क्या SQL सर्वर का नया संस्करण उपलब्ध होना अच्छा नहीं है? यह कुछ ऐसा है जो केवल हर दो साल में होता है, और इस महीने हमने देखा कि एक सामान्य उपलब्धता तक पहुंच गया है। (ठीक है, मुझे पता है कि हमें लगभग लगातार Azure में SQL डेटाबेस का एक नया संस्करण मिलता है, लेकिन मैं इसे अलग मानता हूं।) इस नई रिलीज़ को स्वीकार करते हुए, इस महीने का टी-एसक्यूएल मंगलवार (माइकल स्वार्ट - @mjswart द्वारा होस्ट किया गया) SQL सर्वर 2016 की सभी चीजों के विषय पर है!
क्या SQL सर्वर का नया संस्करण उपलब्ध होना अच्छा नहीं है? यह कुछ ऐसा है जो केवल हर दो साल में होता है, और इस महीने हमने देखा कि एक सामान्य उपलब्धता तक पहुंच गया है। (ठीक है, मुझे पता है कि हमें लगभग लगातार Azure में SQL डेटाबेस का एक नया संस्करण मिलता है, लेकिन मैं इसे अलग मानता हूं।) इस नई रिलीज़ को स्वीकार करते हुए, इस महीने का टी-एसक्यूएल मंगलवार (माइकल स्वार्ट - @mjswart द्वारा होस्ट किया गया) SQL सर्वर 2016 की सभी चीजों के विषय पर है!
इसलिए आज मैं SQL 2016 के टेम्पोरल टेबल्स फीचर को देखना चाहता हूं, और कुछ क्वेरी प्लान स्थितियों पर एक नजर डालना चाहता हूं जिन्हें आप देख सकते हैं। मुझे टेम्पोरल टेबल्स बहुत पसंद हैं, लेकिन मुझे एक ऐसा गॉचा मिला है जिसके बारे में आप जानना चाहेंगे।
अब, इस तथ्य के बावजूद कि SQL Server 2016 अब RTM में है, मैं AdventureWorks2016CTP3 का उपयोग कर रहा हूं, जिसे आप यहां डाउनलोड कर सकते हैं - लेकिन केवल AdventureWorks2016CTP3.bak डाउनलोड न करें। , SQLServer2016CTP3Samples.zip भी लें उसी साइट से।
आप देखते हैं, नमूना संग्रह में, नई सुविधाओं को आज़माने के लिए कुछ उपयोगी स्क्रिप्ट हैं, जिनमें कुछ अस्थायी तालिकाओं के लिए भी शामिल हैं। यह जीत-जीत है - आपको नई सुविधाओं का एक समूह आज़माने को मिलता है, और मुझे इस पोस्ट में इतनी स्क्रिप्ट दोहराने की ज़रूरत नहीं है। वैसे भी, AW 2016 CTP3 Temporal Setup.sql चल रहे टेम्पोरल टेबल्स के बारे में दो लिपियों को प्राप्त करें। , उसके बाद Temporal System-Versioning Sample.sql .
ये स्क्रिप्ट कुछ तालिकाओं के अस्थायी संस्करण सेट करती हैं, जिनमें HumanResources.Employee . शामिल हैं . यह HumanResources.Employee_Temporal . बनाता है (हालाँकि, तकनीकी रूप से, इसे कुछ भी कहा जा सकता था)। CREATE TABLE के अंत में कथन, यह बिट प्रकट होता है, पंक्ति के मान्य होने पर इंगित करने के लिए उपयोग करने के लिए दो छिपे हुए कॉलम जोड़ते हैं, और यह इंगित करते हैं कि एक तालिका बनाई जानी चाहिए जिसे HumanResources.Employee_Temporal_History कहा जाता है। पुराने संस्करणों को संग्रहीत करने के लिए।
... ValidFrom datetime2(7) हमेशा के रूप में उत्पन्न होता है जैसे कि ROW START HIDDEN NOT NULL, ValidTo datetime2(7) हमेशा ROW END HIDDEN NOT NULL, PERIOD for SYSTEM_TIME (ValidFrom, ValidTo)) के साथ (SYSTEM_VERSIONING =ON (SYSTEM_VERSIONING =ON) =[मानव संसाधन]। [कर्मचारी_टेम्पोरल_इतिहास]));
इस पोस्ट में मैं यह जानना चाहता हूं कि जब इतिहास का उपयोग किया जाता है तो क्वेरी योजनाओं के साथ क्या होता है।
यदि मैं किसी विशेष BusinessEntityID . के लिए नवीनतम पंक्ति देखने के लिए तालिका को क्वेरी करता हूं , मुझे उम्मीद के मुताबिक एक क्लस्टर्ड इंडेक्स सीक मिलता है।
चुनें e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal AS eWHERE e.BusinessEntityID =4;
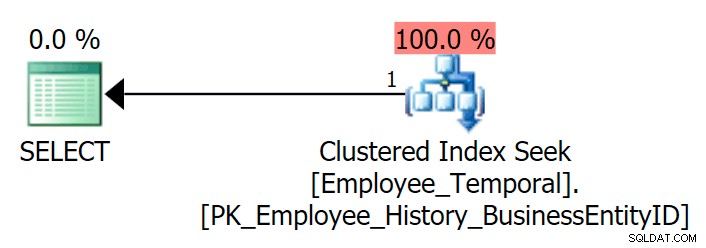
मुझे यकीन है कि मैं अन्य इंडेक्स का उपयोग करके इस तालिका को क्वेरी कर सकता हूं, अगर इसमें कोई था। लेकिन इस मामले में, ऐसा नहीं होता है। आइए एक बनाते हैं।
मानव संसाधन पर अद्वितीय सूचकांक बनाएं rf_ix_Login.Employee_Temporal(LoginID);
अब मैं LoginID . द्वारा तालिका को क्वेरी कर सकता हूं , और यदि मैं Loginid . के अलावा अन्य कॉलम मांगता हूं तो एक कुंजी लुकअप दिखाई देगा या BusinessEntityID . इसमें से कुछ भी आश्चर्यजनक नहीं है।
चुनें * ह्यूमन रिसोर्सेज से। कर्मचारी_टेम्पोरल eWHERE e.LoginID =N'adventure-works\rob0';
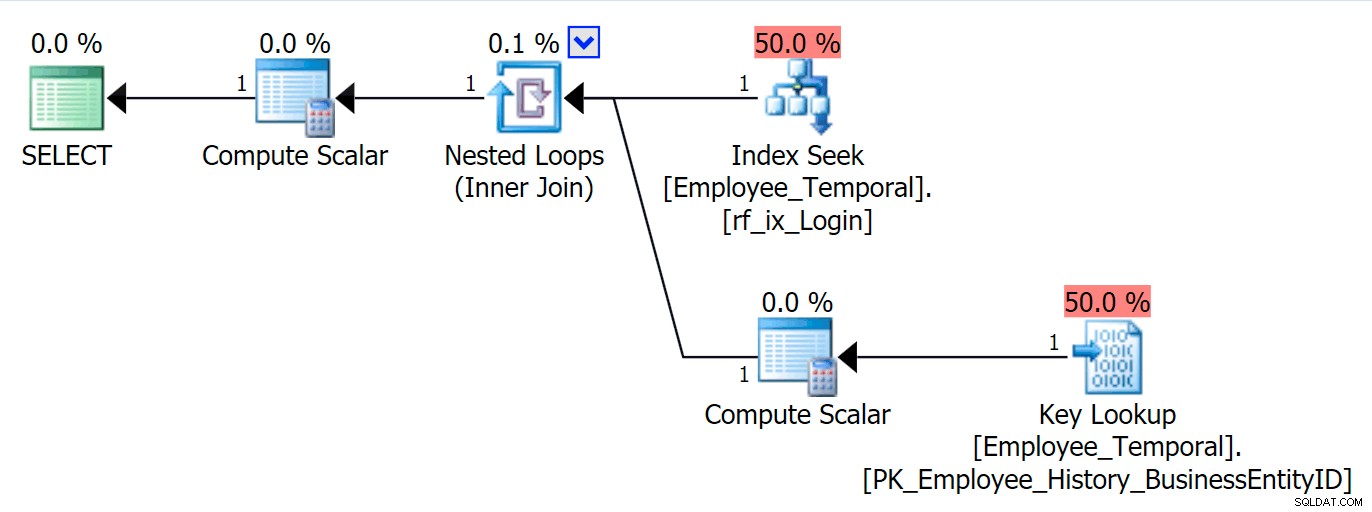
आइए एक मिनट के लिए SQL सर्वर प्रबंधन स्टूडियो का उपयोग करें, और देखें कि यह तालिका ऑब्जेक्ट एक्सप्लोरर में कैसी दिखती है।

हम HumanResources.Employee_Temporal . के अंतर्गत उल्लिखित इतिहास तालिका देख सकते हैं , और स्तंभ और अनुक्रमणिका दोनों तालिका और इतिहास तालिका दोनों से। लेकिन उचित टेबल पर इंडेक्स प्राथमिक कुंजी हैं (BusinessEntityID . पर) ) और जो इंडेक्स मैंने अभी बनाया था, हिस्ट्री टेबल में मैचिंग इंडेक्स नहीं हैं।
इतिहास तालिका पर सूचकांक ValidTo . पर है और ValidFrom . हम अनुक्रमणिका पर राइट-क्लिक कर सकते हैं और गुण चुन सकते हैं, और हम यह संवाद देखते हैं:
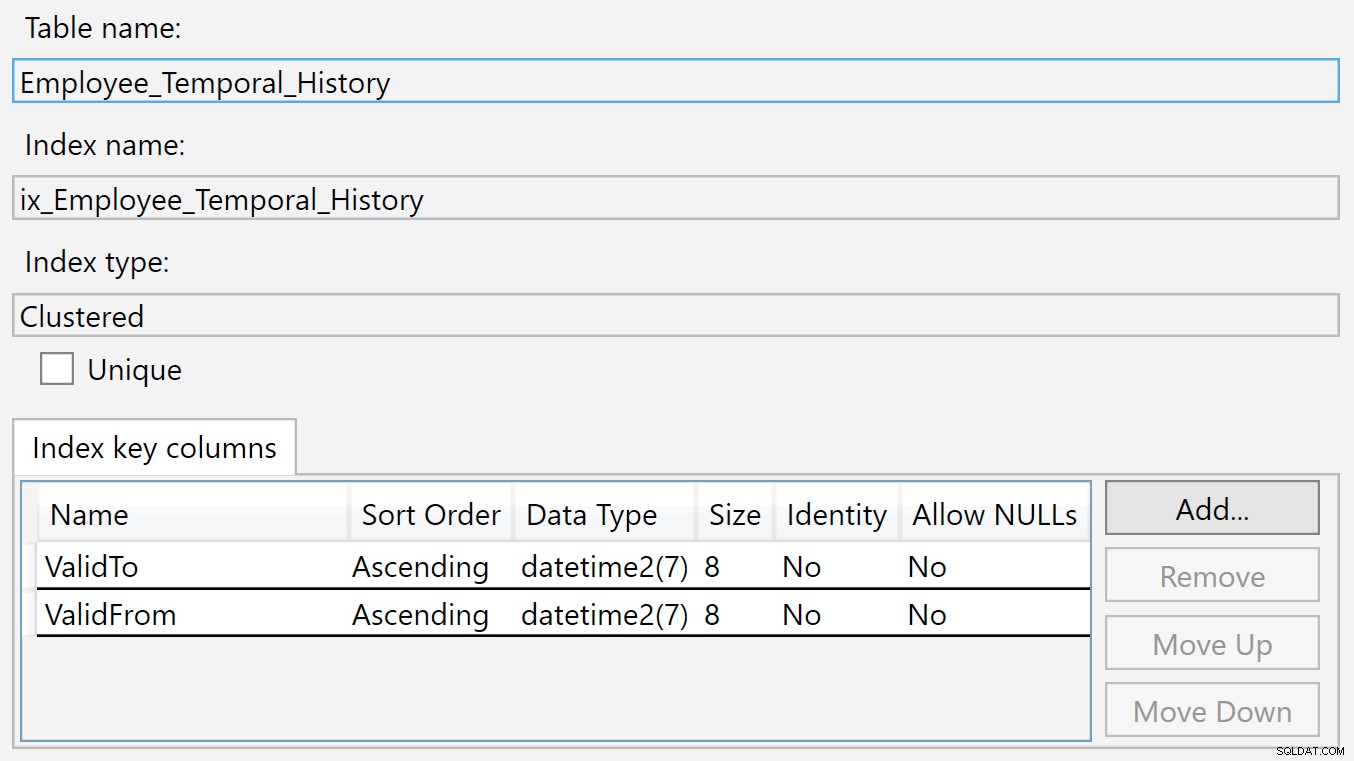
इस इतिहास तालिका में एक नई पंक्ति तब डाली जाती है जब यह मुख्य तालिका में मान्य नहीं होती है, क्योंकि इसे अभी हटा दिया गया है या बदल दिया गया है। ValidTo . में मान कॉलम स्वाभाविक रूप से वर्तमान समय से भरे हुए हैं, इसलिए ValidTo एक पहचान कॉलम की तरह आरोही कुंजी के रूप में कार्य करता है, ताकि बी-पेड़ संरचना के अंत में नई प्रविष्टियां दिखाई दें।
लेकिन जब आप तालिका को क्वेरी करना चाहते हैं तो यह कैसा प्रदर्शन करता है?
यदि हम अपनी तालिका से पूछना चाहते हैं कि किसी विशेष समय में वर्तमान में क्या था, तो हमें एक क्वेरी संरचना का उपयोग करना चाहिए जैसे:
चुनें * मानव संसाधन से। कर्मचारी_टेम्पोरल सिस्टम_टाइम के लिए '20160612 11:22';
इस क्वेरी को मुख्य तालिका से उपयुक्त पंक्तियों को इतिहास तालिका से उपयुक्त पंक्तियों के साथ संयोजित करने की आवश्यकता है।
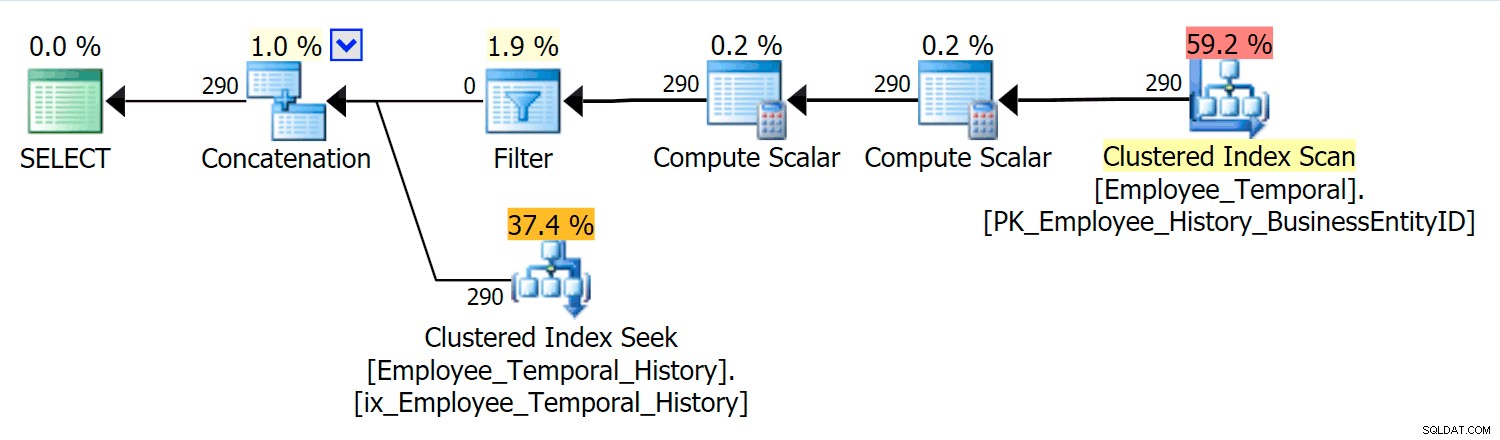
इस परिदृश्य में, मेरे द्वारा चुने गए क्षण के लिए मान्य पंक्तियाँ सभी इतिहास तालिका से थीं, लेकिन फिर भी, हम मुख्य तालिका के विरुद्ध एक क्लस्टर इंडेक्स स्कैन देखते हैं, जिसे फ़िल्टर ऑपरेटर द्वारा फ़िल्टर किया गया था। इस फ़िल्टर का विधेय है:
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' और [HumanResources].[Employee_Temporal].[ValidTo]> '2016-06-12 11:22 :00.0000000'
आइए इसे एक पल में फिर से देखें।
इतिहास तालिका पर क्लस्टर्ड इंडेक्स सीक को स्पष्ट रूप से ValidTo पर सीक प्रेडिकेट का लाभ उठाना चाहिए। सीक के रेंज स्कैन की शुरुआत HumanResources.Employee_Temporal_History.ValidTo है > स्केलर ऑपरेटर ('2016-06-12 11:22:00') , लेकिन कोई अंत नहीं है, क्योंकि प्रत्येक पंक्ति जिसमें ValidTo . है जिस समय के बाद हम परवाह करते हैं वह एक उम्मीदवार पंक्ति है, और एक उपयुक्त ValidFrom . के लिए परीक्षण किया जाना चाहिए अवशिष्ट विधेय द्वारा मान, जो कि HumanResources.Employee_Temporal_History.ValidFrom है <= '2016-06-12 11:22:00' ।
अब, अंतरालों को अनुक्रमित करना कठिन है; यह एक ज्ञात बात है जिस पर कई ब्लॉगों पर चर्चा की गई है। सबसे प्रभावी समाधान प्रश्नों को लिखने के रचनात्मक तरीकों पर विचार करते हैं, लेकिन ऐसे किसी भी स्मार्ट को टेम्पोरल टेबल में नहीं बनाया गया है। हालांकि, आप इंडेक्स को अन्य कॉलम पर भी डाल सकते हैं, जैसे कि ValidFrom पर, या यहां तक कि इंडेक्स भी हो सकते हैं जो मुख्य टेबल पर आपके प्रश्नों के प्रकार से मेल खाते हों। क्लस्टर इंडेक्स के साथ ValidTo . दोनों पर एक कंपोजिट कुंजी है और ValidFrom , ये दो कॉलम हर दूसरे कॉलम में शामिल हो जाते हैं, कुछ अवशिष्ट विधेय परीक्षण के लिए एक अच्छा अवसर प्रदान करते हैं।
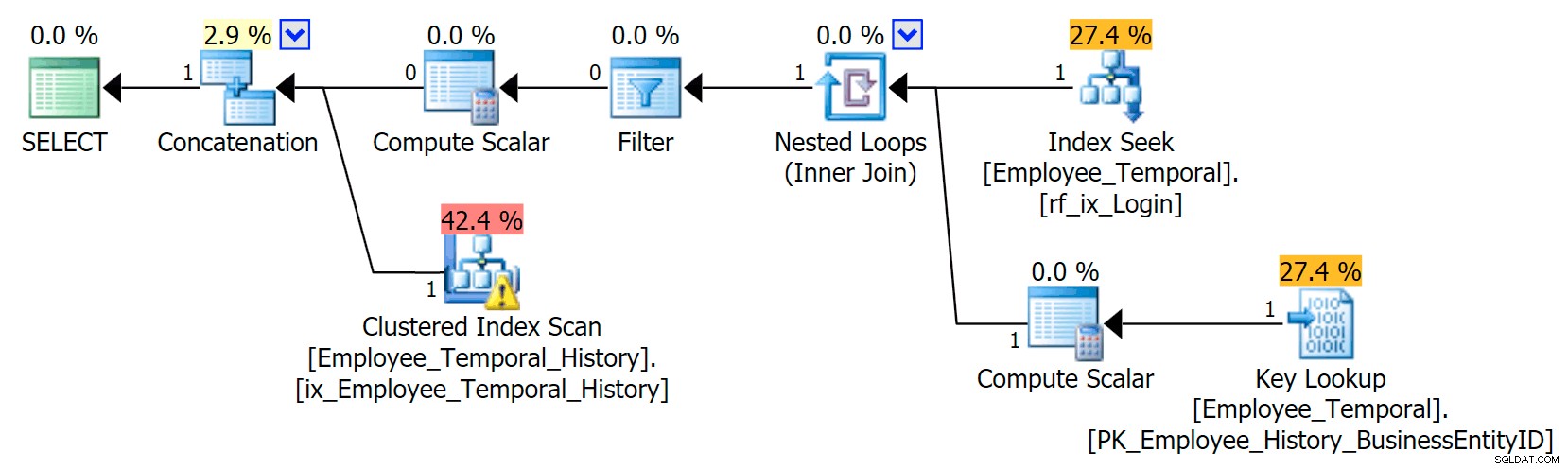
अगर मुझे पता है कि मुझे किस लॉगिन आईडी में दिलचस्पी है, तो मेरी योजना एक अलग आकार लेती है।
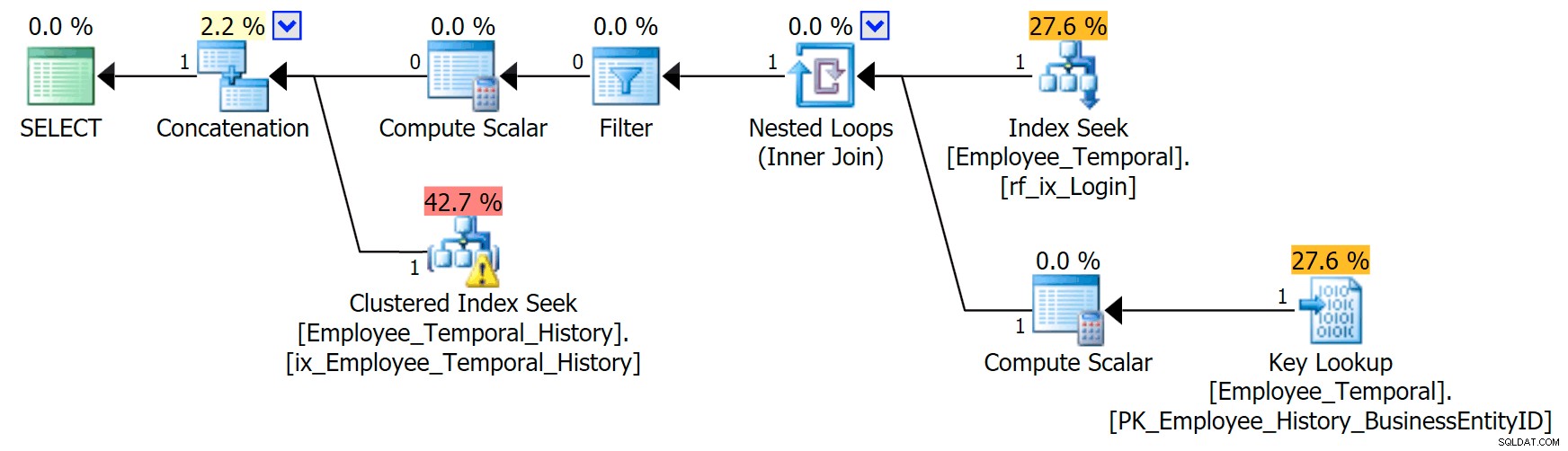
कॉन्सटेनेशन ऑपरेटर की शीर्ष शाखा पहले की तरह दिखती है, हालांकि उस फ़िल्टर ऑपरेटर ने किसी भी पंक्ति को हटाने के लिए मैदान में प्रवेश किया है जो मान्य नहीं है, लेकिन निचली शाखा पर क्लस्टर इंडेक्स सीक में एक चेतावनी है। यह एक अवशिष्ट विधेय चेतावनी है, जैसे मेरी पिछली पोस्ट में उदाहरण। यह उन प्रविष्टियों को फ़िल्टर करने में सक्षम है जो उस समय के बाद तक मान्य हैं जब तक हम परवाह करते हैं, लेकिन अवशिष्ट विधेय अब LoginID को फ़िल्टर करता है साथ ही ValidFrom ।
[मानव संसाधन]। /पूर्व>रॉब0 की पंक्तियों में परिवर्तन इतिहास में पंक्तियों का एक छोटा अनुपात होने जा रहा है। यह कॉलम मुख्य तालिका की तरह अद्वितीय नहीं होगा, क्योंकि पंक्ति को कई बार बदला जा सकता है, लेकिन अनुक्रमण के लिए अभी भी एक अच्छा उम्मीदवार है।
इंडेक्स बनाएं rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);इस नई अनुक्रमणिका का हमारी योजना पर उल्लेखनीय प्रभाव है।
अब इसने हमारे क्लस्टर इंडेक्स सीक को क्लस्टर्ड इंडेक्स स्कैन में बदल दिया है!!
आप देखिए, क्वेरी ऑप्टिमाइज़र अब काम करता है कि नई अनुक्रमणिका का उपयोग करना सबसे अच्छी बात होगी। लेकिन यह भी तय करता है कि अन्य सभी कॉलम प्राप्त करने के लिए लुकअप करने का प्रयास (क्योंकि मैं सभी कॉलम मांग रहा था) बस बहुत अधिक काम होगा। टिपिंग बिंदु पर पहुंच गया (दुख की बात है कि इस मामले में एक गलत धारणा), और इसके बजाय एक क्लस्टर इंडेक्स स्कैन चुना गया। भले ही गैर-संकुल सूचकांक के बिना, सबसे अच्छा विकल्प एक संकुल सूचकांक खोज का उपयोग करना होता, जब गैर-संकुल सूचकांक पर विचार किया जाता है और टिपिंग-पॉइंट कारणों से अस्वीकार कर दिया जाता है, तो यह स्कैन करना चुनता है।
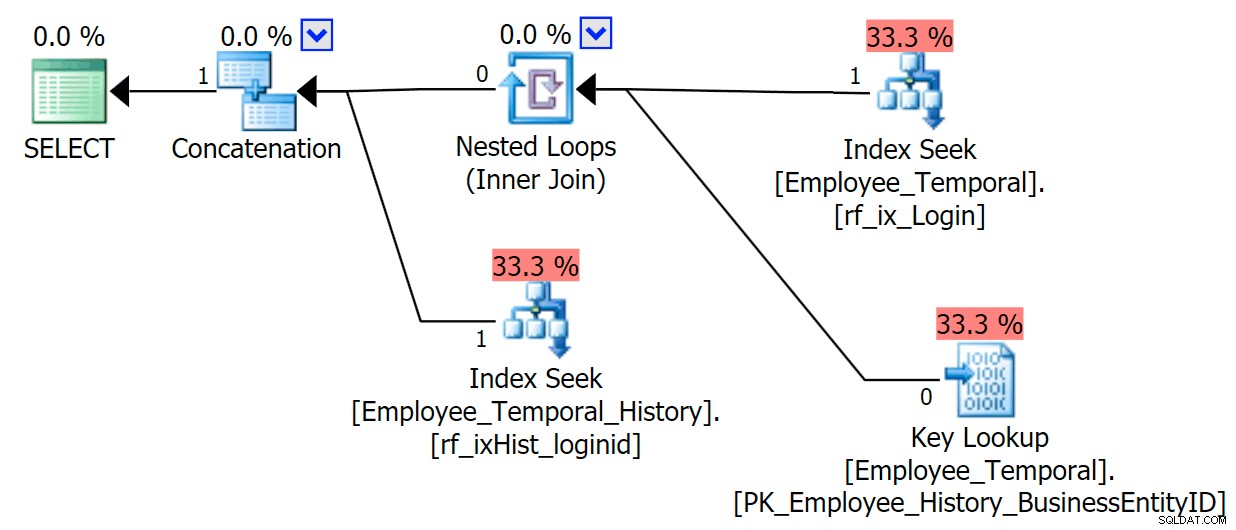
निराशा की बात है कि मैंने अभी-अभी यह सूचकांक बनाया है और इसके आँकड़े अच्छे होने चाहिए। यह पता होना चाहिए कि एक सीक जिसे ठीक एक लुकअप की आवश्यकता है, एक क्लस्टर्ड इंडेक्स स्कैन से बेहतर होना चाहिए (केवल आंकड़ों के अनुसार - यदि आप सोच रहे थे कि इसे यह जानना चाहिए क्योंकि
LoginIDमुख्य तालिका में अद्वितीय है, याद रखें कि यह हमेशा नहीं रहा होगा)। इसलिए मुझे संदेह है कि इतिहास की तालिकाओं में लुकअप से बचा जाना चाहिए, हालांकि मैंने अभी तक इस पर पर्याप्त शोध नहीं किया है।अब हम केवल उन कॉलमों को क्वेरी करने के लिए थे जो हमारे गैर-क्लस्टर इंडेक्स में दिखाई देते हैं, हमें बेहतर व्यवहार मिलेगा। अब जब किसी खोज की आवश्यकता नहीं है, इतिहास तालिका पर हमारे नए सूचकांक का खुशी से उपयोग किया जाता है। इसे अभी भी केवल
LoginIDपर फ़िल्टर करने में सक्षम होने के आधार पर एक अवशिष्ट विधेय लागू करने की आवश्यकता है औरValidTo, लेकिन यह क्लस्टर्ड इंडेक्स स्कैन में जाने से कहीं बेहतर व्यवहार करता है।लॉगिन आईडी चुनें, ValidFrom, ValidToFROM HumanResources.Employee_TemporalSYSTEM_TIME के लिए '20160612 11:22' जहां लॉग इन आईडी =N'adventure-works\rob0'
तो अपने इतिहास तालिकाओं को अतिरिक्त तरीकों से अनुक्रमित करें, यह देखते हुए कि आप उनसे कैसे पूछताछ करेंगे। लुकअप से बचने के लिए आवश्यक कॉलम शामिल करें, क्योंकि आप वास्तव में स्कैन से बच रहे हैं।
यदि डेटा बार-बार बदल रहा है तो ये इतिहास तालिकाएँ बड़ी हो सकती हैं। तो सावधान रहें कि उन्हें कैसे संभाला जा रहा है। अन्य
FOR SYSTEM_TIME. का उपयोग करते समय भी यही स्थिति होती है निर्माण करता है, इसलिए आपको (हमेशा की तरह) उन योजनाओं की समीक्षा करनी चाहिए जो आपके प्रश्न उत्पन्न कर रहे हैं, और यह सुनिश्चित करने के लिए अनुक्रमणिका करें कि आप SQL सर्वर 2016 की एक बहुत शक्तिशाली विशेषता का लाभ उठाने के लिए अच्छी तरह से तैनात हैं।