बहुत समय पहले, मैंने स्टैक एक्सचेंज पर NULL के बारे में एक प्रश्न का उत्तर दिया, जिसका शीर्षक था, "हमें NULLs की अनुमति क्यों नहीं देनी चाहिए?" मेरे पास पालतू जानवरों और जुनून का मेरा हिस्सा है, और एनयूएलएल का डर मेरी सूची में काफी ऊपर है। एक सहयोगी ने हाल ही में मुझसे कहा, NULL की अनुमति देने के बजाय एक खाली स्ट्रिंग को बाध्य करने की प्राथमिकता व्यक्त करने के बाद:
"मुझे कोड में नल से निपटना पसंद नहीं है।"
मुझे खेद है, लेकिन यह एक अच्छा कारण नहीं है। प्रेजेंटेशन लेयर खाली स्ट्रिंग्स से कैसे निपटता है या NULLs आपके टेबल डिज़ाइन और डेटा मॉडल के लिए ड्राइवर नहीं होना चाहिए। और अगर आप किसी कॉलम में "मूल्य की कमी" की अनुमति दे रहे हैं, तो क्या यह आपके लिए तार्किक दृष्टिकोण से मायने रखता है कि क्या "मूल्य की कमी" को शून्य-लंबाई वाले स्ट्रिंग या NULL द्वारा दर्शाया गया है? या इससे भी बदतर, पूर्णांकों के लिए 0 या -1 जैसे टोकन मान, या तारीखों के लिए 1900-01-01?
इत्ज़िक बेन-गण ने हाल ही में एनयूएलएल पर एक पूरी श्रृंखला लिखी है, और मैं अत्यधिक अनुशंसा करता हूं कि यह सब देखें:
- पूर्ण जटिलताएं - भाग 1
- पूर्ण जटिलताएं - भाग 2
- पूर्ण जटिलताएं - भाग 3, अनुपलब्ध मानक सुविधाएँ और T-SQL विकल्प
- पूर्ण जटिलताएं - भाग 4, मानक अद्वितीय बाधा अनुपलब्ध
लेकिन यहां मेरा उद्देश्य उससे थोड़ा कम जटिल है, जब विषय एक अलग स्टैक एक्सचेंज प्रश्न में आया था:"मौजूदा तालिका में एक ऑटो नाउ फ़ील्ड जोड़ें।" वहां, उपयोगकर्ता मौजूदा तालिका में एक नया कॉलम जोड़ रहा था, इसे वर्तमान दिनांक/समय के साथ ऑटो-पॉप्युलेट करने के इरादे से। उन्होंने सोचा कि क्या उन्हें सभी मौजूदा पंक्तियों के लिए उस कॉलम में NULLs छोड़ देना चाहिए या एक डिफ़ॉल्ट मान सेट करना चाहिए (जैसे 1900-01-01, संभवतः, हालांकि वे स्पष्ट नहीं थे)।
किसी के लिए टोकन मूल्य के आधार पर पुरानी पंक्तियों को फ़िल्टर करना आसान हो सकता है-आखिरकार, कोई कैसे विश्वास कर सकता है कि किसी प्रकार का ब्लूटूथ डूडैड 1900-01-01 को निर्मित या खरीदा गया था? ठीक है, मैंने इसे वर्तमान प्रणालियों में देखा है जहां वे जादू फिल्टर के रूप में कार्य करने के लिए कुछ मनमानी-ध्वनि वाली तारीख का उपयोग करते हैं, केवल उन पंक्तियों को प्रस्तुत करते हैं जहां मूल्य पर भरोसा किया जा सकता है। वास्तव में, हर मामले में मैंने अब तक देखा है, WHERE क्लॉज में तारीख वह तारीख/समय है जब कॉलम (या इसकी डिफ़ॉल्ट बाधा) जोड़ा गया था। जो सब ठीक है; शायद यह समस्या को हल करने का सबसे अच्छा तरीका नहीं है, लेकिन यह a . है रास्ता।
यदि आप दृश्य के माध्यम से तालिका तक नहीं पहुंच रहे हैं, हालांकि, ज्ञात . का यह निहितार्थ मूल्य अभी भी तार्किक और परिणाम-संबंधी दोनों समस्याओं का कारण बन सकता है। तार्किक समस्या बस यह है कि तालिका के साथ बातचीत करने वाले को 1900-01-01 को पता होना चाहिए कि एक फर्जी, टोकन मूल्य "अज्ञात" या "प्रासंगिक नहीं" का प्रतिनिधित्व करता है। वास्तविक दुनिया के उदाहरण के लिए, 1970 के दशक में खेले गए क्वार्टरबैक के लिए सेकंड में औसत रिलीज़ गति क्या थी, इससे पहले कि हम ऐसी चीज़ को मापें या ट्रैक करें? क्या 0 "अज्ञात" के लिए एक अच्छा टोकन मूल्य है? -1 के बारे में कैसे? या 100? तारीखों पर वापस जाना, अगर बिना आईडी वाला कोई मरीज अस्पताल में भर्ती हो जाता है और बेहोश हो जाता है, तो उन्हें जन्म तिथि के रूप में क्या दर्ज करना चाहिए? मुझे नहीं लगता कि 1900-01-01 एक अच्छा विचार है, और यह निश्चित रूप से एक अच्छा विचार नहीं था जब वास्तविक जन्मतिथि होने की अधिक संभावना थी।
टोकन मूल्यों का प्रदर्शन प्रभाव
प्रदर्शन के दृष्टिकोण से, नकली या "टोकन" मान जैसे 1900-01-01 या 9999-21-31 समस्याएं पेश कर सकते हैं। आइए इनमें से कुछ को ऊपर बताए गए हालिया प्रश्न पर आधारित एक उदाहरण के साथ देखें। हमारे पास एक विजेट तालिका है और कुछ वारंटी रिटर्न के बाद, हमने एक EnteredService कॉलम जोड़ने का निर्णय लिया है जहां हम नई पंक्तियों के लिए वर्तमान दिनांक/समय दर्ज करेंगे। एक मामले में हम सभी मौजूदा पंक्तियों को NULL के रूप में छोड़ देंगे, और दूसरे में हम मान को हमारी जादुई 1900-01-01 तारीख में अपडेट कर देंगे। (हम अभी के लिए बातचीत में किसी भी प्रकार की कमी को छोड़ देंगे।)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); अब हम हर टेबल में वही 100,000 पंक्तियां डालेंगे:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; फिर हम नया कॉलम जोड़ सकते हैं और मौजूदा मूल्यों के 10% को वर्तमान-ईश तिथियों के वितरण के साथ अपडेट कर सकते हैं, और अन्य 90% हमारी टोकन तिथि में केवल एक टेबल में अपडेट कर सकते हैं:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; अंत में, हम अनुक्रमणिका जोड़ सकते हैं:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
उपयोग की गई जगह
जब हम डेटा प्रकार विकल्पों, विखंडन, और टोकन मानों बनाम NULL के बारे में बात करते हैं तो मैं हमेशा "डिस्क स्थान सस्ता होता है" सुनता हूं। डिस्क स्थान के साथ मेरी चिंता इतनी अधिक नहीं है कि ये अतिरिक्त अर्थहीन मूल्य लेते हैं। यह अधिक है कि, जब तालिका से पूछताछ की जाती है, तो यह स्मृति बर्बाद कर रही है। यहां हम एक त्वरित विचार प्राप्त कर सकते हैं कि कॉलम और इंडेक्स जोड़े जाने से पहले और बाद में हमारे टोकन मान कितनी जगह का उपभोग करते हैं:
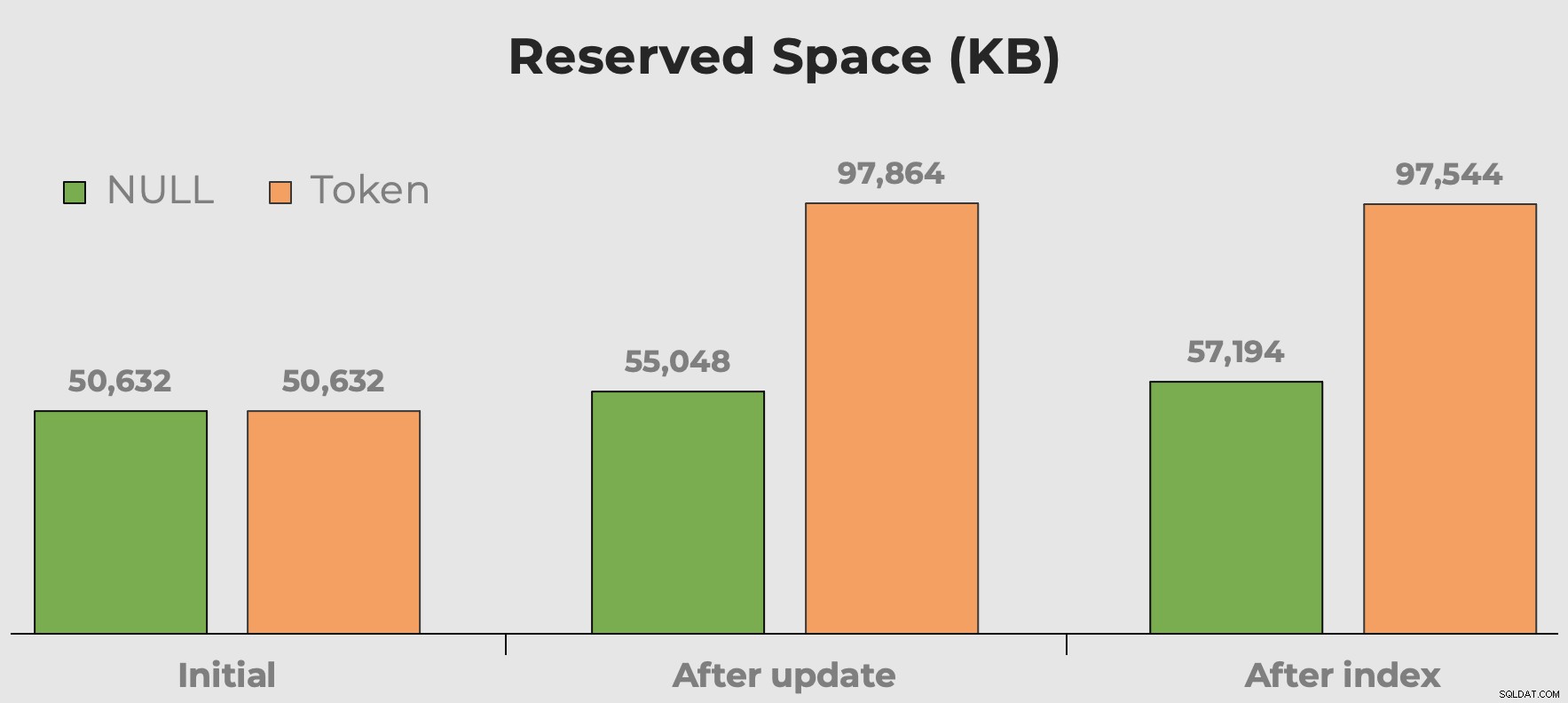 एक कॉलम जोड़ने और एक इंडेक्स जोड़ने के बाद टेबल का आरक्षित स्थान। टोकन मानों के साथ स्थान लगभग दोगुना हो जाता है।
एक कॉलम जोड़ने और एक इंडेक्स जोड़ने के बाद टेबल का आरक्षित स्थान। टोकन मानों के साथ स्थान लगभग दोगुना हो जाता है।
क्वेरी निष्पादन
अनिवार्य रूप से, कोई तालिका में डेटा के बारे में धारणा बनाने जा रहा है और EnteredService कॉलम के विरुद्ध क्वेरी करेगा जैसे कि सभी मान वैध हैं। उदाहरण के लिए:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; टोकन मान कुछ मामलों में अनुमानों के साथ खिलवाड़ कर सकते हैं, लेकिन इससे भी महत्वपूर्ण बात यह है कि वे गलत (या कम से कम अप्रत्याशित) परिणाम देने जा रहे हैं। यहाँ टोकन मानों वाली तालिका के विरुद्ध क्वेरी के लिए निष्पादन योजना है:
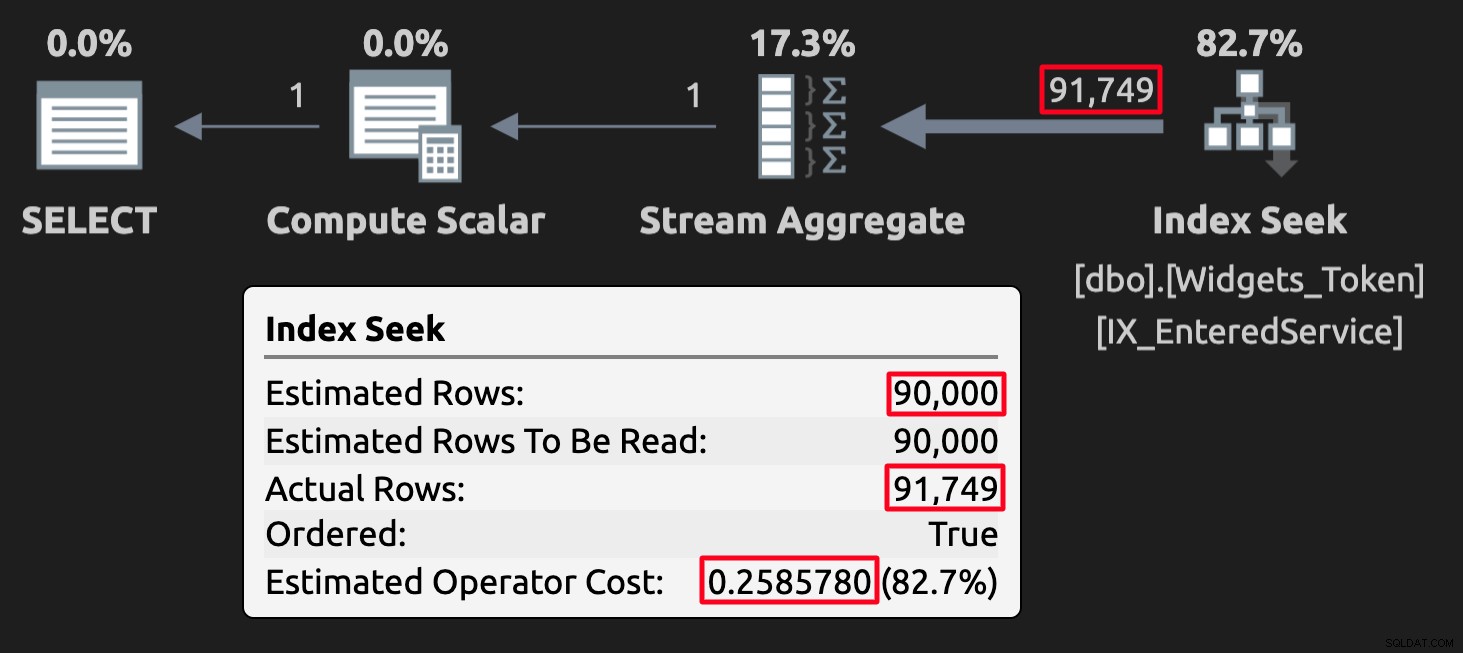 टोकन तालिका के लिए निष्पादन योजना; उच्च लागत पर ध्यान दें।
टोकन तालिका के लिए निष्पादन योजना; उच्च लागत पर ध्यान दें।
और यहाँ NULLs के साथ तालिका के विरुद्ध क्वेरी के लिए निष्पादन योजना है:
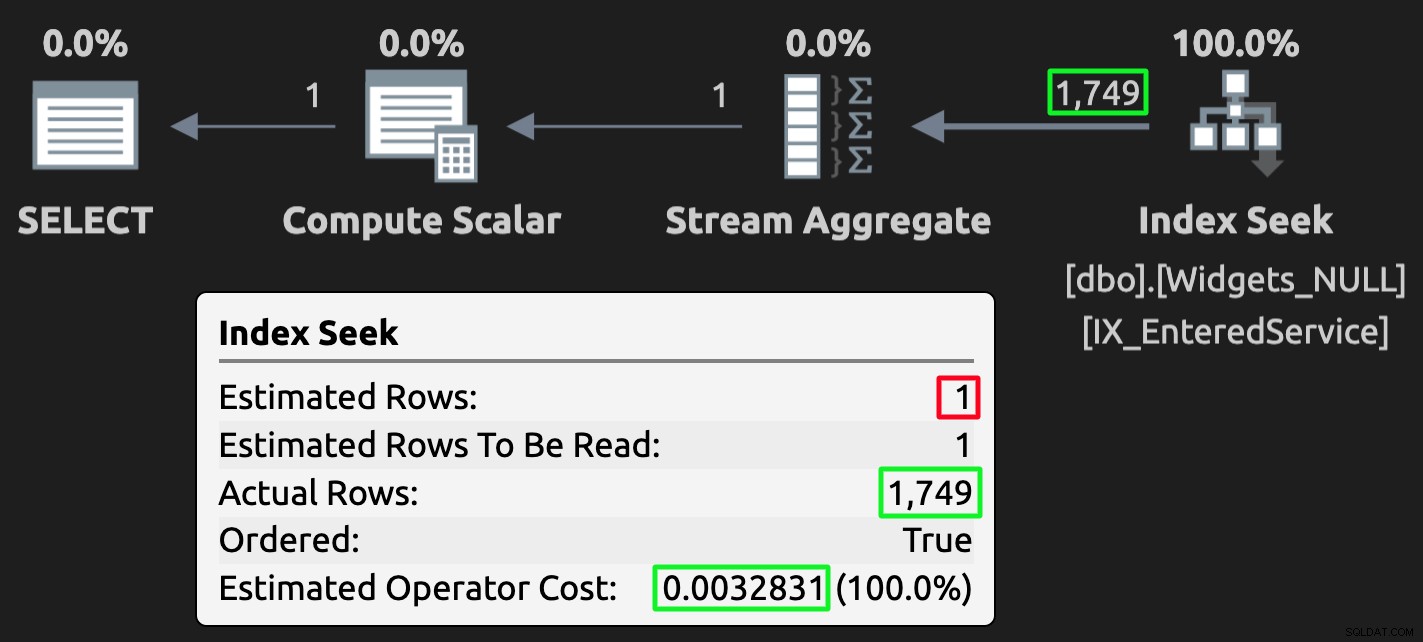 NULL तालिका के लिए निष्पादन योजना; गलत अनुमान, लेकिन बहुत कम लागत।
NULL तालिका के लिए निष्पादन योजना; गलत अनुमान, लेकिन बहुत कम लागत।
दूसरे तरीके से भी ऐसा ही होगा यदि>={some date} और 9999-12-31 के लिए पूछी गई क्वेरी का उपयोग अज्ञात का प्रतिनिधित्व करने वाले जादुई मूल्य के रूप में किया गया था।
फिर, उन लोगों के लिए जो परिणाम जानते हैं, विशेष रूप से गलत हैं क्योंकि आपने टोकन मूल्यों का उपयोग किया है, यह कोई समस्या नहीं है। लेकिन हर कोई जो यह नहीं जानता है - जिसमें भविष्य के सहकर्मी, कोड के अन्य उत्तराधिकारी और अनुरक्षक शामिल हैं, और यहां तक कि भविष्य में आपको स्मृति चुनौतियों के साथ-शायद ठोकर खाने वाला है।
निष्कर्ष
एक कॉलम में एनयूएलएल को अनुमति देने का विकल्प (या पूरी तरह से एनयूएलएल से बचने के लिए) को एक वैचारिक या भय-आधारित निर्णय में कम नहीं किया जाना चाहिए। यह सुनिश्चित करने के लिए कि कोई मूल्य NULL नहीं हो सकता है, या किसी ऐसी चीज़ का प्रतिनिधित्व करने के लिए अर्थहीन मानों का उपयोग करना, जिसे आसानी से संग्रहीत नहीं किया जा सकता था, आपके डेटा मॉडल को तैयार करने के लिए वास्तविक, मूर्त डाउनसाइड्स हैं। मैं सुझाव नहीं दे रहा हूं कि आपके मॉडल में प्रत्येक कॉलम को एनयूएलएल की अनुमति देनी चाहिए; सिर्फ इसलिए कि आप विचार . के विरोध में नहीं हैं NULLs की।