SQL सर्वर अनुक्रमणिका का परिचय
Microsoft SQL सर्वर को संबंधपरक डेटाबेस प्रबंधन प्रणालियों में से एक माना जाता है (RDBMS ), जिसमें डेटा तार्किक रूप से पंक्तियों और स्तंभों में व्यवस्थित होता है जो डेटा कंटेनरों में संग्रहीत होते हैं जिन्हें टेबल कहा जाता है। भौतिक रूप से, तालिकाओं को 8 KB पृष्ठों . के रूप में संग्रहीत किया जाता है जिसे हीप या बी-ट्री क्लस्टर्ड टेबल में व्यवस्थित किया जा सकता है। ढेर . में तालिका में, कोई सॉर्टिंग ऑर्डर नहीं है जो डेटा पृष्ठों के अंदर डेटा के क्रम और उस तालिका के भीतर पृष्ठों के अनुक्रम को नियंत्रित करता है, क्योंकि सॉर्टिंग तंत्र को लागू करने के लिए उस तालिका पर कोई क्लस्टर इंडेक्स परिभाषित नहीं है। यदि क्लस्टर इंडेक्स को टेबल कॉलम के समूह के एक कॉलम पर परिभाषित किया गया है, तो डेटा को क्लस्टर इंडेक्स कुंजी कॉलम के मूल्यों के आधार पर डेटा पेजों के अंदर सॉर्ट किया जाएगा, और इन इंडेक्स कुंजी मानों के आधार पर पेजों को एक साथ जोड़ा जाएगा। इस क्रमबद्ध तालिका को संकुल तालिका . कहा जाता है ।
SQL सर्वर में, इंडेक्स को प्रदर्शन ट्यूनिंग प्रक्रिया में एक महत्वपूर्ण और प्रभावी कुंजी माना जाता है। एक इंडेक्स बनाने का उद्देश्य बेस टेबल तक पहुंच को तेज करना और अनुरोधित डेटा को वापस करने के लिए सभी टेबल पंक्तियों को स्कैन किए बिना अनुरोधित डेटा को पुनः प्राप्त करना है। आप डेटाबेस इंडेक्स को एक बुक इंडेक्स के रूप में सोच सकते हैं जो आपको उस शब्द को खोजने के लिए पूरी किताब को पढ़ने के बिना, पुस्तक में शब्दों को जल्दी से खोजने में मदद करता है। उदाहरण के लिए, मान लें कि आपको ग्राहक आईडी का उपयोग करके किसी विशिष्ट ग्राहक के बारे में जानकारी प्राप्त करने की आवश्यकता है। यदि इस तालिका में ग्राहक आईडी कॉलम के लिए कोई अनुक्रमणिका परिभाषित नहीं है, तो SQL सर्वर इंजन प्रदान की गई आईडी के साथ ग्राहक को पुनः प्राप्त करने के लिए सभी तालिका पंक्तियों की एक-एक करके जांच करता है। यदि इस तालिका में ग्राहक आईडी कॉलम के लिए एक इंडेक्स परिभाषित किया गया है, तो SQL सर्वर इंजन ग्राहक के बारे में जानकारी प्राप्त करने के लिए, स्कैन की गई संख्या को कम करने के लिए, आधार तालिका के बजाय सॉर्ट किए गए इंडेक्स में अनुरोधित ग्राहक आईडी मानों की तलाश करेगा। डेटा पुनर्प्राप्त करने के लिए पंक्तियाँ।
SQL सर्वर में, अनुक्रमणिका को तार्किक रूप से 8K पृष्ठों या अनुक्रमणिका नोड्स के रूप में B-पेड़ के रूप में संरचित किया जाता है। बी-ट्री संरचना में तीन स्तर होते हैं:एक रूट स्तर जिसमें बी-पेड़ के शीर्ष पर एक अनुक्रमणिका पृष्ठ शामिल है, एक पत्ती स्तर जो बी-ट्री के निचले भाग में स्थित है और इसमें डेटा पृष्ठ और एक मध्यवर्ती स्तर है। जिसमें रूट और लीफ स्तरों के बीच स्थित सभी नोड्स शामिल हैं, जिसमें इंडेक्स कुंजी मान और निम्नलिखित पृष्ठों पर पॉइंटर्स शामिल हैं। यह बी-ट्री आकार इंडेक्स कुंजी के आधार पर डेटा पृष्ठों को बाएं से दाएं और ऊपर से नीचे तक नेविगेट करने का एक त्वरित तरीका प्रदान करता है।
SQL सर्वर में, दो मुख्य प्रकार के इंडेक्स होते हैं, एक क्लस्टर इंडेक्स, जिसमें वास्तविक डेटा को इंडेक्स के लीफ लेवल पेज पर स्टोर किया जाता है, जिसमें प्रत्येक टेबल के लिए केवल एक क्लस्टर इंडेक्स बनाने की क्षमता होती है, क्योंकि डेटा पेज के अंदर डेटा और पेजों के क्रम को क्लस्टर्ड इंडेक्स के आधार पर सॉर्ट किया जाएगा। चाबी। यदि आप अपनी तालिका में प्राथमिक कुंजी बाधा को परिभाषित करते हैं, तो क्लस्टर इंडेक्स स्वचालित रूप से बनाया जाएगा यदि उस तालिका के लिए पहले कोई क्लस्टर इंडेक्स परिभाषित नहीं किया गया था। दूसरे प्रकार की अनुक्रमणिका गैर-संकुल अनुक्रमणिका . है जिसमें इंडेक्स कुंजी कॉलम की सॉर्ट की गई कॉपी और बेस टेबल या क्लस्टर इंडेक्स में बाकी कॉलम के लिए एक पॉइंटर शामिल है, जिसमें प्रत्येक टेबल के लिए 999 गैर-क्लस्टर इंडेक्स बनाने की क्षमता है।
SQL सर्वर हमें अन्य विशेष प्रकार की अनुक्रमणिकाएँ प्रदान करता है, जैसे कि अद्वितीय अनुक्रमणिका जो स्वचालित रूप से तब बनाया जाता है जब विशिष्ट स्तंभ मानों की विशिष्टता को लागू करने के लिए एक अद्वितीय बाधा परिभाषित की जाती है, एक समग्र अनुक्रमणिका जिसमें एक से अधिक कुंजी कॉलम इंडेक्स कुंजी में भाग लेंगे, एक कवरिंग इंडेक्स जिसमें किसी विशिष्ट क्वेरी द्वारा अनुरोध किए गए सभी कॉलम इंडेक्स कुंजी, फ़िल्टर की गई अनुक्रमणिका में भाग लेंगे। यह एक अनुकूलित गैर-संकुल अनुक्रमणिका है जिसमें तालिका पंक्तियों के केवल एक छोटे से हिस्से को अनुक्रमणित करने के लिए फ़िल्टर विधेय होता है, एक स्थानिक अनुक्रमणिका यह उन स्तंभों पर बनाया जाता है जो स्थानिक डेटा संग्रहीत करते हैं, एक XML अनुक्रमणिका जो XML डेटा प्रकार स्तंभों में XML बाइनरी लार्ज ऑब्जेक्ट्स (BLOBs) पर बनाई जाती है, एक Columnstore अनुक्रमणिका जिसमें डेटा को स्तंभ डेटा प्रारूप में व्यवस्थित किया जाता है, एक पूर्ण-पाठ अनुक्रमणिका जो SQL सर्वर फुल-टेक्स्ट इंजन और एक हैश इंडेक्स . द्वारा बनाया गया है जिसका उपयोग स्मृति-अनुकूलित तालिकाओं में किया जाता है।
जैसा कि मैं SQL सर्वर इंडेक्स को कॉल करता था, यह एक दोधारी तलवार . है , जहां SQL सर्वर क्वेरी ऑप्टिमाइज़र डेटा पुनर्प्राप्ति प्रक्रिया को तेज करके आपके अनुप्रयोगों के प्रदर्शन को बेहतर बनाने के लिए अच्छी तरह से डिज़ाइन किए गए इंडेक्स से लाभ उठा सकता है। इसके विपरीत, एक इंडेक्स जिसे खराब तरीके से डिज़ाइन किया गया है, उसे SQL सर्वर क्वेरी ऑप्टिमाइज़र द्वारा नहीं चुना जाएगा और यह डेटा संशोधन संचालन को धीमा करके आपके एप्लिकेशन के प्रदर्शन को कम कर देगा और डेटा में इसका लाभ उठाए बिना आपके स्टोरेज का उपभोग करेगा। पुनर्प्राप्ति प्रक्रियाएं। इसलिए, बेहतर है कि पहले सूचकांक निर्माण की सर्वोत्तम प्रथाओं और दिशानिर्देशों का पालन करें, विकास के माहौल पर प्रभाव की जांच करें, और डेटा पुनर्प्राप्ति संचालन की गति और डेटा संशोधन संचालन पर उस सूचकांक को जोड़ने के ऊपरी हिस्से के बीच एक समझौता खोजें। और उस सूचकांक की अंतरिक्ष आवश्यकताओं को उत्पादन वातावरण में लागू करने से पहले।
एक सूचकांक बनाने से पहले, आपको उन विभिन्न पहलुओं का अध्ययन करना होगा जो सूचकांक के निर्माण और उपयोग को प्रभावित करते हैं। इसमें प्रकार . शामिल है डेटाबेस वर्कलोड, ऑनलाइन ट्रांजेक्शन प्रोसेसिंग (OLTP) या ऑनलाइन एनालिटिकल प्रोसेसिंग (OLAP), टेबल का आकार , टेबल कॉलम . की विशेषताएं , सॉर्टिंग ऑर्डर क्वेरी में कॉलम के इंडेक्स का प्रकार जो क्वेरी और भंडारण गुणों जैसे FILLFACTOR . से मेल खाती है और PAD_INDEX विकल्प जो डेटा से भरे जाने वाले प्रत्येक लीफ-लेवल और इंटरमीडिएट लेवल पेज पर स्पेस के प्रतिशत को नियंत्रित करते हैं।
SQL सर्वर अनुक्रमणिका विखंडन
डीबीए के रूप में आपका काम सही इंडेक्स बनाने तक सीमित नहीं है। एक बार सूचकांक बन जाने के बाद, आपको सूचकांक के उपयोग और आंकड़ों की निगरानी करनी चाहिए, उदाहरण के लिए, आपको यह जानना होगा कि क्या इस सूचकांक का खराब उपयोग किया गया है या बिल्कुल भी उपयोग नहीं किया गया है। इस प्रकार, आप इन इंडेक्स को बनाए रखने के लिए सही समाधान प्रदान कर सकते हैं या उन्हें अधिक कुशल लोगों के साथ बदल सकते हैं। इस तरह, आप अपने सिस्टम के लिए उच्चतम लागू प्रदर्शन बनाए रखेंगे। आप स्वयं से पूछ सकते हैं:SQL सर्वर क्वेरी ऑप्टिमाइज़र अब मेरी अनुक्रमणिका का उपयोग क्यों नहीं करता, हालाँकि उसने पहले ऐसा किया था?
उत्तर मुख्य रूप से निरंतर डेटा और स्कीमा परिवर्तनों से संबंधित है जो आधार तालिका पर किए जाते हैं जिन्हें इंडेक्स में प्रतिबिंबित किया जाना चाहिए। समय के साथ, और इन सभी परिवर्तनों के साथ, अनुक्रमणिका पृष्ठ क्रमबद्ध नहीं हो जाते हैं, जिससे अनुक्रमणिका खंडित हो जाती है। विखंडन का एक अन्य कारण एक नया मान सम्मिलित करने या वर्तमान मान को अद्यतन करने का प्रयास है, और नया मान वर्तमान में उपलब्ध खाली स्थान में फिट नहीं होता है। इस मामले में, पृष्ठ दो पृष्ठों में विभाजित हो जाएगा, जहां अंतिम पृष्ठ के बाद भौतिक रूप से नया पृष्ठ बनाया जाएगा। और आप एक खंडित सूचकांक से पढ़ने और स्कैन किए जाने वाले पृष्ठों की संख्या की कल्पना कर सकते हैं, और निश्चित रूप से, इन पृष्ठों के बीच की दूरी के कारण कई रिकॉर्ड पुनर्प्राप्त करने के लिए किए गए I/O संचालन की संख्या। और इस खंडित अनुक्रमणिका का उपयोग करने की इस अतिरिक्त लागत के कारण, SQL सर्वर क्वेरी अनुकूलक इस अनुक्रमणिका को अनदेखा कर देगा।
सूचकांक विखंडन प्राप्त करने के विभिन्न तरीके
SQL सर्वर हमें इंडेक्स फ़्रेग्मेंटेशन का प्रतिशत प्राप्त करने के विभिन्न तरीके प्रदान करता है। पहला तरीका इंडेक्स . में इंडेक्स फ़्रेग्मेंटेशन के प्रतिशत की जांच करना है गुण विंडो, विखंडन . के अंतर्गत टैब, जैसा कि नीचे दिखाया गया है:
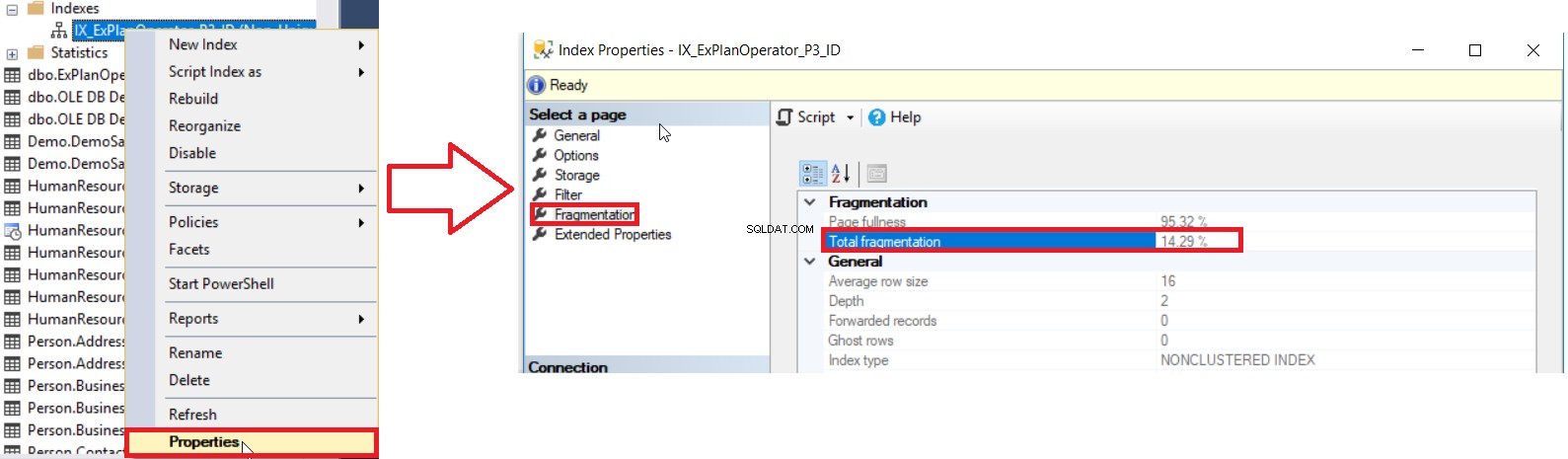
लेकिन कई इंडेक्स के विखंडन स्तर की जांच करने के लिए, आपको पहले सभी इंडेक्स के लिए यूआई विधि जांच करने की जरूरत है, जो एक समय बर्बाद करने वाला ऑपरेशन है। सभी डेटाबेस इंडेक्स के विखंडन स्तर की जांच करने के लिए दूसरी उपलब्ध विधि sys.dm_db_index_physical_stats DMF को क्वेरी कर रही है और इन इंडेक्स के बारे में सभी जानकारी पुनर्प्राप्त करने के लिए sys.indexes DMV के साथ जुड़ती है, यह ध्यान में रखते हुए कि ये आंकड़े ताज़ा हो जाएंगे जब SQL सर्वर सेवा को निम्न के समान क्वेरी का उपयोग करके पुनरारंभ किया जाता है:
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
AdventureWorks2016CTP3 . को क्वेरी करने का आउटपुट परिणाम परीक्षण डेटाबेस निम्न के जैसा होगा:
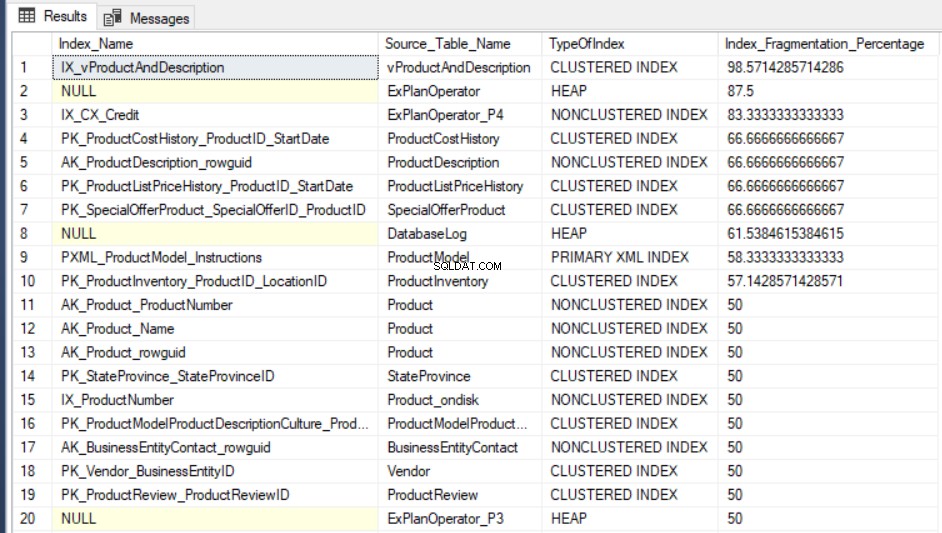
विखंडन प्रतिशत प्राप्त करने का तीसरा तरीका SQL सर्वर अंतर्निहित मानक रिपोर्ट का उपयोग करना है जिसे इंडेक्स फिजिकल स्टैटिस्टिक्स कहा जाता है। यह रिपोर्ट सूचकांक विभाजन, विखंडन प्रतिशत, प्रत्येक सूचकांक विभाजन पर पृष्ठों की संख्या, और सूचकांक के पुनर्निर्माण या पुनर्गठन द्वारा सूचकांक विखंडन मुद्दे को ठीक करने के तरीके के बारे में उपयोगी जानकारी देता है। रिपोर्ट देखने के लिए, अपने डेटाबेस पर राइट-क्लिक करें, रिपोर्ट विकल्प, मानक रिपोर्ट चुनें और नीचे दिए गए अनुसार इंडेक्स भौतिक सांख्यिकी चुनें:
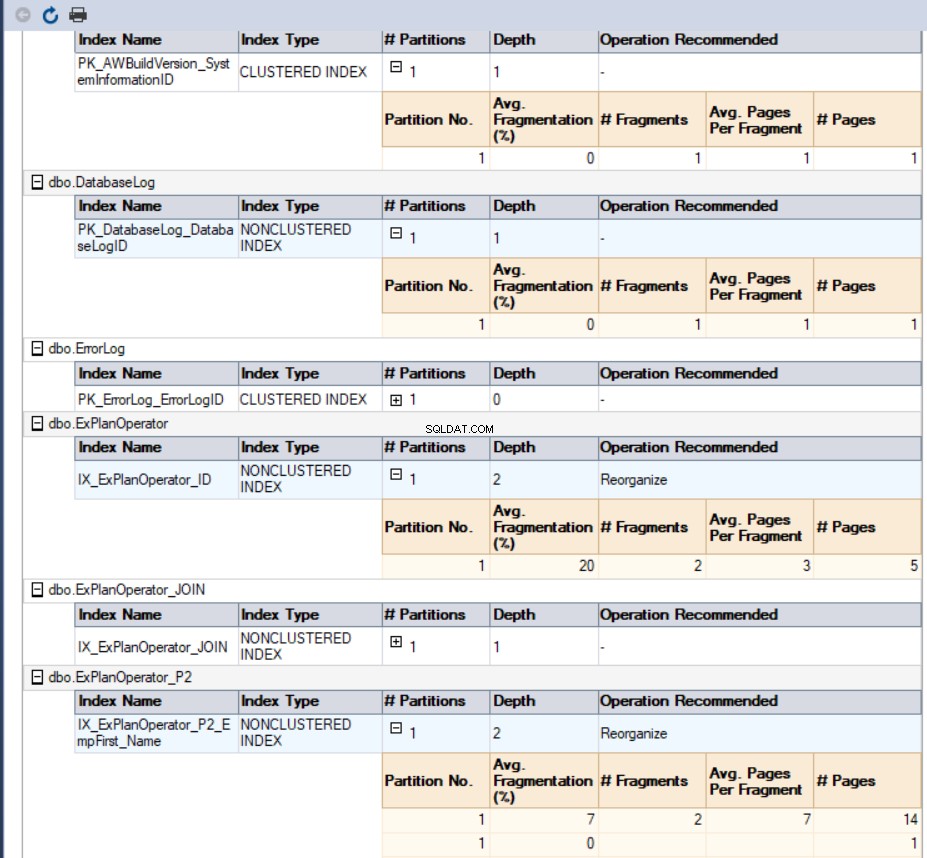
हमारे मामले में, जेनरेट की गई रिपोर्ट इस तरह दिखेगी:
सभी डेटाबेस इंडेक्स के विखंडन प्रतिशत को पुनः प्राप्त करने का अंतिम और आसान तरीका dbForge इंडेक्स मैनेजर टूल है। dbForge अनुक्रमणिका प्रबंधक टूल एक ऐड-इन है जिसे SQL सर्वर डेटाबेस इंडेक्स का विश्लेषण करने के लिए आपके SQL सर्वर मैनेजमेंट स्टूडियो में जोड़ा जा सकता है, जो आपको इन इंडेक्स फ़्रेग्मेंटेशन मुद्दों को ठीक करने के लिए चयनित डेटाबेस इंडेक्स और रखरखाव सुझावों की स्थिति के साथ एक बहुत ही उपयोगी रिपोर्ट प्रदान करता है।
अपने एसएसएमएस में डीबीफोर्ज इंडेक्स मैनेजर ऐड-इन स्थापित करने के बाद, आप स्कैन किए जाने वाले डेटाबेस पर राइट-क्लिक करके इसे चला सकते हैं, इंडेक्स मैनेजर चुनें। , फिर इंडेक्स फ़्रेग्मेंटेशन प्रबंधित करें जैसा कि नीचे दिखाया गया है:
डीबीफोर्ज इंडेक्स मैनेजर टूल आपको चयनित डेटाबेस इंडेक्स के विखंडन की एक समग्र तस्वीर प्राप्त करने की अनुमति देता है, इस समस्या को ठीक करने के लिए उचित कार्यों की सिफारिश के साथ, जैसा कि नीचे दिखाया गया है:

डीबीफोर्ज इंडेक्स मैनेजर टूल आपको डेटाबेस के बीच स्विच करने की भी अनुमति देता है, इस डेटाबेस को स्कैन करने के बाद आपको एक नई रिपोर्ट प्रदान करता है जैसा कि नीचे दिखाया गया है:
डीबीफोर्ज इंडेक्स मैनेजर टूल द्वारा उत्पन्न इंडेक्स फ्रैगमेंटेशन रिपोर्ट को एक सीएसवी फाइल में निर्यात किया जा सकता है ताकि इंडेक्स फ्रैगमेंटेशन स्थिति का विश्लेषण किया जा सके, जैसा कि नीचे दिखाया गया है:
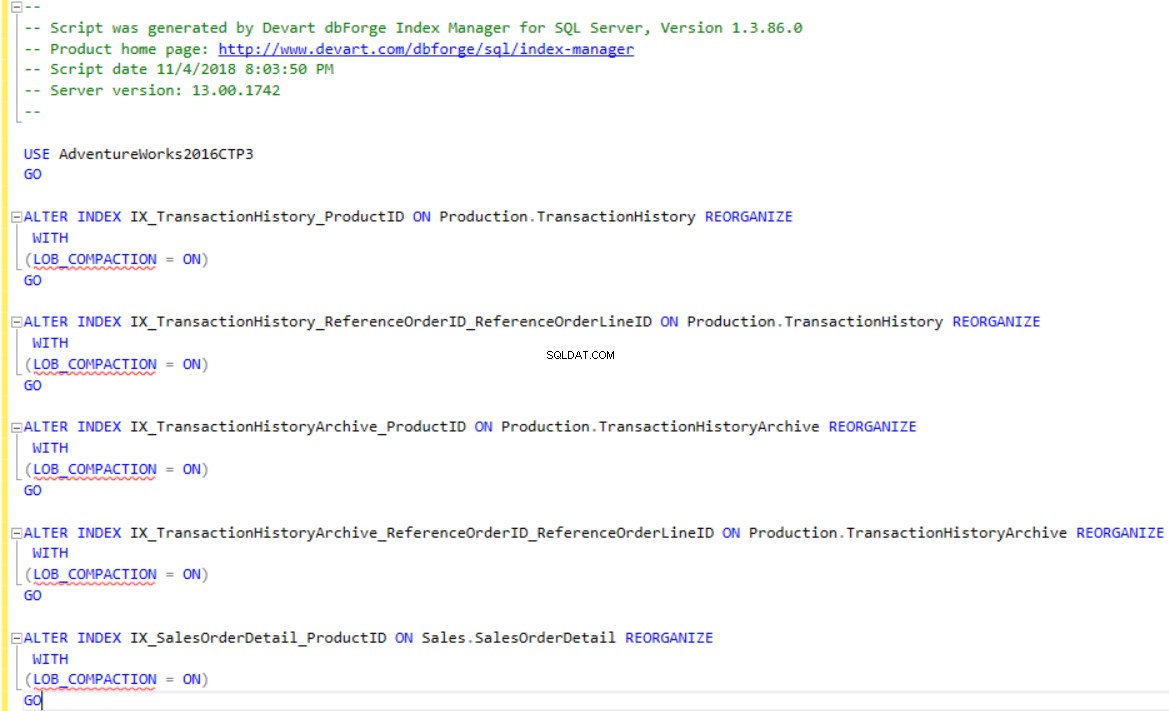
dbForge इंडेक्स मैनेजर आपको टूल अनुशंसा के अनुसार इंडेक्स को पुनर्निर्माण या पुनर्गठित करने के लिए टी-एसक्यूएल स्क्रिप्ट उत्पन्न करने की अनुमति देता है। स्क्रिप्ट परिवर्तन का उपयोग करें खंडित इंडेक्स के लिए स्क्रिप्ट दिखाने या सहेजने का विकल्प, जैसा कि नीचे दिखाया गया है:
dbForge इंडेक्स मैनेजर टूल आपको फिक्स पर क्लिक करके सीधे इंडेक्स फ्रैगमेंटेशन समस्या को ठीक करने की क्षमता प्रदान करता है। बटन जो अनुशंसित क्रिया को सीधे चयनित अनुक्रमणिकाओं पर निष्पादित करेगा, जो परिणाम पर फिक्सिंग स्थिति दिखाएगा कॉलम जैसा कि नीचे दिखाया गया है:

यदि आप पुन:विश्लेषण करें . पर क्लिक करते हैं बटन, यह फिक्स ऑपरेशन को सफलतापूर्वक करने के बाद डेटाबेस पर इंडेक्स विखंडन को फिर से स्कैन करेगा। इस लेख में जो यहां सूचीबद्ध है, वह सिर्फ एक परिचय है कि कैसे dbForge इंडेक्स मैनेजर टूल हमें इंडेक्स फ्रैगमेंटेशन मुद्दों की पहचान करने और उन्हें ठीक करने में मदद करेगा। आपके लिए मेरा सुझाव है कि इसे डाउनलोड करें और जांचें कि यह टूल आपको क्या प्रदान कर सकता है।
उपयोगी कड़ियाँ:
- सूचकांक की मूल बातें
- सूचकांक के प्रकार
- क्लस्टर और गैर-क्लस्टर इंडेक्स का वर्णन किया गया है
- संकुल अनुक्रमणिका संरचनाएं
उपयोगी टूल:
डीबीफोर्ज इंडेक्स मैनेजर - एसक्यूएल इंडेक्स की स्थिति का विश्लेषण करने और इंडेक्स विखंडन के साथ मुद्दों को ठीक करने के लिए आसान एसएसएमएस ऐड-इन।