SQL सर्वर में समस्या निवारण के लिए अधिक परेशान करने वाली समस्याओं में से एक स्मृति अनुदान से संबंधित हो सकती है। कुछ प्रश्नों को निष्पादित करने के लिए दूसरों की तुलना में अधिक मेमोरी की आवश्यकता होती है, जो इस बात पर आधारित होती है कि किन कार्यों को करने की आवश्यकता है (जैसे सॉर्ट, हैश)। SQL सर्वर का ऑप्टिमाइज़र अनुमान लगाता है कि कितनी मेमोरी की आवश्यकता है, और क्वेरी को निष्पादन शुरू करने के लिए मेमोरी ग्रांट प्राप्त करनी चाहिए। यह क्वेरी निष्पादन की अवधि के लिए उस अनुदान को रखता है - जिसका अर्थ है कि यदि ऑप्टिमाइज़र स्मृति को अधिक महत्व देता है तो आप समवर्ती मुद्दों में भाग सकते हैं। यदि यह स्मृति को कम आंकता है, तो आप tempdb में स्पिल देख सकते हैं। दोनों में से कोई भी आदर्श नहीं है, और जब आपके पास अनुदान के लिए उपलब्ध मेमोरी से अधिक मेमोरी की मांग करने वाले बहुत अधिक प्रश्न हों, तो आप देखेंगे कि RESOURCE_SEMAPHORE प्रतीक्षा कर रहा है। इस मुद्दे पर हमला करने के कई तरीके हैं, और मेरी नई पसंदीदा विधियों में से एक क्वेरी स्टोर का उपयोग करना है।
सेटअप
हम वाइडवर्ल्ड आयातकों की एक प्रति का उपयोग करेंगे जिसे मैंने DataLoadSimulation.DailyProcessToCreateHistory संग्रहीत कार्यविधि का उपयोग करके फुलाया था। Sales.Orders तालिका में लगभग 4.6 मिलियन पंक्तियाँ हैं, और Sales.OrderLines तालिका में लगभग 9.2 मिलियन पंक्तियाँ हैं। हम बैकअप को पुनर्स्थापित करेंगे और क्वेरी स्टोर को सक्षम करेंगे, और किसी भी पुराने क्वेरी स्टोर डेटा को हटा देंगे ताकि हम इस डेमो के लिए किसी भी मीट्रिक में बदलाव न करें।
रिमाइंडर:ALTER DATABASE
USE [master]; GO RESTORE DATABASE [WideWorldImporters] FROM DISK = N'C:\Backups\WideWorldImporters.bak' WITH FILE = 1, MOVE N'WWI_Primary' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.mdf', MOVE N'WWI_UserData' TO N'C:\Databases\WideWorldImporters\WideWorldImporters_UserData.ndf', MOVE N'WWI_Log' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.ldf', NOUNLOAD, REPLACE, STATS = 5 GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, INTERVAL_LENGTH_MINUTES = 10 ); GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE CLEAR; GO
दिनांक सीमा के आधार पर उपरोक्त ऑर्डर और ऑर्डरलाइन तालिकाओं के प्रश्नों के परीक्षण के लिए हम संग्रहीत प्रक्रिया का उपयोग करेंगे:
USE [WideWorldImporters]; GO DROP PROCEDURE IF EXISTS [Sales].[usp_OrderInfo_OrderDate]; GO CREATE PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO
परीक्षण
हम इनपुट पैरामीटर के तीन अलग-अलग सेटों में संग्रहित प्रक्रिया को निष्पादित करेंगे:
EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
पहला निष्पादन 1958 पंक्तियों को लौटाता है, दूसरा 267,268 पंक्तियों को लौटाता है, और अंतिम 2.2 मिलियन से अधिक पंक्तियों को लौटाता है। यदि आप दिनांक सीमाओं को देखें, तो यह आश्चर्यजनक नहीं है - दिनांक सीमा जितनी बड़ी होगी, उतना ही अधिक डेटा लौटाया जाएगा।
क्योंकि यह एक संग्रहीत कार्यविधि है, प्रारंभ में उपयोग किए जाने वाले इनपुट पैरामीटर योजना के साथ-साथ दी जाने वाली स्मृति का निर्धारण करते हैं। यदि हम पहले निष्पादन के लिए वास्तविक निष्पादन योजना को देखें, तो हमें नेस्टेड लूप और 2656 KB का मेमोरी ग्रांट दिखाई देता है।
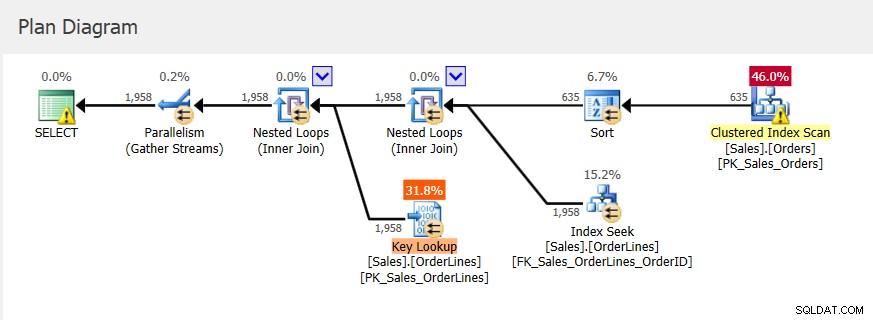
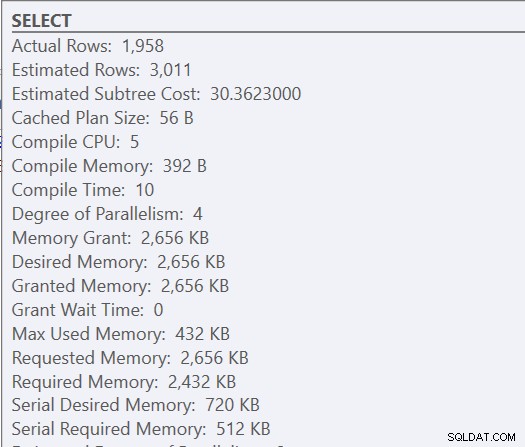
बाद के निष्पादन में एक ही योजना है (जैसा कि कैश किया गया था) और एक ही स्मृति अनुदान, लेकिन हमें एक सुराग मिलता है कि यह पर्याप्त नहीं है क्योंकि एक प्रकार की चेतावनी है।
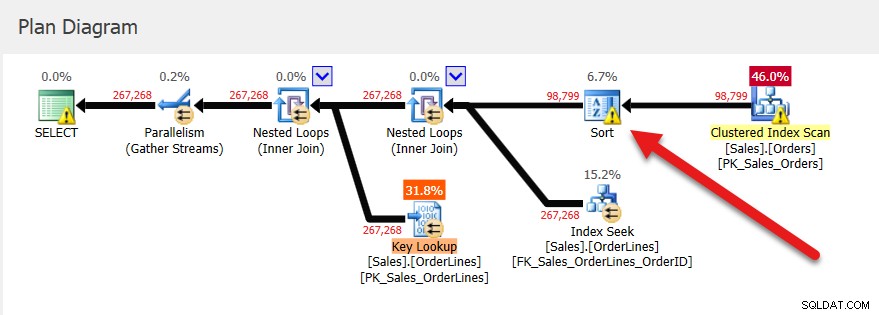
यदि हम इस संग्रहीत कार्यविधि के लिए क्वेरी स्टोर में देखते हैं, तो हम तीन निष्पादन और यूज्डकेबी मेमोरी के लिए समान मान देखते हैं, चाहे हम औसत, न्यूनतम, अधिकतम, अंतिम या मानक विचलन देखें। नोट:क्वेरी स्टोर में स्मृति अनुदान जानकारी को 8KB पृष्ठों की संख्या के रूप में रिपोर्ट किया जाता है।
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], --memory grant (reported as the number of 8 KB pages) for the query plan within the aggregation interval [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE [qsq].[object_id] = OBJECT_ID(N'Sales.usp_OrderInfo_OrderDate');

अगर हम इस परिदृश्य में स्मृति अनुदान मुद्दों की तलाश कर रहे हैं - जहां एक योजना कैश की जाती है और फिर से उपयोग की जाती है - क्वेरी स्टोर हमारी मदद नहीं करेगा।
लेकिन क्या होगा यदि विशिष्ट क्वेरी निष्पादन पर संकलित की जाती है, या तो एक RECOMPILE संकेत के कारण या क्योंकि यह तदर्थ है?
हम कथन में RECOMPILE संकेत जोड़ने की प्रक्रिया को बदल सकते हैं (जिसकी अनुशंसा प्रक्रिया स्तर पर RECOMPILE जोड़ने या RECOMIPLE के साथ प्रक्रिया चलाने पर की जाती है):
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate] OPTION (RECOMPILE); GO
अब हम अपनी प्रक्रिया को पहले की तरह ही इनपुट पैरामीटर के साथ फिर से चलाएंगे, और आउटपुट की जांच करेंगे:

ध्यान दें कि हमारे पास एक नया query_id है - क्वेरी टेक्स्ट बदल गया है क्योंकि हमने इसमें OPTION (RECOMPILE) जोड़ा है - और हमारे पास दो नए plan_id मान भी हैं, और हमारे पास हमारी एक योजना के लिए अलग-अलग मेमोरी ग्रांट नंबर हैं। plan_id 5 के लिए केवल एक निष्पादन है, और स्मृति अनुदान संख्या प्रारंभिक निष्पादन से मेल खाती है - ताकि योजना छोटी तिथि सीमा के लिए हो। दो बड़ी तिथि सीमाओं ने एक ही योजना बनाई, लेकिन स्मृति अनुदान में महत्वपूर्ण परिवर्तनशीलता है - न्यूनतम के लिए 94,528, और अधिकतम के लिए 573,568।
यदि हम क्वेरी स्टोर रिपोर्ट का उपयोग करके मेमोरी ग्रांट जानकारी को देखें, तो यह परिवर्तनशीलता कुछ अलग तरह से दिखाई देती है। डेटाबेस से शीर्ष संसाधन उपभोक्ता रिपोर्ट खोलना, और फिर मीट्रिक को मेमोरी खपत (KB) और औसत में बदलना, RECOMPILE के साथ हमारी क्वेरी सूची में सबसे ऊपर आती है।
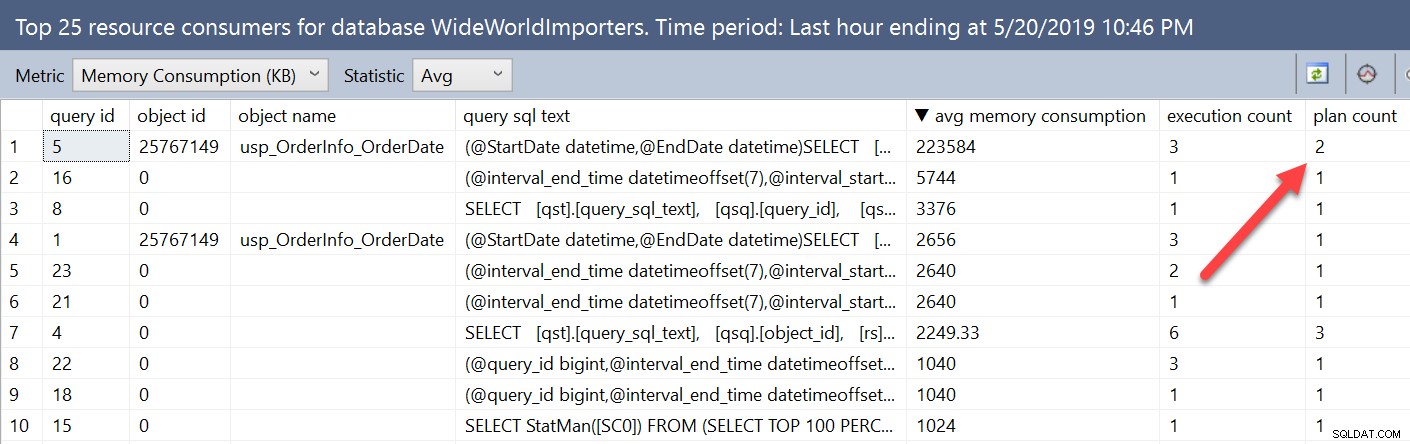
इस विंडो में, मेट्रिक्स को क्वेरी द्वारा एकत्रित किया जाता है, न कि योजना द्वारा। क्वेरी स्टोर दृश्यों के विरुद्ध हमने जो क्वेरी निष्पादित की, वह न केवल query_id बल्कि plan_id को भी सूचीबद्ध करती है। यहां हम देख सकते हैं कि क्वेरी में दो योजनाएं हैं, और हम उन दोनों को योजना सारांश विंडो में देख सकते हैं, लेकिन इस दृश्य में सभी योजनाओं के लिए मीट्रिक संयुक्त हैं।
जब हम सीधे विचारों को देख रहे होते हैं तो स्मृति अनुदान में परिवर्तनशीलता स्पष्ट होती है। हम आँकड़ों को औसत से StDev में बदलकर UI का उपयोग करते हुए परिवर्तनशीलता के साथ क्वेरी ढूंढ सकते हैं:
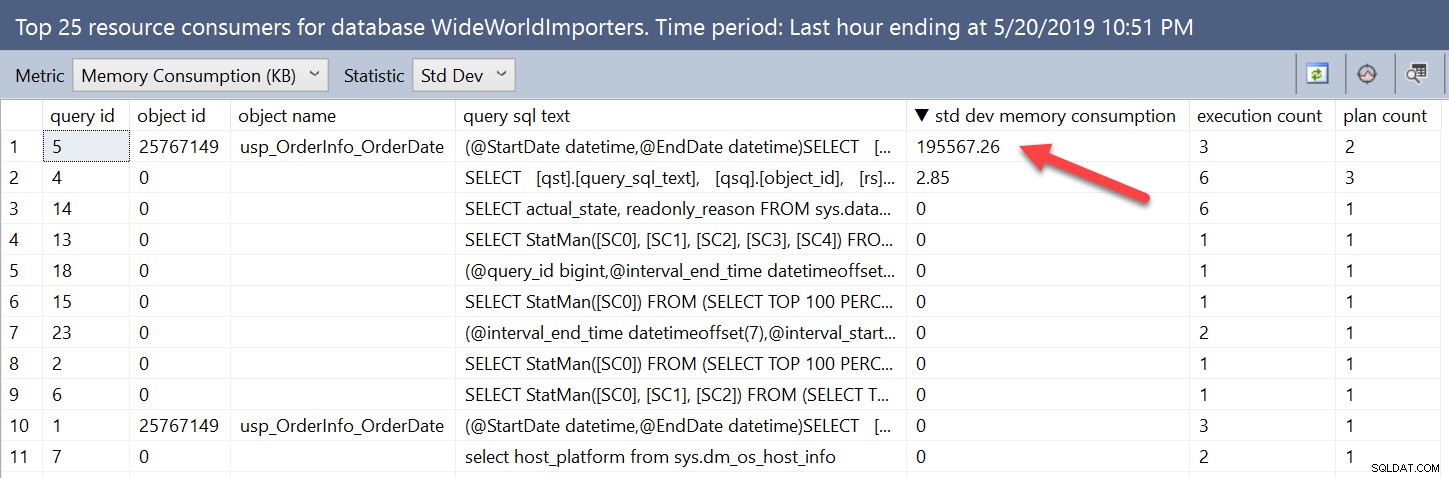
हम वही जानकारी क्वेरी स्टोर दृश्यों को क्वेरी करके और stdev_query_max_used_memory अवरोही द्वारा क्रमित करके प्राप्त कर सकते हैं। लेकिन, हम न्यूनतम और अधिकतम स्मृति अनुदान, या अंतर के प्रतिशत के बीच अंतर के आधार पर भी खोज सकते हैं। उदाहरण के लिए, यदि हम उन मामलों के बारे में चिंतित थे जहां अनुदान में अंतर 512MB से अधिक था, तो हम चला सकते थे:
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE ([rs].[max_query_max_used_memory]*8) - ([rs].[min_query_max_used_memory]*8) > 524288;
आप में से जो SQL Server 2017 को Columnstore इंडेक्स के साथ चला रहे हैं, जिन्हें मेमोरी ग्रांट फीडबैक का लाभ है, वे भी क्वेरी स्टोर में इस जानकारी का उपयोग कर सकते हैं। क्लस्टर्ड कॉलमस्टोर इंडेक्स जोड़ने के लिए हम सबसे पहले अपनी ऑर्डर टेबल बदलेंगे:
ALTER TABLE [Sales].[Invoices] DROP CONSTRAINT [FK_Sales_Invoices_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [FK_Sales_Orders_BackorderOrderID_Sales_Orders]; GO ALTER TABLE [Sales].[OrderLines] DROP CONSTRAINT [FK_Sales_OrderLines_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [PK_Sales_Orders] WITH ( ONLINE = OFF ); GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Orders ON [Sales].[Orders];
फिर हम डेटाबेस कॉम्बेबिलिटी मोड को 140 पर सेट करेंगे ताकि हम मेमोरी ग्रांट फीडबैक का लाभ उठा सकें:
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 140; GO
अंत में, हम अपनी क्वेरी से OPTION (RECOMPILE) को हटाने के लिए अपनी संग्रहीत प्रक्रिया को बदल देंगे और फिर इसे विभिन्न इनपुट मानों के साथ कुछ बार चलाएंगे:
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
क्वेरी स्टोर में हम निम्नलिखित देखते हैं:

हमारे पास query_id =1 के लिए एक नई योजना है, जिसमें मेमोरी ग्रांट मेट्रिक्स के लिए अलग-अलग मान हैं, और हमारे पास plan_id 6 की तुलना में थोड़ा कम StDev है। यदि हम क्वेरी स्टोर में योजना को देखते हैं तो हम देखते हैं कि यह क्लस्टर्ड कॉलमस्टोर इंडेक्स तक पहुंचता है। :
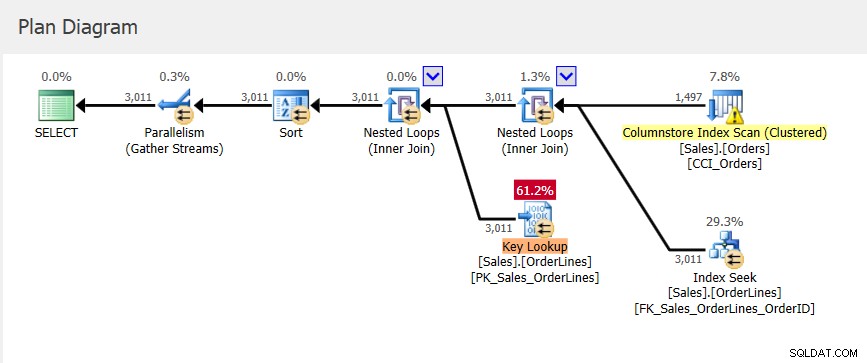
याद रखें कि क्वेरी स्टोर में वह योजना है जिसे निष्पादित किया गया था, लेकिन इसमें केवल अनुमान शामिल हैं। जबकि योजना कैश में योजना में स्मृति अनुदान जानकारी अद्यतन होती है जब स्मृति प्रतिक्रिया होती है, यह जानकारी क्वेरी स्टोर में मौजूदा योजना पर लागू नहीं होती है।
सारांश
चर स्मृति अनुदान के साथ प्रश्नों को देखने के लिए क्वेरी स्टोर का उपयोग करने के बारे में मुझे यह पसंद है:डेटा स्वचालित रूप से एकत्र किया जा रहा है। यदि यह समस्या अनपेक्षित रूप से दिखाई देती है, तो हमें जानकारी एकत्र करने और प्रयास करने के लिए कुछ भी करने की आवश्यकता नहीं है, हमने इसे पहले से ही क्वेरी स्टोर में कैद कर लिया है। ऐसे मामले में जहां एक क्वेरी को पैरामीटर किया गया है, योजना कैशिंग के कारण स्थिर मूल्यों की संभावना के कारण स्मृति अनुदान परिवर्तनशीलता को खोजना कठिन हो सकता है। हालाँकि, हमें यह भी पता चल सकता है कि, पुनर्संकलन के कारण, क्वेरी में बहुत भिन्न मेमोरी ग्रांट मानों के साथ कई योजनाएँ हैं जिनका उपयोग हम समस्या को ट्रैक करने के लिए कर सकते हैं। क्वेरी स्टोर में कैप्चर किए गए डेटा का उपयोग करके समस्या की जांच करने के कई तरीके हैं, और यह आपको समस्याओं को सक्रिय रूप से और साथ ही प्रतिक्रियात्मक रूप से देखने की अनुमति देता है।