यह एक SQL सर्वर आंतरिक समस्याग्रस्त ऑपरेटर्स श्रृंखला का हिस्सा है। इस विषय पर कलेन की पहली पोस्ट और दूसरी पोस्ट अवश्य पढ़ें।
SQL सर्वर को लगभग 30 वर्षों से अधिक हो गया है, और मैं लगभग लंबे समय से SQL सर्वर के साथ काम कर रहा हूँ। मैंने इस अविश्वसनीय उत्पाद के वर्षों (और दशकों!) और संस्करणों में बहुत सारे बदलाव देखे हैं। इन पोस्ट में, मैं आपके साथ साझा करूँगा कि मैं SQL सर्वर की कुछ विशेषताओं या पहलुओं को कैसे देखता हूँ, कभी-कभी कुछ ऐतिहासिक परिप्रेक्ष्य के साथ।
पिछली बार मैंने SQL सर्वर क्वेरी प्लान में हैशिंग के बारे में SQL सर्वर डायग्नोस्टिक्स में संभावित समस्याग्रस्त ऑपरेटर के रूप में बात की थी। जब कोई उपयोगी अनुक्रमणिका नहीं होती है तो हैशिंग का उपयोग अक्सर जुड़ने और एकत्रीकरण के लिए किया जाता है। और स्कैन की तरह (जिसके बारे में मैंने इस श्रृंखला में पहली पोस्ट में बात की थी), ऐसे समय होते हैं जब हैशिंग वास्तव में विकल्पों की तुलना में बेहतर विकल्प होता है। हैश जॉइन के लिए, विकल्पों में से एक है LOOP JOIN, जिसके बारे में मैंने आपको पिछली बार भी बताया था।
इस पोस्ट में, मैं आपको हैशिंग के एक और विकल्प के बारे में बताऊंगा। हैशिंग के अधिकांश विकल्पों में डेटा को सॉर्ट करने की आवश्यकता होती है, इसलिए या तो योजना में एक SORT ऑपरेटर को शामिल करने की आवश्यकता होती है, या मौजूदा इंडेक्स के कारण आवश्यक डेटा पहले से ही सॉर्ट किया जाना चाहिए।
SQL सर्वर निदान के लिए विभिन्न प्रकार के जॉइन
जॉइन ऑपरेशंस के लिए, जॉइन का सबसे आम और उपयोगी प्रकार लूप जॉइन है। मैंने पिछली पोस्ट में लूप जॉइन के लिए एल्गोरिदम का वर्णन किया था। हालाँकि डेटा को लूप जॉइन के लिए सॉर्ट करने की आवश्यकता नहीं होती है, आंतरिक टेबल पर एक इंडेक्स की उपस्थिति जुड़ने को और अधिक कुशल बनाती है और जैसा कि आपको पता होना चाहिए, एक इंडेक्स की उपस्थिति का अर्थ कुछ सॉर्टिंग है। जबकि क्लस्टर्ड इंडेक्स डेटा को स्वयं सॉर्ट करता है, गैर-क्लस्टर इंडेक्स इंडेक्स कुंजी कॉलम को सॉर्ट करता है। वास्तव में, ज्यादातर मामलों में, इंडेक्स के बिना, SQL सर्वर का ऑप्टिमाइज़र HASH JOIN एल्गोरिथम का उपयोग करना चुनता है। हमने इसे पिछली बार के उदाहरण में देखा था, कि बिना इंडेक्स के, हैश जॉइन को चुना गया था, और इंडेक्स के साथ, हमें लूप जॉइन मिला।
तीसरे प्रकार का जुड़ाव MERGE JOIN है। यह एल्गोरिथम पहले से छांटे गए दो डेटासेट पर काम करता है। यदि हम पहले से सॉर्ट किए गए डेटा के दो सेटों को संयोजित (या जॉइन) करने का प्रयास कर रहे हैं, तो मिलान वाली पंक्तियों को खोजने के लिए प्रत्येक सेट के माध्यम से केवल एक ही पास लेता है। यहाँ मर्ज जॉइन एल्गोरिथम के लिए स्यूडोकोड है:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
हालांकि MERGE JOIN एक बहुत ही कुशल एल्गोरिथम है, इसके लिए यह आवश्यक है कि दोनों इनपुट डेटासेट को जॉइन की द्वारा सॉर्ट किया जाए, जिसका आमतौर पर मतलब है कि दोनों टेबलों के लिए जॉइन की पर एक क्लस्टर इंडेक्स होना। चूंकि आपको प्रति तालिका केवल एक क्लस्टर इंडेक्स मिलता है, क्लस्टर कुंजी कॉलम को केवल मर्ज जॉइन होने की अनुमति देने के लिए क्लस्टरिंग कुंजी के लिए सबसे अच्छा समग्र विकल्प नहीं हो सकता है।
इसलिए आमतौर पर, मैं अनुशंसा नहीं करता कि आप केवल MERGE JOINS के उद्देश्य से अनुक्रमणिका बनाने का प्रयास करें, लेकिन यदि आप पहले से मौजूद अनुक्रमणिका के कारण MERGE JOIN प्राप्त करते हैं, तो यह आमतौर पर एक अच्छी बात है। दोनों इनपुट डेटासेट को सॉर्ट करने की आवश्यकता के अलावा, MERGE JOIN के लिए यह भी आवश्यक है कि कम से कम एक डेटासेट में जॉइन की के लिए अद्वितीय मान हों।
आइए एक उदाहरण देखें। सबसे पहले, हम हेडर . को फिर से बनाएंगे और विवरण टेबल:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
इसके बाद, इन तालिकाओं के बीच जुड़ने की योजना देखें:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
ये रही योजना:

ध्यान दें कि दोनों टेबलों पर क्लस्टर इंडेक्स के साथ भी, हमें हैश जॉइन मिलता है। हम UNIQUE होने के लिए किसी एक अनुक्रमणिका का पुनर्निर्माण कर सकते हैं। इस मामले में, इसे हेडर . पर इंडेक्स होना चाहिए तालिका, क्योंकि केवल वही है जिसमें SalesOrderID. . के लिए अद्वितीय मान हैं
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
अब, क्वेरी को फिर से चलाएँ, और ध्यान दें कि योजना MERGE JOIN कैसे करती है।

इन योजनाओं को पहले से ही एक इंडेक्स में डेटा को सॉर्ट करने से लाभ होता है, क्योंकि निष्पादन योजना सॉर्टिंग का लाभ उठा सकती है। लेकिन कभी-कभी, SQL सर्वर को अपने क्वेरी निष्पादन के भाग के रूप में छँटाई करनी पड़ती है। आप कभी-कभी किसी योजना में SORT ऑपरेटर को दिखाई दे सकते हैं, भले ही आप सॉर्ट किए गए आउटपुट के लिए न कहें। यदि SQL सर्वर को लगता है कि MERGE JOIN एक अच्छा विकल्प हो सकता है, लेकिन तालिकाओं में से एक में उपयुक्त क्लस्टर इंडेक्स नहीं है, और यह छँटाई को बहुत सस्ता बनाने के लिए काफी छोटा है, तो MERGE JOIN को अनुमति देने के लिए एक सॉर्ट किया जा सकता है। इस्तेमाल किया।
लेकिन आमतौर पर, SORT ऑपरेटर उन प्रश्नों में दिखाई देता है जहां हमने ORDER BY के साथ सॉर्ट किए गए डेटा के लिए कहा है, जैसा कि निम्नलिखित उदाहरण में है।
SELECT * FROM Details
ORDER BY ProductID;
GO

संकुल सूचकांक को स्कैन किया जाता है (जो तालिका को स्कैन करने के समान है) और फिर पंक्तियों को अनुरोध के अनुसार क्रमबद्ध किया जाता है।
पहले से सॉर्ट किए गए क्लस्टर इंडेक्स से निपटना
लेकिन क्या होगा यदि डेटा पहले से ही क्लस्टर इंडेक्स में सॉर्ट किया गया है, और क्वेरी में क्लस्टर कुंजी कॉलम पर ऑर्डर शामिल है? ऊपर के उदाहरण में, हमने विवरण तालिका में SalesOrderID पर एक संकुल सूचकांक बनाया है। निम्नलिखित दो प्रश्नों को देखें:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
यदि हम इन प्रश्नों को एक साथ चलाते हैं, तो क्वेस्ट स्पॉटलाइट ट्यूनिंग पैक विश्लेषण विंडो इंगित करती है कि दोनों योजनाएँ समान लागत वाली हैं; प्रत्येक कुल का 50% है। तो, वास्तव में उनके बीच क्या अंतर है?
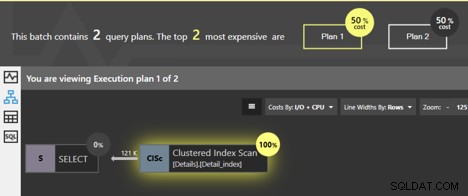
दोनों क्वेश्चन क्लस्टर्ड इंडेक्स को स्कैन कर रहे हैं और SQL सर्वर जानता है कि यदि लीफ लेवल के पेजों को क्रम में फॉलो किया जाता है, तो डेटा क्लस्टर्ड की ऑर्डर में वापस आ जाएगा। कोई अतिरिक्त छँटाई करने की आवश्यकता नहीं है, इसलिए योजना में कोई SORT ऑपरेटर नहीं जोड़ा गया है। लेकिन एक अंतर है। हम क्लस्टर्ड इंडेक्स स्कैन ऑपरेटर पर क्लिक कर सकते हैं और कुछ विस्तृत जानकारी प्राप्त करेंगे।
पहले, ORDER BY के बिना क्वेरी के लिए, पहली योजना के लिए विस्तृत जानकारी देखें।

विवरण हमें बताते हैं कि "आदेशित" संपत्ति गलत है। यहां कोई आवश्यकता नहीं है कि डेटा क्रमबद्ध क्रम में लौटाया जाए। यह पता चला है कि ज्यादातर मामलों में, डेटा को पुनः प्राप्त करने का सबसे आसान तरीका क्लस्टर इंडेक्स के पृष्ठों का पालन करना है, इसलिए डेटा अंत में क्रम में वापस आ जाएगा, लेकिन इसकी कोई गारंटी नहीं है। झूठी संपत्ति का मतलब यह है कि परिणाम वापस करने के लिए SQL सर्वर द्वारा आदेशित पृष्ठों का पालन करने की कोई आवश्यकता नहीं है। वास्तव में ऐसे अन्य तरीके हैं जिनसे SQL सर्वर क्लस्टर इंडेक्स का पालन किए बिना तालिका के लिए सभी पंक्तियां प्राप्त कर सकता है। यदि निष्पादन के दौरान, SQL सर्वर पंक्तियों को प्राप्त करने के लिए किसी भिन्न विधि का उपयोग करना चुनता है, तो हमें आदेशित परिणाम नहीं दिखाई देंगे।
दूसरी क्वेरी के लिए, विवरण इस तरह दिखता है:
 चूंकि क्वेरी में ORDER BY शामिल है, इसलिए एक आवश्यकता है कि डेटा को क्रमबद्ध क्रम में वापस किया जाए और SQL सर्वर क्रम में संकुल अनुक्रमणिका के पृष्ठों का अनुसरण करेगा।
चूंकि क्वेरी में ORDER BY शामिल है, इसलिए एक आवश्यकता है कि डेटा को क्रमबद्ध क्रम में वापस किया जाए और SQL सर्वर क्रम में संकुल अनुक्रमणिका के पृष्ठों का अनुसरण करेगा।
यहां याद रखने वाली सबसे महत्वपूर्ण बात यह है कि यदि आप अपनी क्वेरी में ORDER BY शामिल नहीं करते हैं तो सॉर्ट किए गए डेटा की कोई गारंटी नहीं है। सिर्फ इसलिए कि आपके पास एक संकुल सूचकांक है, अभी भी कोई गारंटी नहीं है! यहां तक कि अगर पिछले साल हर बार जब आपने क्वेरी चलाई, तो आपको ऑर्डर के बिना डेटा वापस मिल गया, इस बात की कोई गारंटी नहीं है कि आप डेटा को क्रम में वापस प्राप्त करना जारी रखेंगे। ORDER BY का उपयोग करना उस क्रम की गारंटी देने का एकमात्र तरीका है जिसमें आपके परिणाम लौटाए जाते हैं।
सॉर्ट ऑपरेशंस का उपयोग करने के लिए टिप्स
तो, SQL सर्वर डायग्नोस्टिक्स में SORT एक ऑपरेशन से बचा जाना है? स्कैन और हैश ऑपरेशंस की तरह, इसका उत्तर निश्चित रूप से है, 'यह निर्भर करता है'। छँटाई बहुत महंगी हो सकती है, खासकर बड़े डेटासेट पर। उचित अनुक्रमण SQL सर्वर को SORT संचालन करने से बचने में मदद करता है क्योंकि एक अनुक्रमणिका का मूल रूप से मतलब है कि आपका डेटा पूर्वनिर्धारित है। लेकिन अनुक्रमण एक लागत के साथ आता है। प्रत्येक सूचकांक के लिए रखरखाव लागत के अलावा भंडारण लागत भी है। यदि आपका डेटा अत्यधिक अपडेट किया गया है, तो आपको अनुक्रमितों की संख्या न्यूनतम रखने की आवश्यकता है।
यदि आप पाते हैं कि आपके कुछ धीमी गति से चलने वाले प्रश्न उनकी योजनाओं में SORT संचालन दिखाते हैं, और यदि वे SORT योजना के सबसे महंगे ऑपरेटरों में से हैं, तो आप अनुक्रमणिका बनाने पर विचार कर सकते हैं जो SQL सर्वर को छँटाई से बचने की अनुमति देता है। लेकिन आपको यह सुनिश्चित करने के लिए पूरी तरह से परीक्षण करने की आवश्यकता होगी कि अतिरिक्त अनुक्रमणिका अन्य प्रश्नों को धीमा न करें जो आपके समग्र एप्लिकेशन प्रदर्शन के लिए महत्वपूर्ण हैं।