संबंधपरक डेटाबेस तालिका में एक संगठन के डेटा का प्रतिनिधित्व करते हैं जो विभिन्न डेटा प्रकारों के साथ कॉलम का उपयोग करते हैं जिससे उन्हें मान्य मान संग्रहीत करने की अनुमति मिलती है। बेहतर क्वेरी प्रदर्शन के लिए डेवलपर्स और डीबीए को प्रत्येक कॉलम के लिए उपयुक्त डेटा प्रकार को जानना और समझना होगा।
यह लेख लोकप्रिय डेटा प्रकारों VARCHAR () और NVARCHAR (), उनकी तुलना, और SQL सर्वर में प्रदर्शन समीक्षाओं से निपटेगा।
VARCHAR [ ( n | अधिकतम )] एसक्यूएल में
VARCHAR डेटा प्रकार गैर-यूनिकोड का प्रतिनिधित्व करता है चर-लंबाई स्ट्रिंग डेटा प्रकार। आप इसमें अक्षरों, संख्याओं और विशेष वर्णों को स्टोर कर सकते हैं।
- एन बाइट्स में स्ट्रिंग आकार का प्रतिनिधित्व करता है।
- VARCHAR डेटा प्रकार कॉलम अधिकतम 8000 गैर-यूनिकोड वर्णों को संग्रहीत करता है।
- VARCHAR डेटा प्रकार प्रति वर्ण 1 बाइट लेता है। यदि आप N के लिए स्पष्ट रूप से मान निर्दिष्ट नहीं करते हैं, तो यह 1-बाइट संग्रहण लेता है।
नोट:भ्रमित न हों N एक स्ट्रिंग में वर्णों की संख्या का प्रतिनिधित्व करने वाले मान के साथ।
निम्न क्वेरी 100 बाइट्स डेटा के साथ VARCHAR डेटा प्रकार को परिभाषित करती है।
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
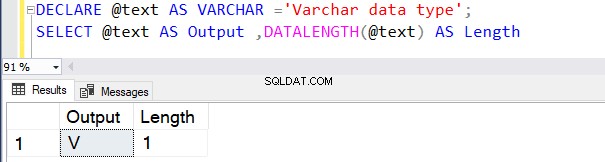
यह स्पेस कैरेक्टर सहित 1 बाइट प्रति कैरेक्टर की वजह से लंबाई 17 देता है।
निम्न क्वेरी N . के किसी भी मान के बिना VARCHAR डेटा प्रकार को परिभाषित करती है . इसलिए, SQL सर्वर डिफ़ॉल्ट मान को 1 बाइट मानता है, जैसा कि नीचे दिखाया गया है।
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
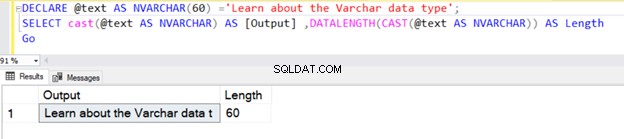
हम VARCHAR का उपयोग CAST या CONVERT फ़ंक्शन का उपयोग करके भी कर सकते हैं। उदाहरण के लिए, नीचे दिए गए दो उदाहरणों में, हमने 100 बाइट्स लंबाई वाला एक वैरिएबल घोषित किया और बाद में CAST ऑपरेटर का उपयोग किया।
पहली क्वेरी की लंबाई 30 है क्योंकि हमने CAST ऑपरेटर VARCHAR डेटा प्रकार में N निर्दिष्ट नहीं किया है। डिफ़ॉल्ट लंबाई 30 है।
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
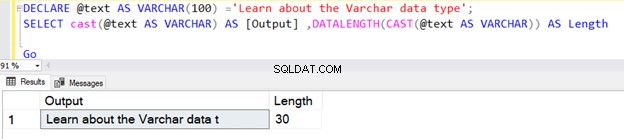
हालाँकि, यदि स्ट्रिंग की लंबाई 30 से कम है, तो यह स्ट्रिंग का वास्तविक आकार लेती है।

NVARCHAR [ ( n | अधिकतम )] एसक्यूएल में
NVARCHAR डेटा प्रकार यूनिकोड . के लिए है चर-लंबाई वर्ण डेटा प्रकार। यहां, एन राष्ट्रीय भाषा चरित्र सेट को संदर्भित करता है और यूनिकोड स्ट्रिंग को परिभाषित करने के लिए उपयोग किया जाता है। आप गैर-यूनिकोड और यूनिकोड दोनों वर्णों (जापानी कांजी, कोरियाई हंगुल, आदि) को संग्रहीत कर सकते हैं।
- एन बाइट्स में स्ट्रिंग आकार का प्रतिनिधित्व करता है।
- यह अधिकतम 4000 यूनिकोड और गैर-यूनिकोड वर्णों को संग्रहीत कर सकता है।
- VARCHAR डेटा प्रकार प्रति वर्ण 2 बाइट्स लेता है। यदि आप N के लिए कोई मान निर्दिष्ट नहीं करते हैं तो इसमें 2 बाइट्स का संग्रहण होता है।
निम्न क्वेरी 100 बाइट्स डेटा के साथ VARCHAR डेटा प्रकार को परिभाषित करती है।
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
यह 36 की स्ट्रिंग लंबाई लौटाता है क्योंकि NVARCHAR प्रति वर्ण संग्रहण में 2 बाइट लेता है।
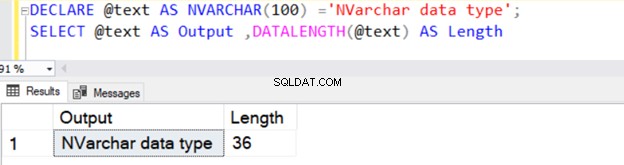
VARCHAR डेटा प्रकार के समान, NVARCHAR में N के लिए एक स्पष्ट मान निर्दिष्ट किए बिना 1 वर्ण (2 बाइट्स) का डिफ़ॉल्ट मान भी होता है।
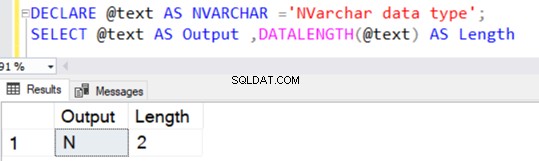
यदि हम N के किसी भी स्पष्ट मान के बिना CAST या CONVERT फ़ंक्शन का उपयोग करके NVARCHAR कन्वर्ट लागू करते हैं, तो डिफ़ॉल्ट मान 30 वर्ण, यानी 60 बाइट्स है।
यूनिकोड और गैर-यूनिकोड मानों को VARCHAR डेटा प्रकार में संग्रहीत करना
मान लीजिए हमारे पास एक टेबल है जो ई-शॉपिंग पोर्टल से ग्राहकों की प्रतिक्रिया रिकॉर्ड करती है। इस उद्देश्य के लिए, हमारे पास निम्न क्वेरी के साथ एक SQL तालिका है।
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
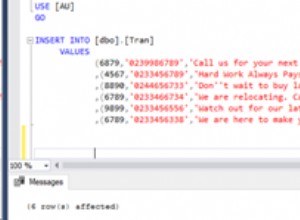
हम इस तालिका में अंग्रेजी, जापानी और हिंदी में कई नमूना रिकॉर्ड सम्मिलित करते हैं। [टिप्पणी] . के लिए डेटा प्रकार VARCHAR है और [NewComment] है NVARCHAR() ।
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
क्वेरी सफलतापूर्वक निष्पादित होती है, और इसमें से एक मान का चयन करते समय यह निम्न पंक्तियाँ देता है। दूसरी और तीसरी पंक्ति के लिए, अगर यह अंग्रेजी में नहीं है तो यह डेटा को नहीं पहचानता है।
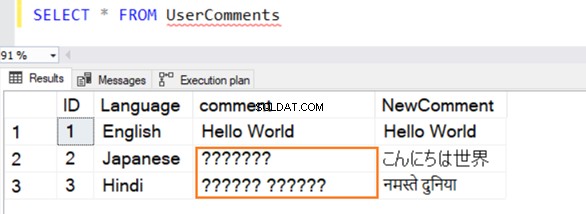
VARCHAR और NVARCHAR डेटा प्रकार:प्रदर्शन तुलना
हमें JOIN या WHERE विधेय में VARCHAR और NVARCHAR डेटा प्रकारों के उपयोग को नहीं मिलाना चाहिए। यह मौजूदा इंडेक्स को अमान्य कर देता है क्योंकि SQL सर्वर को जॉइन के दोनों किनारों पर समान डेटा प्रकार की आवश्यकता होती है। SQL सर्वर बेमेल होने की स्थिति में CONVERT_IMPLICIT() फ़ंक्शन का उपयोग करके अंतर्निहित रूपांतरण करने का प्रयास करता है।
SQL सर्वर डेटा प्रकार प्राथमिकता का उपयोग यह निर्धारित करने के लिए करता है कि लक्ष्य डेटा प्रकार कौन सा है। VARCHAR डेटा प्रकार की तुलना में NVARCHAR की उच्च प्राथमिकता है। इसलिए, डेटा प्रकार रूपांतरण के दौरान, SQL सर्वर मौजूदा VARCHAR मानों को NVARCHAR में बदल देता है।
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
अब, दो सेलेक्ट स्टेटमेंट निष्पादित करते हैं जो उनके डेटा प्रकारों के अनुसार रिकॉर्ड को पुनः प्राप्त करते हैं।
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
दोनों क्वेरी इंडेक्स सीक ऑपरेटर . का उपयोग करती हैं और इंडेक्स जिन्हें हमने पहले परिभाषित किया था।
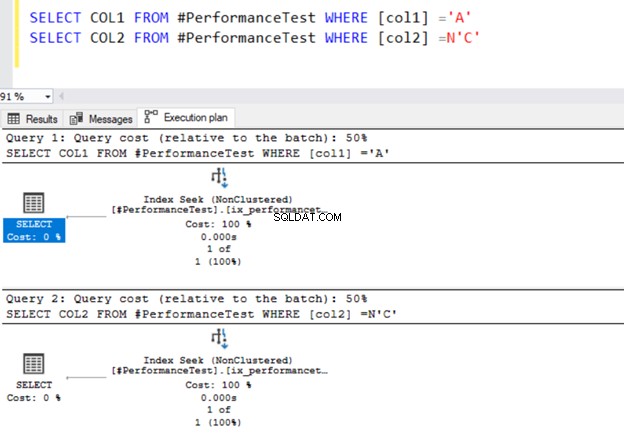
अब, हम डेटा प्रकार मानों को WHERE विधेय से तुलना करने के लिए स्विच करते हैं। कॉलम 1 में VARCHAR डेटा प्रकार है, लेकिन हम इसे NVARCHAR डेटा प्रकार के रूप में रखने के लिए N'A' निर्दिष्ट करते हैं।
इसी तरह, col2 NVARCHAR डेटा प्रकार है, और हम 'C' मान निर्दिष्ट करते हैं जो VARCHAR डेटा प्रकार को संदर्भित करता है।
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'क्वेरी वास्तविक निष्पादन योजना में, आपको एक इंडेक्स स्कैन मिलता है, और सेलेक्ट स्टेटमेंट में एक चेतावनी प्रतीक होता है।
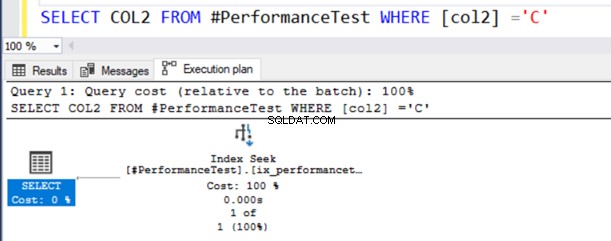
यह क्वेरी ठीक काम करती है क्योंकि NVARCHAR() डेटा प्रकार में यूनिकोड और गैर-यूनिकोड दोनों मान हो सकते हैं।
अब, दूसरी क्वेरी इंडेक्स स्कैन का उपयोग करती है और SELECT ऑपरेटर पर एक चेतावनी प्रतीक जारी करती है।
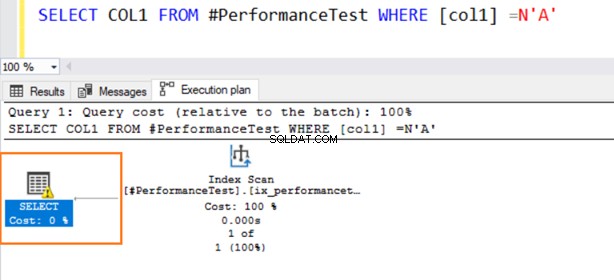
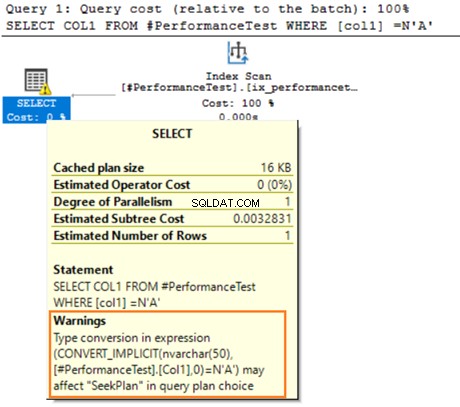
माउस को सेलेक्ट स्टेटमेंट पर होवर करें जो निहित रूपांतरण के बारे में चेतावनी जारी करता है। SQL सर्वर मौजूदा अनुक्रमणिका का ठीक से उपयोग नहीं कर सका। यह VARCHAR और NVARCHAR दोनों डेटा प्रकारों के लिए अलग-अलग डेटा सॉर्टिंग एल्गोरिदम के कारण है।
यदि तालिका में लाखों पंक्तियाँ हैं, तो SQL सर्वर को अतिरिक्त कार्य करना होगा और डेटा रूपांतरण का उपयोग करके डेटा को परोक्ष रूप से परिवर्तित करना होगा। यह आपके क्वेरी प्रदर्शन को नकारात्मक रूप से प्रभावित कर सकता है। इसलिए, आपको प्रश्नों को अनुकूलित करने में इन डेटा प्रकारों के मिश्रण और मिलान से बचना चाहिए।
निष्कर्ष
डेटाबेस टेबल और उनके कॉलम डेटा प्रकार को उचित रूप से डिजाइन करते समय आपको अपनी डेटा आवश्यकताओं की समीक्षा करनी चाहिए। आमतौर पर, VARCHAR डेटा प्रकार सर्वर आपकी अधिकांश डेटा आवश्यकताओं को पूरा करता है। हालाँकि, यदि आपको यूनिकोड और गैर-यूनिकोड दोनों प्रकार के डेटा को एक कॉलम में संग्रहीत करने की आवश्यकता है, तो आप NVARCHAR का उपयोग करने पर विचार कर सकते हैं। हालांकि, अंतिम निर्णय लेने से पहले आपको इसके प्रदर्शन निहितार्थ, भंडारण आकार की समीक्षा करनी चाहिए।