास कैश कनेक्शन मैनेजर का उपयोग करने का विकल्प है जो अवरुद्ध परिवर्तनों को खत्म करने में मदद करेगा, कम से कम जहां यह मायने रखता है, लेकिन आपको अभी भी अपने स्रोत डेटा को डबल प्रोसेस करने की लागत का भुगतान करना होगा।
दो डेटा प्रवाह को कैनवास पर खींचें। पहला कैश कनेक्शन मैनेजर को पॉप्युलेट करेगा और वहीं होना चाहिए जहां एग्रीगेट होता है।
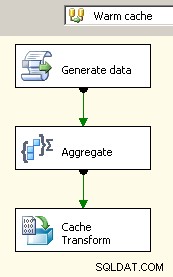
अब जबकि कैश में समेकित डेटा है, अपने मुख्य डेटा प्रवाह में एक लुकअप कार्य छोड़ें और कैश के विरुद्ध एक लुकअप करें।
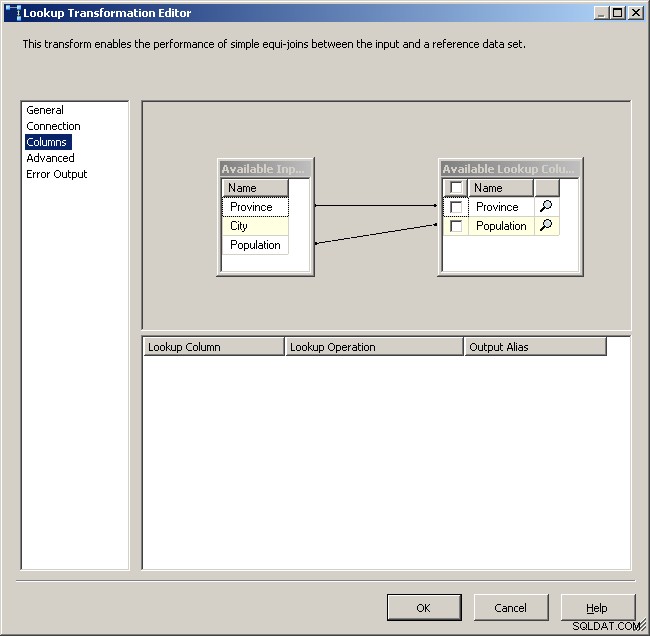
सामान्य लुकअप टैब
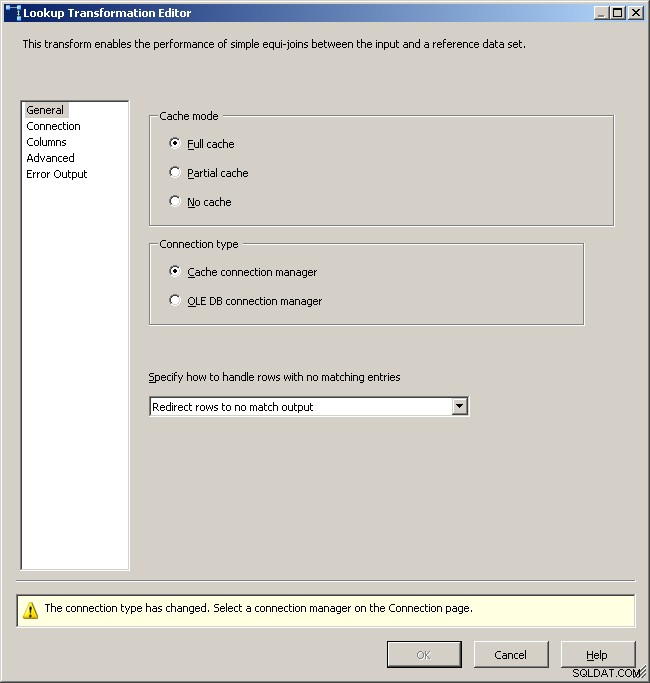
कैशे कनेक्शन प्रबंधक चुनें
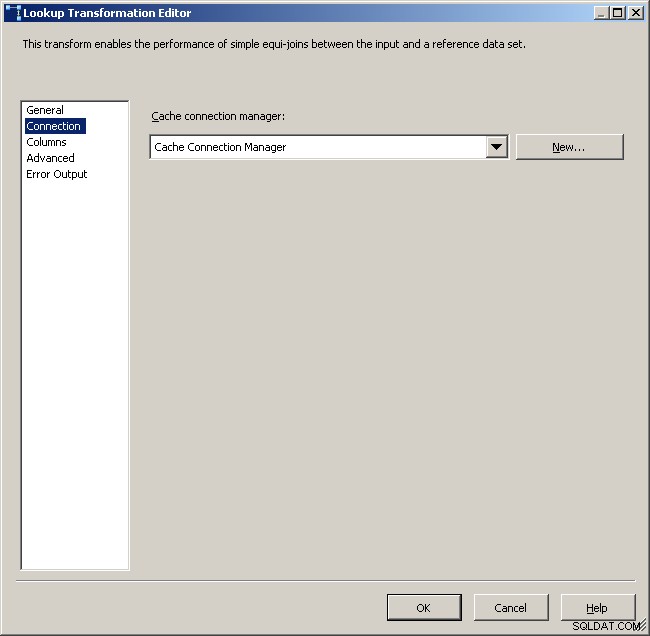
उपयुक्त कॉलम मैप करें
महान सफलता 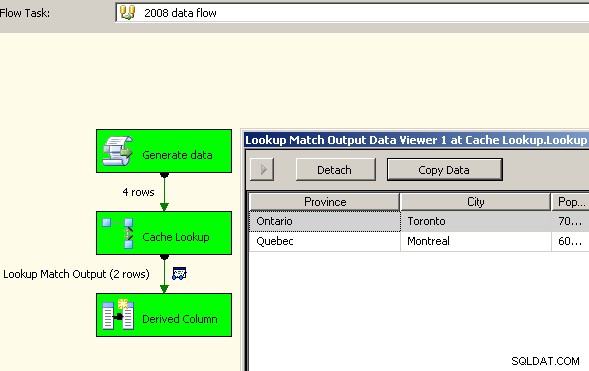
स्क्रिप्ट कार्य
तीसरा तरीका, जिसके बारे में मैं सोच सकता हूं, 2005 या 2008, यह है कि आप इसे स्वयं लिखें। एक सामान्य नियम के रूप में, मैं स्क्रिप्ट कार्यों से बचने की कोशिश करता हूं लेकिन यह एक ऐसा मामला है जहां यह शायद समझ में आता है। आपको इसे एक एसिंक्रोनस स्क्रिप्ट ट्रांसफ़ॉर्मेशन लेकिन बस वहां अपने एकत्रीकरण को संभालें। बनाए रखने के लिए अधिक कोड लेकिन आप अपने स्रोत डेटा को पुन:संसाधित करने की परेशानी से स्वयं को बचा सकते हैं।
अंत में, एक सामान्य चेतावनी के रूप में, मैं जांच करूंगा कि संबंधों का आपके समाधान पर क्या प्रभाव पड़ेगा। इस डेटा सेट के लिए, मुझे उम्मीद है कि गुएलफ जैसे कुछ अचानक से टोरंटो में सूजन और टाई करेंगे, लेकिन अगर ऐसा होता है, तो पैकेज को क्या करना चाहिए? अभी, दोनों का परिणाम ओंटारियो के लिए 2 पंक्तियों में होगा, लेकिन क्या यह अभीष्ट व्यवहार है? बेशक, स्क्रिप्ट आपको यह परिभाषित करने की अनुमति देती है कि संबंधों के मामले में क्या होता है। आप शायद "सामान्य" डेटा को कैश करके और अपनी लुकअप स्थिति के रूप में उपयोग करके और संबंधों में से केवल एक को वापस खींचने के लिए समुच्चय का उपयोग करके 2008 के समाधान को उसके सिर पर खड़ा कर सकते हैं। 2005 शायद मर्ज में शामिल होने के लिए बाएं स्रोत के रूप में कुल मिलाकर ऐसा ही कर सकता है
संपादन
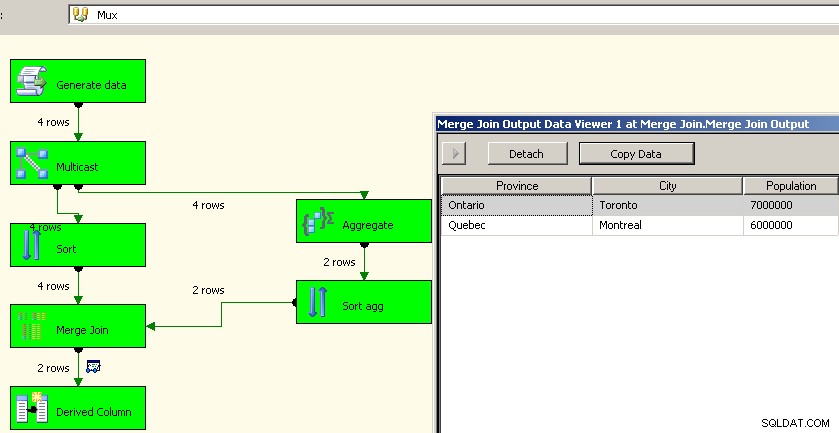
जेसन हॉर्नर ने अपनी टिप्पणी में एक अच्छा विचार रखा। एक मल्टीकास्ट परिवर्तन का उपयोग करने और एक स्ट्रीम में एकत्रीकरण करने और इसे वापस एक साथ लाने के लिए एक अलग दृष्टिकोण होगा। मैं यह नहीं समझ सका कि इसे एक संघ के साथ कैसे काम करना है, लेकिन हम उपरोक्त की तरह प्रकार और विलय में शामिल हो सकते हैं। यह शायद एक बेहतर तरीका है क्योंकि यह हमें स्रोत डेटा को पुन:संसाधित करने की परेशानी से बचाता है।