हो सकता है कि मुझे कुछ याद आ रहा हो लेकिन आपको डेटा को PIVOT करने में सक्षम होना चाहिए लेकिन आपको row_number() को लागू करने की आवश्यकता होगी कॉलम बनाने में मदद करने के लिए।
कुंजी इस तरह की क्वेरी का उपयोग करने के लिए होगी:
SELECT ONE.UserID,
ONE.Episode,
ONE.Value,
TWO.Details,
'Details'
+cast(row_number() over(partition by one.userid, one.episode
order by two.details) as varchar(10)) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
यह नए कॉलम नामों के लिए एक अद्वितीय अनुक्रम बनाएगा, फिर आप PIVOT लागू कर सकते हैं:
select userid, episode,
value,
details1,
details2
from
(
SELECT ONE.UserID,
ONE.Episode,
ONE.Value,
TWO.Details,
'Details'
+cast(row_number() over(partition by one.userid, one.episode
order by two.details) as varchar(10)) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
) d
pivot
(
max(details)
for seq in (Details1, Details2)
) piv;
देखें SQL Fiddle with Demo . फिर आप इसे डायनेमिक SQL में बदल सकते हैं:
DECLARE @cols AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX)
select @cols = STUFF((SELECT ',' + QUOTENAME('Details'+cast(seq as varchar(10)))
from
(
select
row_number() over(partition by one.userid, one.episode
order by two.details) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
) d
group by seq
order by seq
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')
set @query = 'SELECT userid, episode, value, ' + @cols + '
from
(
SELECT ONE.UserID,
ONE.Episode,
ONE.Value,
TWO.Details,
''Details''
+cast(row_number() over(partition by one.userid, one.episode
order by two.details) as varchar(10)) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
) x
pivot
(
max(details)
for seq in (' + @cols + ')
) p '
execute sp_executesql @query;
देखें SQL Fiddle with Demo . आपको परिणाम देना:
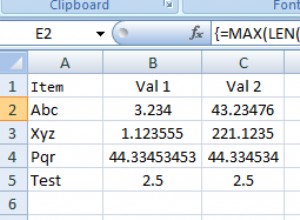
| USERID | EPISODE | VALUE | DETAILS1 | DETAILS2 |
|--------|---------|-----------|-----------|-----------|
| 1 | 1 | VALUE 1-1 | Details 1 | Details 2 |
| 1 | 2 | VALUE 1-2 | Details 1 | Details 2 |