परिचय
एक तालिका एक तार्किक संरचना है। जब आप एक टेबल बनाते हैं, तो आप आमतौर पर परवाह नहीं करेंगे कि यह स्टोरेज लेयर पर किस ड्राइव पर बैठता है। हालाँकि, यदि आप एक डेटाबेस व्यवस्थापक हैं, तो यह ज्ञान आवश्यक हो सकता है यदि आपको कुछ डेटाबेस भागों को वैकल्पिक संग्रहण या वॉल्यूम में स्थानांतरित करने की आवश्यकता है। फिर, आप चाहते हैं कि निश्चित तालिकाएँ किसी विशेष वॉल्यूम या डिस्क के सेट पर हों।
SQL सर्वर में फ़ाइलग्रुप उस अमूर्त परत की पेशकश करते हैं जो हमें हमारी तार्किक संरचनाओं के भौतिक स्थान को नियंत्रित करने की अनुमति देती है - टेबल, इंडेक्स, आदि।
फ़ाइल समूह
फ़ाइल समूह SQL सर्वर में डेटा फ़ाइलों को समूहीकृत करने के लिए एक तार्किक संरचना है। अगर हम एक फाइलग्रुप बनाते हैं और इसे डेटा फाइलों के एक सेट के साथ जोड़ते हैं, तो उस फाइलग्रुप पर बनाई गई कोई भी लॉजिकल ऑब्जेक्ट भौतिक फाइलों के उस सेट पर भौतिक रूप से स्थित होगी।
ऐसे भौतिक फ़ाइल समूहन का प्राथमिक उद्देश्य डेटा आवंटन और डेटा प्लेसमेंट है। उदाहरण के लिए, हम चाहते हैं कि हमारा लेनदेन डेटा फास्ट डिस्क के एक सेट पर संग्रहीत हो। साथ ही, हमें कम खर्चीले डिस्क के दूसरे सेट पर संग्रहीत ऐतिहासिक डेटा की आवश्यकता होती है। ऐसी स्थिति में, हम ट्रॅन . बनाएंगे TXN फ़ाइल समूह और TranHist . पर तालिका एक अलग HIST फ़ाइल समूह पर तालिका। आगे इस लेख में, हम देखेंगे कि यह विभिन्न डिस्क पर डेटा रखने के लिए कैसे अनुवाद करता है।
फ़ाइल समूह बनाना
फ़ाइल समूह बनाने का सिंटैक्स लिस्टिंग 1 . में दिखाया गया है . नोट :डेटाबेस संदर्भ मास्टर है डेटाबेस। बयान जारी करने में, हम इसमें नए फ़ाइल समूह जोड़कर DB2 डेटाबेस को बदल रहे हैं। अनिवार्य रूप से, ये फ़ाइल समूह इस बिंदु पर केवल तार्किक निर्माण हैं। उनमें कोई डेटा नहीं है।
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
फ़ाइल समूह में फ़ाइलें जोड़ना
अगला चरण प्रत्येक फ़ाइल समूह में एक फ़ाइल जोड़ना है। हम एक से अधिक फाइल जोड़ सकते हैं, लेकिन हम इसे प्रदर्शन उद्देश्यों के लिए सरल रखते हैं। ध्यान दें कि प्रत्येक फ़ाइल पूरी तरह से एक अलग ड्राइव पर है, और सिंटैक्स हमें इच्छित फ़ाइल समूह को निर्दिष्ट करने की अनुमति देता है।
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
फ़ाइल समूहों में तालिकाएं बनाना
यहां हम सुनिश्चित करते हैं कि टेबल वांछित डिस्क पर हों। टेबल बनाने का सिंटैक्स हमें अपने इच्छित फ़ाइल समूह को निर्दिष्ट करने की अनुमति देता है।
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
एक कदम पीछे लेते हुए, हम देखते हैं कि अब हमने निम्नलिखित हासिल कर लिया है:
- दो फ़ाइल समूह बनाए।
- प्रत्येक फ़ाइल समूह से संबद्ध डेटा फ़ाइलों (और डिस्क) को निर्धारित किया।
- प्रत्येक फ़ाइल समूह से संबद्ध तालिकाओं का निर्धारण किया।
संक्षेप में, फ़ाइल समूह अमूर्त परत है ।
यह जांचना कि हमारे टेबल किस फ़ाइल समूह पर बैठे हैं
यह जांचने के लिए कि प्रत्येक तालिका किस फ़ाइल समूह से संबंधित है, हम लिस्टिंग 4 में कोड निष्पादित करेंगे। हम दो मुख्य सिस्टम कैटलॉग दृश्यों का उपयोग करते हैं:sys.indexes और sys.data_spaces . sys.data_spaces कैटलॉग व्यू में फाइलग्रुप्स और पार्टिशन्स और मुख्य तार्किक संरचनाओं के बारे में जानकारी होती है जहां टेबल और इंडेक्स संग्रहीत होते हैं।
नोट:हमने sys.tables का उपयोग नहीं किया . जैसा कि हम सहज रूप से सोच सकते हैं, SQL सर्वर इंडेक्स को टेबल के बजाय डेटा स्पेस के साथ एक टेबल में जोड़ता है।
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
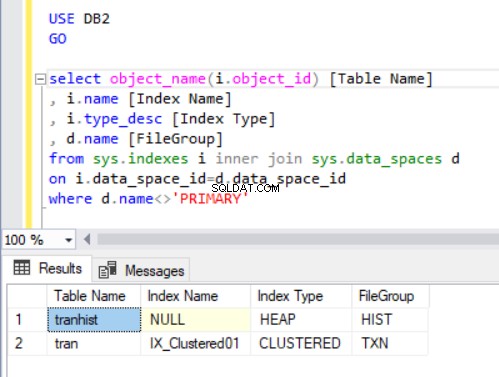
लिस्टिंग 4 में क्वेरी का आउटपुट हमारे द्वारा अभी बनाई गई दो तालिकाओं को प्रदर्शित करता है। ध्यान दें कि ट्रांहिस्ट तालिका में कोई अनुक्रमणिका नहीं है। फिर भी, यह परिणाम सेट में दिखाई देता है, जिसे ढेर . के रूप में पहचाना जाता है ।
एक ढेर एक तालिका है जिसमें तालिका में भौतिक रूप से संग्रहीत ऑर्डर डेटा को निर्धारित करने वाला कोई क्लस्टर इंडेक्स नहीं है। एक तालिका में केवल एक संकुल अनुक्रमणिका हो सकती है।
ट्रान तालिका को आबाद करना
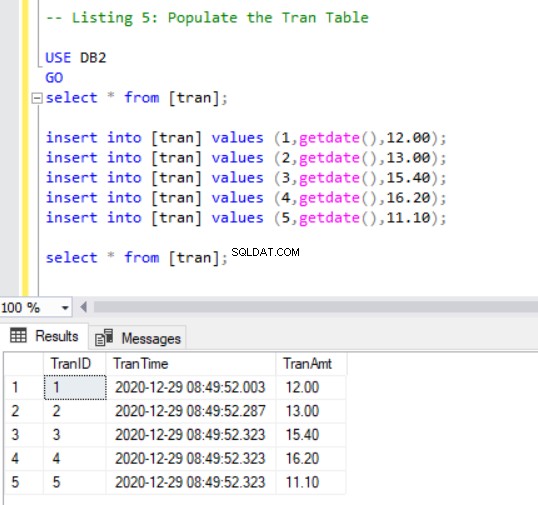
अब, हमें ट्रान . में कुछ रिकॉर्ड जोड़ने होंगे निम्नलिखित कोड का उपयोग कर तालिका:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
तालिका को किसी अन्य फ़ाइल समूह में ले जाना
ट्रान . को स्थानांतरित करने के लिए किसी अन्य फ़ाइल समूह के लिए तालिका, हमें केवल संकुल अनुक्रमणिका का पुनर्निर्माण . करने की आवश्यकता है और यह पुनर्निर्माण करते समय नया फ़ाइल समूह निर्दिष्ट करें। लिस्टिंग 5 इस दृष्टिकोण को दर्शाता है।
हम दो चरणों का पालन करते हैं:पहले, इंडेक्स को ड्रॉप करें, फिर इसे फिर से बनाएं। बीच में, हम यह पुष्टि करने के लिए जाँच करते हैं कि हमारे द्वारा पहले बनाई गई दो तालिकाओं का डेटा और स्थान बरकरार है।
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
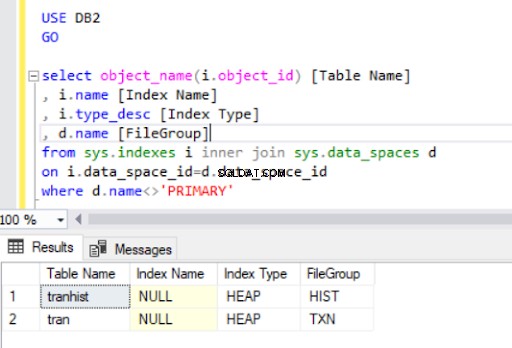
ट्रॅन . से संकुल अनुक्रमणिका को छोड़ने में तालिका, हमने इसे ढेर . में बदल दिया है :
जब हम क्लस्टर इंडेक्स को फिर से बनाते हैं, तो यह लिस्टिंग 4 आउटपुट में भी इंगित होता है।
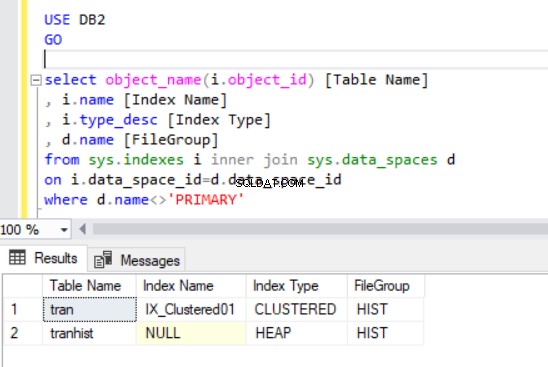
अब हमारे पास ट्रान . है HIST फ़ाइल समूह पर तालिका।
निष्कर्ष
यह आलेख हमारे SQL सर्वर डेटा संग्रहण के संदर्भ में तालिकाओं, अनुक्रमणिकाओं, फ़ाइलों और फ़ाइल समूहों के बीच संबंध को प्रदर्शित करता है। हमने क्लस्टर इंडेक्स को फिर से बनाकर एक टेबल को एक फाइलग्रुप से दूसरे फाइल ग्रुप में ले जाने के बारे में भी बताया है।
यह कौशल तब मददगार होगा जब आपको डेटा को नए संग्रहण (संग्रह के लिए तेज़ डिस्क या धीमी डिस्क) में स्थानांतरित करने की आवश्यकता होगी। अधिक उन्नत परिदृश्यों में, आप तालिका विभाजन को लागू करके डेटा जीवनचक्र को प्रबंधित करने के लिए फ़ाइल समूह का उपयोग कर सकते हैं।
संदर्भ
- डेटाबेस फ़ाइलें और फ़ाइल समूह
- स्विच आउट टेबल विभाजन - एक पूर्वाभ्यास