SQL सर्वर 2008 ने विरल स्तंभों को अशक्त मानों के लिए भंडारण को कम करने और अधिक एक्स्टेंसिबल स्कीमा प्रदान करने के लिए एक विधि के रूप में पेश किया। व्यापार-बंद यह है कि जब आप गैर-नल मानों को संग्रहीत और पुनर्प्राप्त करते हैं तो अतिरिक्त ओवरहेड होता है। स्टेजिंग वातावरण में इस डेटा प्रकार का उपयोग करने वाले ग्राहक से बात करने के बाद, मुझे गैर-नल मानों को संग्रहीत करने की लागत को समझने में दिलचस्पी थी। वे लेखन प्रदर्शन को अनुकूलित करना चाह रहे हैं, और मुझे आश्चर्य है कि क्या विरल स्तंभों के उपयोग का कोई प्रभाव पड़ा है, क्योंकि उनकी विधि के लिए तालिका में एक पंक्ति सम्मिलित करना, फिर उसे अद्यतन करना आवश्यक है। मैंने इस डेमो के लिए एक काल्पनिक उदाहरण बनाया, जिसे नीचे समझाया गया है, यह निर्धारित करने के लिए कि क्या यह उनके लिए उपयोग करने के लिए एक अच्छी पद्धति थी।
आंतरिक समीक्षा
एक त्वरित समीक्षा के रूप में, याद रखें कि जब आप किसी तालिका के लिए एक कॉलम बनाते हैं जो NULL मानों की अनुमति देता है, यदि यह एक निश्चित-लंबाई वाला कॉलम (जैसे एक INT) है, तो यह हमेशा पेज पर पूरे कॉलम की चौड़ाई का उपभोग करेगा, भले ही कॉलम है व्यर्थ। यदि यह एक चर-लंबाई वाला कॉलम है (जैसे VARCHAR), तो यह कॉलम ऑफ़सेट सरणी में कम से कम दो बाइट्स का उपभोग करेगा जब NULL, जब तक कि कॉलम अंतिम आबादी वाले कॉलम के बाद न हों (देखें किम्बर्ली का ब्लॉग पोस्ट कॉलम ऑर्डर कोई फर्क नहीं पड़ता ... आम तौर पर , लेकिन - यह निर्भर करता है)। एक विरल स्तंभ को NULL मानों के लिए पृष्ठ पर किसी स्थान की आवश्यकता नहीं होती है, चाहे वह एक निश्चित-लंबाई वाला या चर-लंबाई वाला स्तंभ हो, और तालिका में अन्य स्तंभों की आबादी की परवाह किए बिना। व्यापार बंद यह है कि जब एक स्पैस कॉलम पॉप्युलेट होता है, तो गैर-स्पैस कॉलम की तुलना में स्टोरेज के चार (4) अधिक बाइट्स लगते हैं। उदाहरण के लिए:
| कॉलम का प्रकार | भंडारण आवश्यकता |
|---|---|
| बिगिनट कॉलम, गैर-स्पैस, नहीं के साथ मूल्य | 8 बाइट्स |
| BIGINT कॉलम, गैर-स्पैस, साथ एक मान | 8 बाइट्स |
| बिगिनट कॉलम, विरल, नहीं के साथ मूल्य | 0 बाइट्स |
| BIGINT कॉलम, विरल, साथ एक मान | 12 बाइट्स |
इसलिए, यह पुष्टि करना आवश्यक है कि भंडारण लाभ पुनर्प्राप्ति के संभावित प्रदर्शन हिट से अधिक है - जो डेटा के खिलाफ पढ़ने और लिखने के संतुलन के आधार पर नगण्य हो सकता है। विभिन्न डेटा प्रकारों के लिए अनुमानित स्थान बचत को ऊपर दिए गए पुस्तकें ऑनलाइन लिंक में प्रलेखित किया गया है।
परीक्षण परिदृश्य
मैंने नीचे वर्णित परीक्षण के लिए चार अलग-अलग परिदृश्य स्थापित किए, और प्रत्येक तालिका में एक आईडी कॉलम (INT), एक नाम कॉलम (VARCHAR (100)), और एक टाइप कॉलम (INT), और फिर 997 NULLABLE कॉलम थे।
| टेस्ट आईडी | टेबल विवरण | <थ>डीएमएल संचालन|
|---|---|---|
| 1 | INT डेटा प्रकार के 997 कॉलम, NULLABLE, गैर-स्पैस | एक बार में एक पंक्ति डालें, आईडी, नाम, प्रकार, और दस (10) रैंडम NULLABLE कॉलम को पॉप्युलेट करना |
| 2 | INT डेटा प्रकार के 997 कॉलम, NULLABLE, विरल | एक बार में एक पंक्ति डालें, आईडी, नाम, प्रकार, और दस (10) रैंडम NULLABLE कॉलम को पॉप्युलेट करना |
| 3 | INT डेटा प्रकार के 997 कॉलम, NULLABLE, गैर-स्पैस | एक समय में एक पंक्ति डालें, आईडी, नाम, केवल टाइप करें, फिर पंक्ति को अपडेट करें, दस (10) रैंडम NULLABLE कॉलम के लिए मान जोड़ें |
| 4 | INT डेटा प्रकार के 997 कॉलम, NULLABLE, विरल | एक समय में एक पंक्ति डालें, आईडी, नाम, केवल टाइप करें, फिर पंक्ति को अपडेट करें, दस (10) रैंडम NULLABLE कॉलम के लिए मान जोड़ें |
| 5 | VARCHAR डेटा प्रकार के 997 कॉलम, NULLABLE, गैर-स्पैस | एक बार में एक पंक्ति डालें, आईडी, नाम, प्रकार, और दस (10) रैंडम NULLABLE कॉलम को पॉप्युलेट करना |
| 6 | VARCHAR डेटा प्रकार के 997 कॉलम, NULLABLE, विरल | एक बार में एक पंक्ति डालें, आईडी, नाम, प्रकार, और दस (10) रैंडम NULLABLE कॉलम को पॉप्युलेट करना |
| 7 | VARCHAR डेटा प्रकार के 997 कॉलम, NULLABLE, गैर-स्पैस | एक समय में एक पंक्ति डालें, आईडी, नाम, केवल टाइप करें, फिर पंक्ति को अपडेट करें, दस (10) रैंडम NULLABLE कॉलम के लिए मान जोड़ें |
| 8 | VARCHAR डेटा प्रकार के 997 कॉलम, NULLABLE, विरल | एक समय में एक पंक्ति डालें, आईडी, नाम, केवल टाइप करें, फिर पंक्ति को अपडेट करें, दस (10) रैंडम NULLABLE कॉलम के लिए मान जोड़ें |
प्रत्येक परीक्षण दो बार 10 मिलियन पंक्तियों के डेटा सेट के साथ चलाया गया था। संलग्न लिपियों का उपयोग परीक्षण को दोहराने के लिए किया जा सकता है, और प्रत्येक परीक्षण के लिए चरण निम्नानुसार थे:
- पूर्व-आकार के डेटा और लॉग फ़ाइलों के साथ एक नया डेटाबेस बनाएं
- उपयुक्त तालिका बनाएं
- स्नैपशॉट प्रतीक्षा आँकड़े और फ़ाइल आँकड़े
- प्रारंभ समय नोट करें
- 10 मिलियन पंक्तियों के लिए DML (एक इंसर्ट, या एक इंसर्ट और एक अपडेट) निष्पादित करें
- स्टॉप टाइम नोट करें
- स्नैपशॉट प्रतीक्षा आँकड़े और फ़ाइल आँकड़े और अलग भंडारण पर एक अलग डेटाबेस में एक लॉगिंग टेबल पर लिखें
- स्नैपशॉट dm_db_index_physical_stats
- डेटाबेस छोड़ें
परीक्षण एक Dell PowerEdge R720 पर 64GB मेमोरी और 12GB SQL Server 2014 SP1 CU4 इंस्टेंस के लिए आवंटित के साथ किया गया था। फ़्यूज़न-आईओ एसएसडी का उपयोग डेटाबेस फ़ाइलों के लिए डेटा संग्रहण के लिए किया गया था।
परिणाम
प्रत्येक परीक्षण परिदृश्य के लिए परीक्षा परिणाम नीचे प्रस्तुत किए गए हैं।
अवधि
सभी मामलों में, तालिका को पॉप्युलेट करने में कम समय (औसत 11.6 मिनट) लगा, जब स्पैस कॉलम का उपयोग किया गया था, तब भी जब पंक्ति को पहले डाला गया था, फिर अपडेट किया गया था। जब पंक्ति को पहले डाला गया, फिर अपडेट किया गया, तो परीक्षण को चलने में लगभग दोगुना समय लगा, जब पंक्ति को सम्मिलित किया गया था, क्योंकि दो बार कई डेटा संशोधनों को निष्पादित किया गया था।
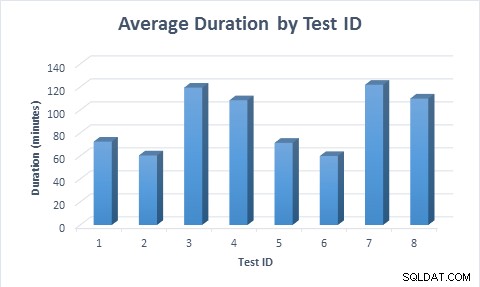 प्रत्येक परीक्षण परिदृश्य के लिए औसत अवधि
प्रत्येक परीक्षण परिदृश्य के लिए औसत अवधि
प्रतीक्षा आंकड़े
| टेस्ट आईडी | औसत प्रतिशत | औसत प्रतीक्षा (सेकंड) |
|---|---|---|
| 1 | 16.47 | 0.0001 |
| 2 | 14.00 | 0.0001 |
| 3 | 16.65 | 0.0001 |
| 4 | 15.07 | 0.0001 |
| 5 | 12.80 | 0.0001 |
| 6 | 13.99 | 0.0001 |
| 7 | 14.85 | 0.0001 |
| 8 | 15.02 | 0.0001 |
प्रतीक्षा के आँकड़े सभी परीक्षणों के लिए सुसंगत थे और इस डेटा के आधार पर कोई निष्कर्ष नहीं निकाला जा सकता है। हार्डवेयर सभी परीक्षण मामलों में संसाधन की मांग को पर्याप्त रूप से पूरा करता है।
फाइल आंकड़े
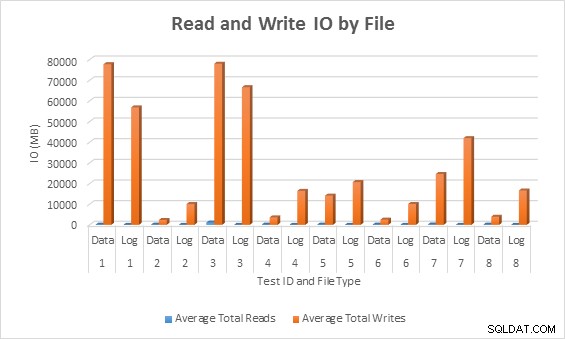 प्रति डेटाबेस फ़ाइल औसत IO (पढ़ें और लिखें)
प्रति डेटाबेस फ़ाइल औसत IO (पढ़ें और लिखें)
सभी मामलों में, विरल स्तंभों वाले परीक्षणों ने गैर-विरल स्तंभों की तुलना में कम IO (विशेष रूप से लिखते हैं) उत्पन्न किए।
भौतिक आंकड़े इंडेक्स करें
| टेस्ट केस | पंक्ति गणना | कुल पृष्ठ संख्या (संकुल अनुक्रमणिका) | कुल स्थान (GB) | सीआई (%) में लीफ पृष्ठों के लिए प्रयुक्त औसत स्थान | औसत रिकॉर्ड आकार (बाइट्स) |
|---|---|---|---|---|---|
| 1 | 10,000,000 | 10,037,312 | 76 | 51.70 | 4,184.49 |
| 2 | 10,000,000 | 301,429 | 2 | 98.51 | 237.50 |
| 3 | 10,000,000 | 10,037,312 | 76 | 51.70 | 4,184.50 |
| 4 | 10,000,000 | 460,960 | 3 | 64.41 | 237.50 |
| 5 | 10,000,000 | 1,823,083 | 13 | 90.31 | 1,326.08 |
| 6 | 10,000,000 | 324,162 | 2 | 98.40 | 255.28 |
| 7 | 10,000,000 | 3,161,224 | 24 | 52.09 | 1,326.39 |
| 8 | 10,000,000 | 503,592 | 3 | 63.33 | 255.28 |
गैर-विरल और विरल तालिकाओं के बीच अंतरिक्ष उपयोग में महत्वपूर्ण अंतर मौजूद हैं। परीक्षण मामलों 1 और 3 को देखते समय यह सबसे उल्लेखनीय है, जहां परीक्षण मामलों 5 और 7 की तुलना में एक निश्चित-लंबाई डेटा प्रकार (INT) का उपयोग किया गया था, जहां एक चर लंबाई डेटा प्रकार का उपयोग किया गया था (VARCHAR(255))। पूर्णांक कॉलम NULL होने पर भी डिस्क स्थान का उपभोग करता है। चर लंबाई वाले कॉलम कम डिस्क स्थान का उपभोग करते हैं, क्योंकि NULL कॉलम के लिए ऑफ़सेट सरणी में केवल दो बाइट्स का उपयोग किया जाता है, और उन NULL कॉलम के लिए कोई बाइट्स नहीं होते हैं जो पंक्ति में अंतिम पॉपुलेटेड कॉलम के बाद होते हैं।
इसके अलावा, एक पंक्ति को सम्मिलित करने और फिर इसे अद्यतन करने की प्रक्रिया केवल पंक्ति (केस 5) को सम्मिलित करने की तुलना में चर-लंबाई कॉलम परीक्षण (केस 7) के लिए विखंडन का कारण बनती है। जब इंसर्ट के बाद अपडेट होता है तो टेबल का आकार लगभग दोगुना हो जाता है, क्योंकि पेज स्प्लिट जो पंक्तियों को अपडेट करते समय होते हैं, जिससे पेज आधा भरा रहता है (बनाम 90% भरा हुआ)।
सारांश
अंत में, हम डिस्क स्थान और IO में एक महत्वपूर्ण कमी देखते हैं जब विरल स्तंभों का उपयोग किया जाता है, और वे हमारे साधारण डेटा संशोधन परीक्षणों में गैर-स्पैस स्तंभों की तुलना में थोड़ा बेहतर प्रदर्शन करते हैं (ध्यान दें कि पुनर्प्राप्ति प्रदर्शन पर भी विचार किया जाना चाहिए; शायद दूसरे का विषय पोस्ट)।
विरल स्तंभों में एक बहुत ही विशिष्ट उपयोग परिदृश्य होता है और कॉलम के डेटा प्रकार और आमतौर पर तालिका में पॉप्युलेट किए जाने वाले स्तंभों की संख्या के आधार पर सहेजे गए डिस्क स्थान की मात्रा की जांच करना महत्वपूर्ण है। हमारे उदाहरण में, हमारे पास 997 विरल स्तंभ थे, और हमने उनमें से केवल 10 को ही आबाद किया था। अधिक से अधिक, उस स्थिति में जहां उपयोग किया गया डेटा प्रकार पूर्णांक था, क्लस्टर इंडेक्स के लीफ स्तर पर एक पंक्ति 188 बाइट्स (आईडी के लिए 4 बाइट्स, नाम के लिए अधिकतम 100 बाइट्स, प्रकार के लिए 4 बाइट्स, और फिर उपभोग करेगी) 10 कॉलम के लिए 80 बाइट्स)। जब 997 कॉलम गैर-स्पैस थे, तब प्रत्येक कॉलम के लिए 4 बाइट आवंटित किए गए थे, भले ही न्यूल हो, इसलिए प्रत्येक पंक्ति पत्ती स्तर पर कम से कम 4,000 बाइट्स थी। हमारे परिदृश्य में, विरल स्तंभ बिल्कुल स्वीकार्य हैं। लेकिन अगर हम INT कॉलम के मानों के साथ 500 या अधिक विरल कॉलम पॉप्युलेट करते हैं, तो स्थान की बचत खो जाती है, और संशोधन का प्रदर्शन अब बेहतर नहीं हो सकता है।
आपके स्तंभों के लिए डेटा प्रकार और कुल में से भरे जाने वाले स्तंभों की अपेक्षित संख्या के आधार पर, आप यह सुनिश्चित करने के लिए समान परीक्षण करना चाह सकते हैं कि, विरल स्तंभों का उपयोग करते समय, सम्मिलित प्रदर्शन और संग्रहण गैर का उपयोग करते समय तुलनीय या बेहतर हैं -विरल स्तंभ। उन मामलों के लिए जब सभी कॉलम पॉप्युलेट नहीं होते हैं, विरल कॉलम निश्चित रूप से विचार करने योग्य होते हैं।