नमस्ते,
SQL सर्वर डेटाबेस में इंडेक्स का उपयोग उन वातावरणों में होता है जिनमें सबसे अधिक प्रदर्शन, गति और मेमोरी बचत की आवश्यकता होती है।
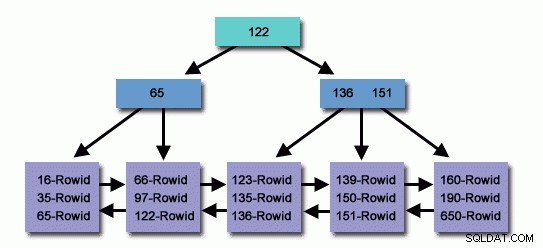
लाखों या अरबों रिकॉर्ड वाली तालिका में, हम कम रिकॉर्ड पढ़ने और संबंधित रिकॉर्ड खोजने के लिए कम खोज करने के लिए इंडेक्स का उपयोग कर सकते हैं।
सटीक रूप से बनाए गए इंडेक्स, डेटाबेस के भीतर लाखों रिकॉर्ड हमने कॉलर की सुविधा का रिकॉर्ड लाने के लिए बहुत ही कम समय के भीतर खोजे हैं, जबकि साथ ही लक्ष्य रिकॉर्ड तक पहुंचकर रिकॉर्ड कम पढ़ें, हम ऑपरेटिंग सिस्टम संसाधनों का प्रभावी ढंग से उपयोग करते हैं।
आपको टेबल पर ज्यादातर पढ़ने के लिए केवल प्रश्नों के लिए इंडेक्स बनाना चाहिए। यदि हटाएं, अद्यतन संचालन केवल पढ़ने के लिए प्रश्नों से अधिक हैं, तो आपको उस तालिका का अनुक्रमणिका नहीं बनाना चाहिए।
आप निम्न स्क्रिप्ट के साथ SQL सर्वर की अनुपलब्ध अनुक्रमणिका अनुशंसा को देख सकते हैं। आप लापता इंडेक्स बना सकते हैं लेकिन आपको इन इंडेक्स की निगरानी करनी चाहिए, अगर वे उपयोगी नहीं हैं, तो आपको उन्हें छोड़ देना चाहिए।
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;



