जबकि लिनक्स पर SQL सर्वर ने v.Next के बारे में लगभग सभी सुर्खियाँ चुरा ली हैं, हमारे पसंदीदा डेटाबेस प्लेटफ़ॉर्म के अगले संस्करण में कुछ अन्य दिलचस्प प्रगतियाँ आ रही हैं। टी-एसक्यूएल के मोर्चे पर, अंत में हमारे पास समूहबद्ध स्ट्रिंग संयोजन करने का एक अंतर्निहित तरीका है:STRING_AGG() ।
मान लें कि हमारे पास निम्न सरल तालिका संरचना है:
CREATE TABLE dbo.Objects
(
[object_id] int,
[object_name] nvarchar(261),
CONSTRAINT PK_Objects PRIMARY KEY([object_id])
);
CREATE TABLE dbo.Columns
(
[object_id] int NOT NULL
FOREIGN KEY REFERENCES dbo.Objects([object_id]),
column_name sysname,
CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name)
);
प्रदर्शन परीक्षणों के लिए, हम इसे sys.all_objects . का उपयोग करके पॉप्युलेट करने जा रहे हैं और sys.all_columns . लेकिन पहले एक साधारण प्रदर्शन के लिए, आइए निम्नलिखित पंक्तियाँ जोड़ें:
INSERT dbo.Objects([object_id],[object_name])
VALUES(1,N'Employees'),(2,N'Orders');
INSERT dbo.Columns([object_id],column_name)
VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'),
(2,N'OrderID'),(2,N'OrderDate'),(2,N'CustomerID'); यदि फ़ोरम कोई संकेत हैं, तो कॉलम नामों की अल्पविराम से अलग की गई सूची के साथ, प्रत्येक ऑब्जेक्ट के लिए एक पंक्ति वापस करना एक बहुत ही सामान्य आवश्यकता है। (व्याख्या करें कि आप जिस भी इकाई प्रकार को इस तरह से मॉडल करते हैं - किसी ऑर्डर से जुड़े उत्पाद नाम, उत्पाद की असेंबली में शामिल भाग के नाम, प्रबंधक को रिपोर्ट करने वाले अधीनस्थ आदि।) इसलिए, उदाहरण के लिए, उपरोक्त डेटा के साथ हम करेंगे इस तरह आउटपुट चाहते हैं:
object columns --------- ---------------------------- Employees EmployeeID,CurrentStatus Orders OrderID,OrderDate,CustomerID
जिस तरह से हम इसे SQL सर्वर के वर्तमान संस्करणों में पूरा करेंगे, वह संभवतः XML PATH के लिए का उपयोग करना है , जैसा कि मैंने इस पिछली पोस्ट में सीएलआर के बाहर सबसे कुशल होने का प्रदर्शन किया था। इस उदाहरण में, यह इस तरह दिखेगा:
SELECT [object] = o.[object_name],
[columns] = STUFF(
(SELECT N',' + c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; मुख्य रूप से, हमें वही आउटपुट मिलता है जो ऊपर दिखाया गया है। SQL सर्वर v.Next में, हम इसे और अधिक सरलता से व्यक्त करने में सक्षम होंगे:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
फिर, यह ठीक उसी आउटपुट का उत्पादन करता है। और हम इसे एक मूल कार्य के साथ करने में सक्षम थे, दोनों महंगे XML पथ के लिए . से बचते हुए मचान, और STUFF() प्रथम अल्पविराम को हटाने के लिए उपयोग किया जाने वाला फ़ंक्शन (यह स्वचालित रूप से होता है)।
आदेश के बारे में क्या?
समूहबद्ध संयोजन के लिए कई कीचड़ समाधानों में से एक समस्या यह है कि अल्पविराम से अलग की गई सूची के क्रम को मनमाना और गैर-निर्धारक माना जाना चाहिए।
एक्सएमएल पथ के लिए समाधान, मैंने एक अन्य पिछली पोस्ट में प्रदर्शित किया था कि एक ORDER BY . जोड़ना तुच्छ और गारंटीकृत है। तो इस उदाहरण में, हम कॉलम सूची को कॉलम नाम से वर्णानुक्रम में क्रमबद्ध करने के लिए SQL सर्वर पर छोड़ने के बजाय क्रमबद्ध कर सकते हैं (या नहीं):
SELECT [object] = [object_name],
[columns] = STUFF(
(SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name -- only change
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; आउटपुट:
object columns --------- ---------------------------- Employees CurrentStatus,EmployeeID Order CustomerID,OrderDate,OrderID
सीटीपी 1.1 ग्रुप के भीतर जोड़ता है करने के लिए STRING_AGG() , इसलिए नए दृष्टिकोण का उपयोग करते हुए, हम कह सकते हैं:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name) -- only change
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
अब हमें वही परिणाम मिलते हैं। ध्यान दें कि, सामान्य आदेश द्वारा . की तरह ही क्लॉज, आप WITHIN GROUP () . के अंदर कई ऑर्डरिंग कॉलम या एक्सप्रेशन जोड़ सकते हैं ।
ठीक है, प्रदर्शन पहले ही हो चुका है!
क्वाड-कोर 2.6 गीगाहर्ट्ज़ प्रोसेसर, 8 जीबी मेमोरी और SQL सर्वर CTP1.1 (14.0.100.187) का उपयोग करके, मैंने एक नया डेटाबेस बनाया, इन तालिकाओं को फिर से बनाया, और sys.all_objects और sys.all_columns . मैंने केवल उन वस्तुओं को शामिल करना सुनिश्चित किया जिनमें कम से कम एक कॉलम था:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rows
SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name)
FROM sys.all_objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns
WHERE [object_id] = o.[object_id]
);
INSERT dbo.Columns([object_id], column_name) -- 8,085 rows
SELECT [object_id], name
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.Objects
WHERE [object_id] = c.[object_id]
); मेरे सिस्टम पर, इससे 656 ऑब्जेक्ट और 8,085 कॉलम निकले (आपका सिस्टम थोड़ा अलग नंबर दे सकता है)।
योजनाएं
सबसे पहले, प्लान एक्सप्लोरर का उपयोग करते हुए, हमारे दो अनियंत्रित प्रश्नों के लिए योजनाओं और तालिका I/O टैब की तुलना करें। यहां समग्र रनटाइम मीट्रिक हैं:
 XML PATH (शीर्ष) और STRING_AGG() (नीचे) के लिए रनटाइम मेट्रिक्स उन्हें>
XML PATH (शीर्ष) और STRING_AGG() (नीचे) के लिए रनटाइम मेट्रिक्स उन्हें>
एक्सएमएल पथ के लिए . से ग्राफिकल योजना और तालिका I/O क्वेरी:
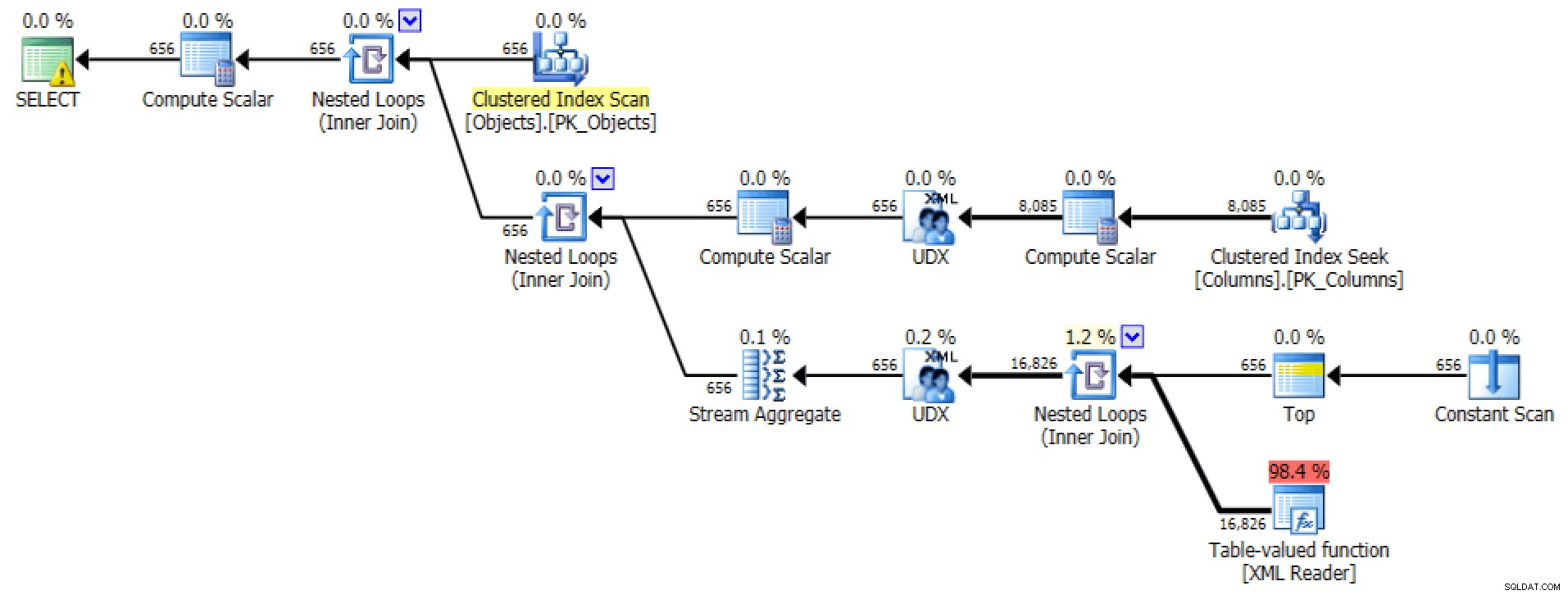
 योजना और तालिका I/O एक्सएमएल पथ के लिए, कोई आदेश नहीं
योजना और तालिका I/O एक्सएमएल पथ के लिए, कोई आदेश नहीं
और STRING_AGG . से संस्करण:
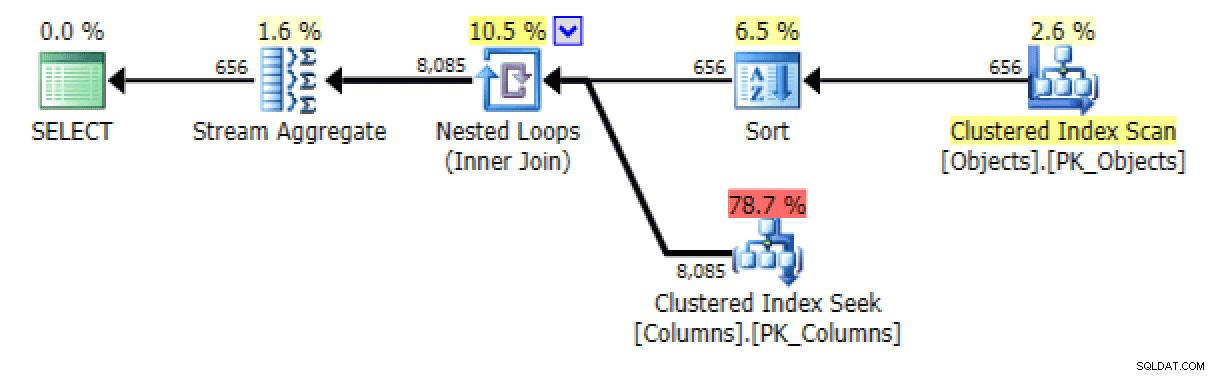
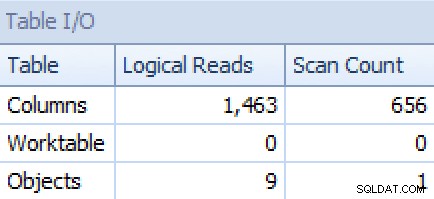 योजना और तालिका I/O STRING_AGG के लिए, कोई आदेश नहीं
योजना और तालिका I/O STRING_AGG के लिए, कोई आदेश नहीं
उत्तरार्द्ध के लिए, संकुल सूचकांक की तलाश मुझे थोड़ी परेशान करने वाली लगती है। यह शायद ही कभी इस्तेमाल किए गए FORCESCAN . के परीक्षण के लिए एक अच्छा मामला लग रहा था संकेत (और नहीं, यह निश्चित रूप से XML पथ के लिए में मदद नहीं करेगा क्वेरी):
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- added hint
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name]; अब प्लान और टेबल I/O टैब एक लॉट . दिखता है बेहतर, कम से कम पहली नज़र में:
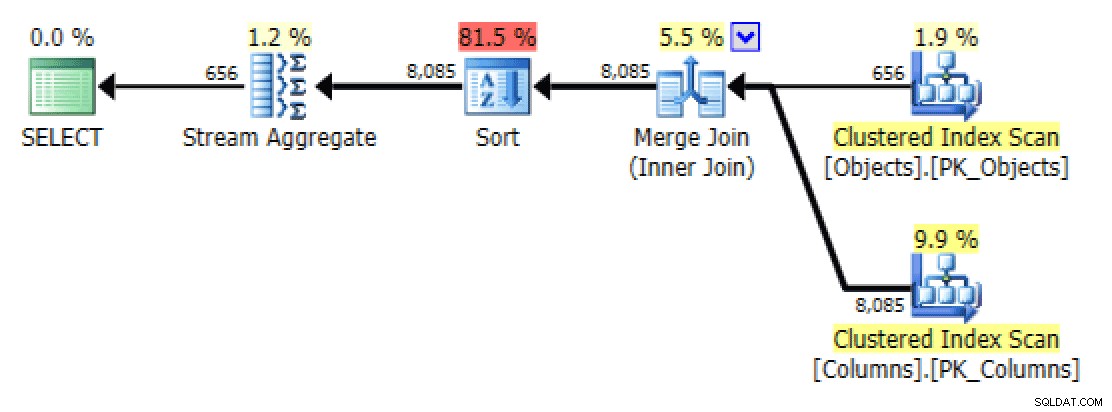
 योजना और तालिका I/O STRING_AGG() के लिए, FORCESCAN के साथ कोई आदेश नहीं
योजना और तालिका I/O STRING_AGG() के लिए, FORCESCAN के साथ कोई आदेश नहीं
प्रश्नों के आदेशित संस्करण मोटे तौर पर समान योजनाएँ उत्पन्न करते हैं। एक्सएमएल पथ के लिए . के लिए संस्करण, एक प्रकार जोड़ा गया है:
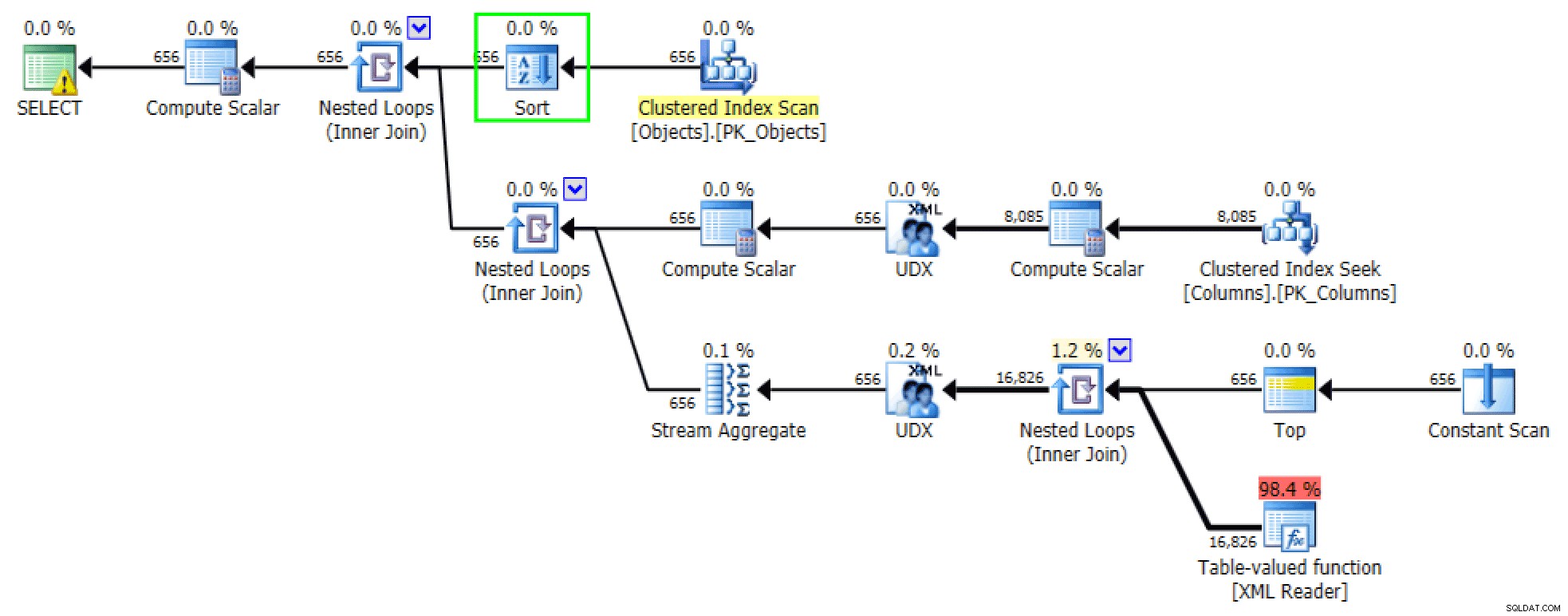 XML PATH संस्करण के लिए जोड़ा गया सॉर्ट करें
XML PATH संस्करण के लिए जोड़ा गया सॉर्ट करें
STRING_AGG() . के लिए , इस मामले में एक स्कैन चुना जाता है, यहां तक कि FORCESCAN . के बिना भी संकेत, और किसी अतिरिक्त सॉर्ट ऑपरेशन की आवश्यकता नहीं है - इसलिए योजना FORCESCAN . के समान दिखती है संस्करण।
पैमाने पर
किसी योजना और वन-ऑफ़ रनटाइम मेट्रिक्स को देखने से हमें इस बारे में कुछ अंदाजा हो सकता है कि STRING_AGG() मौजूदा XML पथ के लिए . से बेहतर प्रदर्शन करता है समाधान, लेकिन एक बड़ा परीक्षण अधिक समझ में आ सकता है। क्या होता है जब हम समूहबद्ध संयोजन को 5,000 बार करते हैं?
SELECT SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered, forcescan] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o; GO 5000 SELECT [for xml path, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, ordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] ORDER BY c.column_name FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o ORDER BY o.[object_name]; GO 5000 SELECT [for xml path, ordered] = SYSDATETIME();
इस स्क्रिप्ट को पांच बार चलाने के बाद, मैंने अवधि संख्याओं का औसत निकाला और ये रहे परिणाम:
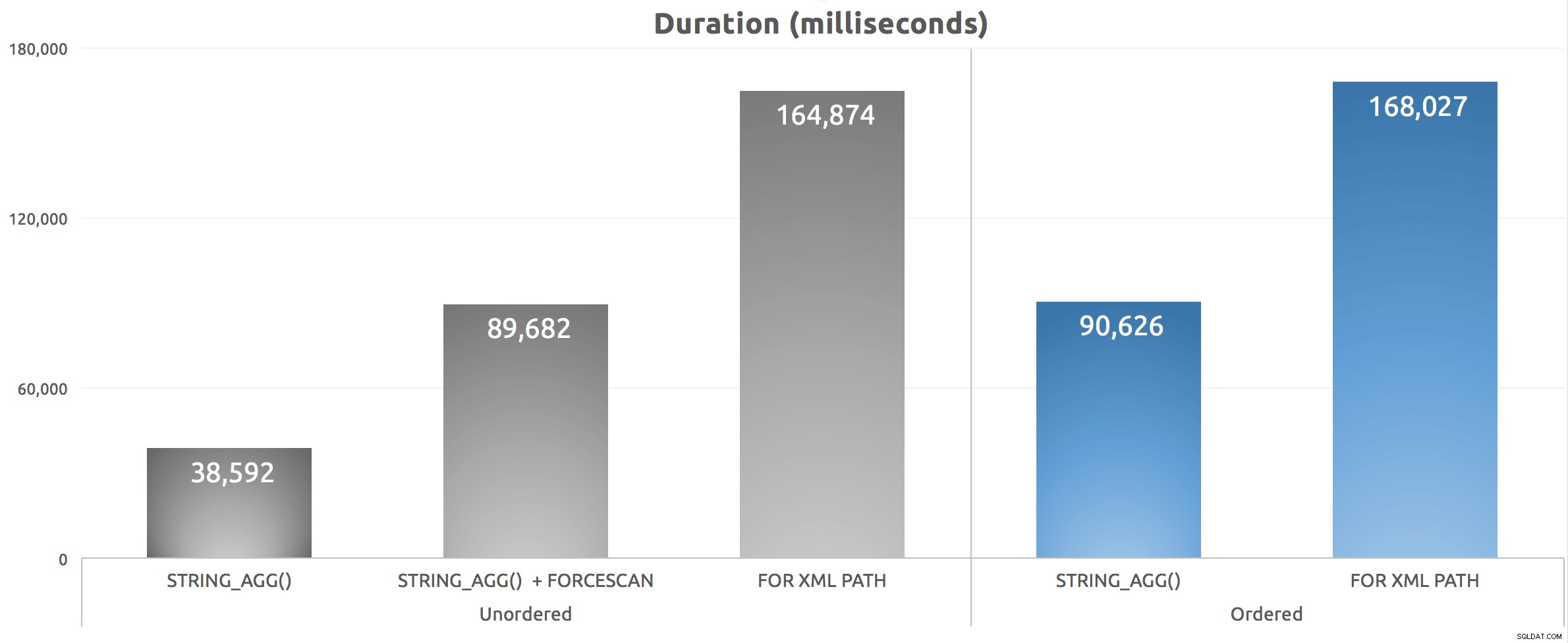 विभिन्न समूहबद्ध संयोजन विधियों के लिए अवधि (मिलीसेकंड)
विभिन्न समूहबद्ध संयोजन विधियों के लिए अवधि (मिलीसेकंड)
हम देख सकते हैं कि हमारा FORCESCAN संकेत ने वास्तव में चीजों को बदतर बना दिया - जब हमने लागत को क्लस्टर इंडेक्स की तलाश से दूर स्थानांतरित कर दिया, तो यह वास्तव में बहुत खराब था, भले ही अनुमानित लागतों ने उन्हें अपेक्षाकृत समकक्ष समझा। इससे भी महत्वपूर्ण बात यह है कि हम देख सकते हैं कि STRING_AGG() एक प्रदर्शन लाभ प्रदान करता है, चाहे समेकित तारों को एक विशिष्ट तरीके से आदेश देने की आवश्यकता हो या नहीं। जैसा कि STRING_SPLIT() के साथ है , जिसे मैंने मार्च में वापस देखा, मैं काफी प्रभावित हूं कि यह फ़ंक्शन "v1" से पहले अच्छी तरह से स्केल करता है।
मेरे पास और परीक्षणों की योजना है, शायद भविष्य की पोस्ट के लिए:
- जब सभी डेटा एक ही टेबल से आता है, ऑर्डरिंग का समर्थन करने वाले इंडेक्स के साथ और उसके बिना
- लिनक्स पर समान प्रदर्शन परीक्षण
इस बीच, यदि आपके पास समूहबद्ध संयोजन के लिए विशिष्ट उपयोग के मामले हैं, तो कृपया उन्हें नीचे साझा करें (या मुझे abertrand@sentryone.com पर ई-मेल करें)। मैं यह सुनिश्चित करने के लिए हमेशा तैयार रहता हूं कि मेरे परीक्षण यथासंभव वास्तविक हों।