SQL सर्वर में क्वेरी ऑप्टिमाइज़ेशन क्या है? बड़ा विषय है। आधारों को कवर करने के लिए प्रत्येक तकनीक या समस्या को एक अलग लेख की आवश्यकता होती है। लेकिन जब आप अपने गेम को प्रश्नों के साथ समतल करना शुरू कर रहे हैं, तो आपको भरोसा करने के लिए कुछ आसान चाहिए। यही इस लेख का लक्ष्य है।
आप कह सकते हैं कि आपके प्रश्न इष्टतम हैं, सब कुछ अच्छा प्रदर्शन करता है, और उपयोगकर्ता खुश हैं। बेशक, प्रदर्शन ही सब कुछ नहीं है। परिणाम भी सही होने चाहिए। चाहे वह जॉइन हो, सबक्वेरी हो, पर्यायवाची हो, सीटीई हो, व्यू हो, या जो कुछ भी हो, उसे स्वीकार्य रूप से प्रदर्शन करना चाहिए।
और अंत में, आप अपने उपयोगकर्ताओं के साथ घर जा सकते हैं। आप रात भर धीमी गति से चलने वाली क्वेरी को ठीक करने के लिए कार्यालय में नहीं रहना चाहते हैं।
शुरू करने से पहले, मैं आपको विश्वास दिलाता हूं कि यात्रा कठिन नहीं होगी। यह सिर्फ एक प्राइमर होगा। हमारे पास ऐसे उदाहरण होंगे जो आपके लिए भी बहुत अलग नहीं होंगे। अंत में, जब आप गहन अध्ययन के लिए तैयार होंगे, तो हम कुछ लिंक प्रस्तुत करेंगे जिन्हें आप देख सकते हैं।
आइए शुरू करते हैं।
<एच2>1. SQL क्वेरी ऑप्टिमाइज़ेशन डिज़ाइन और आर्किटेक्चर से शुरू होता हैहैरान? जब कुछ टूटता है तो SQL क्वेरी ऑप्टिमाइज़ेशन एक विचार या बैंड-सहायता नहीं है। आपकी क्वेरी उतनी ही तेज़ी से चलती है जितनी तेज़ी से आपका डिज़ाइन अनुमति देता है। हम सामान्यीकृत तालिकाओं, सही डेटा प्रकारों, अनुक्रमणिका के उपयोग, पुराने डेटा को संग्रहीत करने और आपके द्वारा सोची जा सकने वाली किसी भी सर्वोत्तम प्रक्रिया के बारे में बात कर रहे हैं।
एक अच्छा डेटाबेस डिज़ाइन सही हार्डवेयर और SQL सर्वर सेटिंग्स के साथ तालमेल में काम करता है। क्या आपने इसे कई वर्षों तक सुचारू रूप से चलाने के लिए डिज़ाइन किया था और अभी भी नया महसूस कर रहे हैं? यह एक बड़ा सपना है, लेकिन हमारे पास इसके बारे में सोचने के लिए केवल एक निश्चित (आमतौर पर - कम) समय है।
यह उत्पादन में पहले दिन सही नहीं होगा, लेकिन हमें आधारों को कवर करना चाहिए था। हम तकनीकी ऋण को कम करेंगे। यदि आप एक टीम के साथ काम कर रहे हैं, तो यह वन-मैन शो की तुलना में बहुत अच्छा है। आप ज़्यादातर घंटियाँ और सीटी बजा सकते हैं।
फिर भी, क्या होगा यदि डेटाबेस लाइव चल रहा है और आप प्रदर्शन दीवार से टकराते हैं? यहाँ कुछ SQL क्वेरी अनुकूलन युक्तियाँ और तरकीबें दी गई हैं।
2. SQL सर्वर मानक रिपोर्ट के साथ समस्यात्मक प्रश्नों को स्पॉट करें
जब आप कोडिंग कर रहे होते हैं, तो कोड की एक लंबी श्रृंखला या एक संग्रहीत प्रक्रिया को खोजना आसान होता है। आप इसे लाइन दर लाइन डिबग कर सकते हैं। जो लाइन पिछड़ जाती है उसे ठीक करना होता है।
लेकिन क्या होगा अगर आपके हेल्पडेस्क ने एक दर्जन टिकट फेंके क्योंकि यह धीमा है? उपयोगकर्ता कोड में सटीक स्थान नहीं बता सकते हैं, और न ही हेल्पडेस्क। समय आपका सबसे बड़ा दुश्मन है।
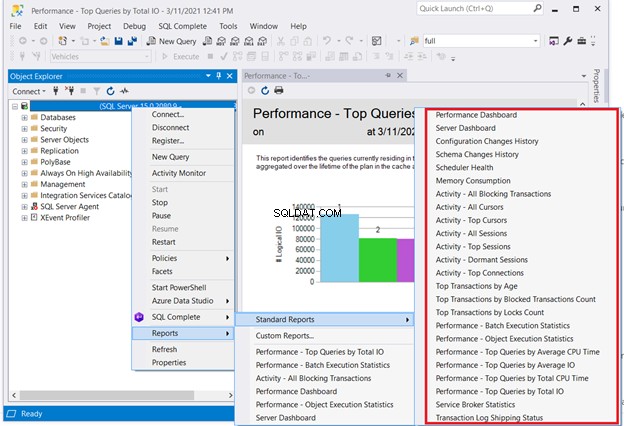
एक समाधान जिसके लिए कोडिंग की आवश्यकता नहीं होगी, वह है SQL सर्वर की मानक रिपोर्ट की जाँच करना। SQL सर्वर प्रबंधन स्टूडियो में आवश्यक सर्वर पर राइट-क्लिक करें> रिपोर्ट> मानक रिपोर्ट . हमारी रुचि का विषय प्रदर्शन डैशबोर्ड हो सकता है या प्रदर्शन - कुल I/O के आधार पर शीर्ष क्वेरी . खराब प्रदर्शन करने वाली पहली क्वेरी चुनें। फिर वहां से SQL क्वेरी ऑप्टिमाइज़ेशन या SQL प्रदर्शन ट्यूनिंग प्रारंभ करें।
3. सांख्यिकी IO के साथ SQL क्वेरी ट्यूनिंग
प्रश्न में प्रश्न को इंगित करने के बाद, आप STATISTICS IO में तार्किक पठन की जाँच शुरू कर सकते हैं। यह SQL क्वेरी ऑप्टिमाइज़ेशन टूल में से एक है।
कुछ I/O बिंदु हैं, लेकिन आपको तार्किक पढ़ने पर ध्यान देना चाहिए। तार्किक पठन जितना अधिक होगा, क्वेरी प्रदर्शन उतना ही अधिक समस्याग्रस्त होगा।
निम्नलिखित 3 कारकों को कम करके, आप SQL में प्रदर्शन ट्यूनिंग क्वेरी को तेज़ कर सकते हैं:
- उच्च तार्किक पढ़ता है,
- उच्च LOB तार्किक पढ़ता है,
- या उच्च WorkTable/WorkFile तार्किक पढ़ता है।
तार्किक पठन पर जानकारी प्राप्त करने के लिए, SQL सर्वर प्रबंधन स्टूडियो क्वेरी विंडो में सांख्यिकी IO चालू करें।
सांख्यिकी IO चालू करें
क्वेरी पूरी होने के बाद आप संदेश टैब में आउटपुट प्राप्त कर सकते हैं। चित्र 2 नमूना आउटपुट प्रदर्शित करता है:
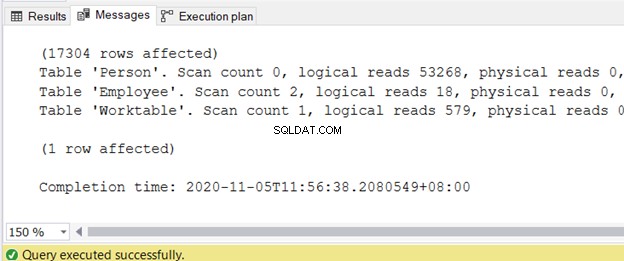
मैंने 3 गंदा I/O सांख्यिकी में तार्किक पठन को कम करने के बारे में एक अलग लेख लिखा है जो कि SQL क्वेरी प्रदर्शन को कम करता है। सटीक चरणों और उच्च तार्किक पठन वाले कोड नमूने और उन्हें कम करने के तरीकों के लिए इसका संदर्भ लें।
4. निष्पादन योजनाओं के साथ SQL क्वेरी ट्यूनिंग
लॉजिकल रीड अकेले आपको पूरी तस्वीर नहीं देगा। क्वेरी ऑप्टिमाइज़र द्वारा चुने गए चरणों की श्रृंखला आपके परिणाम सेट की कहानी बताएगी। आपके द्वारा क्वेरी निष्पादित करने के बाद यह सब कैसे शुरू होता है?
नीचे दिया गया चित्र 3 इस बात का आरेख है कि जब तक आप परिणाम सेट नहीं कर लेते, तब तक निष्पादन को ट्रिगर करने के बाद क्या होता है।
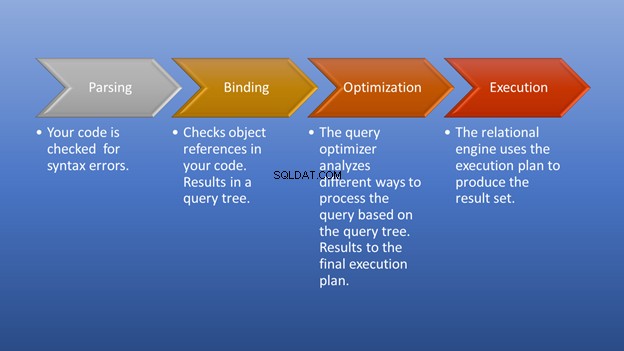
पार्सिंग और बाइंडिंग एक फ्लैश में होगी। कमाल का हिस्सा अनुकूलन चरण है, जिस पर हमारा ध्यान केंद्रित है। इस स्तर पर, क्वेरी ऑप्टिमाइज़र सर्वोत्तम संभव निष्पादन योजना का चयन करने में महत्वपूर्ण भूमिका निभाता है। यद्यपि इस भाग को कुछ संसाधनों की आवश्यकता होती है, यह एक कुशल निष्पादन योजना चुनने पर बहुत समय बचाता है। यह गतिशील रूप से होता है, क्योंकि डेटाबेस समय के साथ बदलता है। इस तरह, प्रोग्रामर इस बात पर ध्यान केंद्रित कर सकता है कि अंतिम परिणाम कैसे बनाया जाए।
प्रत्येक योजना जिसे क्वेरी अनुकूलक मानता है उसकी क्वेरी लागत होती है। कई विकल्पों में से, अनुकूलक सबसे उचित लागत वाली योजना का चयन करेगा। नोट :उचित लागत न्यूनतम लागत के बराबर नहीं है। यह भी विचार करने की आवश्यकता है कि कौन सी योजना सबसे तेज़ परिणाम देगी। कम लागत वाला प्लान हमेशा सबसे तेज नहीं होता है। उदाहरण के लिए, अनुकूलक कई प्रोसेसर कोर का उपयोग करना चुन सकता है। हम इसे समानांतर निष्पादन कहते हैं। यह अधिक संसाधनों की खपत करेगा लेकिन सीरियल निष्पादन की तुलना में तेजी से चलेगा।
विचार करने के लिए एक और बिंदु सांख्यिकी है। निष्पादन योजना बनाने के लिए क्वेरी ऑप्टिमाइज़र इस पर निर्भर करता है। यदि आंकड़े पुराने हैं, तो क्वेरी अनुकूलक से सर्वोत्तम निर्णय की अपेक्षा न करें।
जब योजना तय हो जाती है और निष्पादन आगे बढ़ता है, तो आप परिणाम देखेंगे। अब क्या?
SQL सर्वर में क्वेरी निष्पादन योजना का निरीक्षण करें
जब आप कोई प्रश्न बनाते हैं, तो आप पहले परिणाम देखना चाहते हैं। परिणाम सही होने चाहिए। जब यह हो जाए, तो आपका काम हो गया।
क्या ऐसा है?
यदि आपके पास समय की कमी है, और नौकरी दांव पर है, तो आप इसके लिए सहमत हो सकते हैं। इसके अलावा, आप हमेशा वापस आ सकते हैं। हालाँकि, यदि अन्य समस्याएं आती हैं, तो आप उन्हें बार-बार भूल सकते हैं। और फिर, अतीत का भूत आपका शिकार करेगा।
अब, सही परिणाम प्राप्त करने के बाद सबसे अच्छी बात क्या है?
वास्तविक निष्पादन योजना का निरीक्षण करें या लाइव क्वेरी आंकड़े !
उत्तरार्द्ध अच्छा है यदि आपकी क्वेरी धीमी गति से चलती है और आप देखना चाहते हैं कि पंक्तियों के संसाधित होने पर हर सेकंड क्या होता है।
कई बार स्थिति आपको तुरंत योजना का निरीक्षण करने के लिए बाध्य करेगी। प्रारंभ करने के लिए, कंट्रोल-एम press दबाएं या वास्तविक निष्पादन योजना शामिल करें . क्लिक करें SQL सर्वर प्रबंधन स्टूडियो के टूलबार से। यदि आप SQL सर्वर के लिए dbForge Studio पसंद करते हैं, तो क्वेरी प्रोफाइलर पर जाएं - यह वही जानकारी प्रदान करता है + कुछ घंटियाँ और सीटी जो आपको SSMS में नहीं मिल सकती हैं।
हमने वास्तविक निष्पादन योजना देखी है . आइए आगे बढ़ते हैं।
क्या कोई अनुक्रमणिका या अनुक्रमणिका अनुशंसाएं अनुपलब्ध हैं?
लापता इंडेक्स का पता लगाना आसान है - आपको तुरंत चेतावनी मिल जाती है।
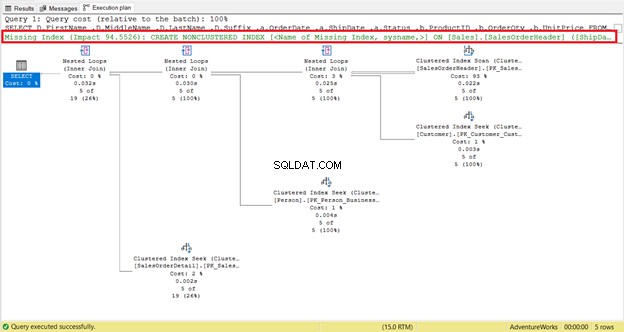
अनुक्रमणिका बनाने के लिए तत्काल कोड प्राप्त करने के लिए, अनुपलब्ध अनुक्रमणिका . पर राइट-क्लिक करें संदेश (लाल रंग में बॉक्सिंग)। फिर अनुक्रमणिका विवरण अनुपलब्ध . चुनें . लापता इंडेक्स बनाने के लिए कोड के साथ एक नई क्वेरी विंडो दिखाई देगी। इंडेक्स बनाएं।
इस भाग का पालन करना आसान है। तेजी से निष्पादन प्राप्त करने के लिए यह एक अच्छा प्रारंभिक बिंदु है। लेकिन कुछ मामलों में इसका कोई असर नहीं होगा। क्यों? आपकी क्वेरी के लिए आवश्यक कुछ कॉलम अनुक्रमणिका में नहीं हैं। इसलिए, यह एक क्लस्टर इंडेक्स स्कैन पर वापस आ जाएगा।
यह देखने के लिए कि क्या शामिल कॉलम की आवश्यकता है, इंडेक्स बनाने के बाद आपको निष्पादन योजना का पुन:निरीक्षण करना होगा। फिर, इंडेक्स को तदनुसार समायोजित करें और अपनी क्वेरी को फिर से चलाएँ। उसके बाद, निष्पादन योजना को फिर से जांचें।
लेकिन क्या होगा यदि कोई अनुक्रमणिका अनुपलब्ध न हो?
निष्पादन योजना पढ़ें
आरंभ करने के लिए आपको कुछ बुनियादी बातें जानने की आवश्यकता है:
- ऑपरेटर
- गुण
- पढ़ने की दिशा
- चेतावनी
ऑपरेटर
क्वेरी ऑप्टिमाइज़र कुछ प्रकार के मिनी-प्रोग्राम का उपयोग करता है जिन्हें ऑपरेटर कहा जाता है। आपने उनमें से कुछ को चित्र 4 में देखा है - संकुल अनुक्रमणिका खोज , संकुल अनुक्रमणिका स्कैन , नेस्टेड लूप्स , और चुनें ।
नामों, चिह्नों और विवरणों के साथ एक विस्तृत सूची प्राप्त करने के लिए, आप Microsoft से इस संदर्भ की जांच कर सकते हैं।
गुण
पर्दे के पीछे क्या हो रहा है, यह समझने के लिए ग्राफिकल आरेख पर्याप्त नहीं हैं। आपको प्रत्येक ऑपरेटर की संपत्तियों में गहराई से खुदाई करने की आवश्यकता है। उदाहरण के लिए, संकुल अनुक्रमणिका स्कैन चित्र 4 में निम्नलिखित गुण हैं:
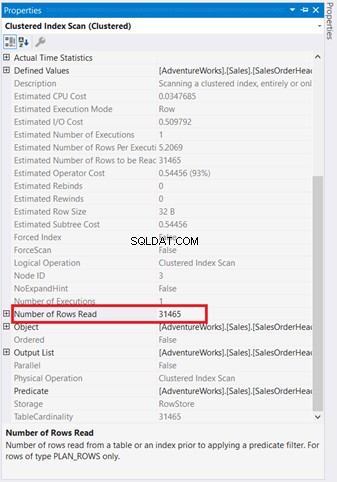
यदि आप इसकी सावधानीपूर्वक जांच करेंगे, तो संकुल अनुक्रमणिका स्कैन ऑपरेटर भयानक है। जैसा कि चित्र 5 दिखाता है, यह 31,465 पंक्तियों को पढ़ता है, लेकिन अंतिम परिणाम सेट केवल 5 पंक्तियाँ है। इसलिए, चित्र 4 में पढ़ी गई पंक्तियों की संख्या को कम करने के लिए एक अनुक्रमणिका अनुशंसा है। क्वेरी का तार्किक पठन भी अधिक है और यही कारण बताता है।
इन गुणों के बारे में अधिक जानने के लिए, सामान्य ऑपरेटर गुणों और योजना गुणों की सूची देखें।
पढ़ने की दिशा
आम तौर पर, यह जापानी मंगा को पढ़ने जैसा है - दाएं से बाएं। उन तीरों का अनुसरण करें जो बाईं ओर इंगित कर रहे हैं। यहाँ SQL सर्वर के लिए dbForge Studio से एक सरल उदाहरण दिया गया है।
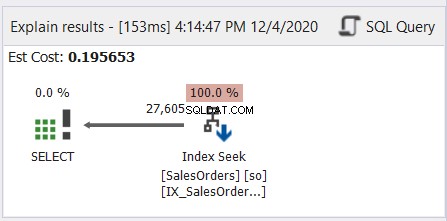
जैसा कि चित्र 6 दर्शाता है, तीर इंडेक्स सीक ऑपरेटर से बाईं ओर SELECT ऑपरेटर की ओर इशारा करता है।
हालाँकि, दाएँ से बाएँ पढ़ना हमेशा सही नहीं हो सकता है। SSMS के उदाहरण के साथ चित्र 7 देखें:
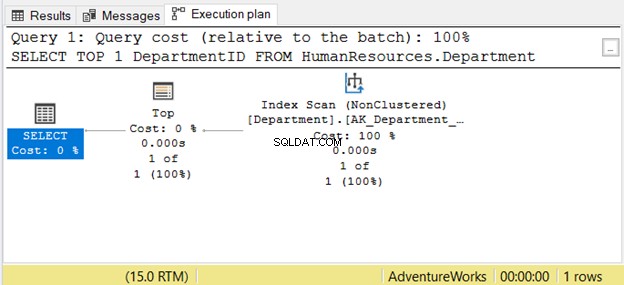
यदि आप इसे दाएं से बाएं पढ़ते हैं, तो आप देखेंगे कि सूचकांक स्कैन ऑपरेटर आउटपुट 1 पंक्ति में से 1 है। लाने के लिए सिर्फ 1 पंक्ति कैसे जान सकती है? यह शीर्ष . के कारण है ऑपरेटर। अगर हम इसे दाएं से बाएं पढ़ेंगे तो यह हमें भ्रमित करेगा।
इस मामले को बेहतर ढंग से समझने के लिए, इसे "सेलेक्ट ऑपरेटर इंडेक्स स्कैन का उपयोग करके 1 पंक्ति लाने के लिए शीर्ष का उपयोग करता है" के रूप में पढ़ें। वह बाएं से दाएं है।
हमें क्या उपयोग करना चाहिए? दाएं से बाएं या बाएं से दाएं?
यह दोनों तरह का है - जो भी आपको योजना को समझने में मदद करता है।
जबकि तीर हमें डेटा प्रवाह की दिशा देता है, इसकी मोटाई हमें डेटा के आकार के बारे में कुछ संकेत देती है। आइए फिर से चित्र 4 देखें।
संकुल अनुक्रमणिका स्कैन नेस्टेड लूप . पर जा रहे हैं दूसरों की तुलना में एक मोटा तीर है। गुण इंडेक्स स्कैन . का विवरण चित्र 5 में हमें बताएं कि यह मोटा क्यों है (5 पंक्तियों के अंतिम परिणाम के लिए 31,465 पंक्तियाँ पढ़ी जाती हैं)।
चेतावनी
निष्पादन योजना ऑपरेटर में दिखाई देने वाला एक चेतावनी आइकन हमें बताता है कि उस ऑपरेटर में कुछ बुरा हुआ है। यह अधिक संसाधनों का उपभोग करके आपके SQL क्वेरी अनुकूलन को बाधित कर सकता है।
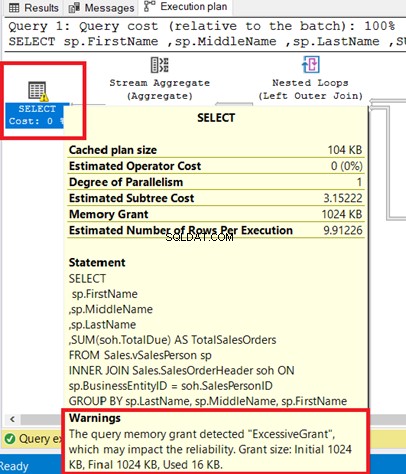
आप चयन ऑपरेटर में चेतावनी देख सकते हैं। उस ऑपरेटर पर होवर करने से चेतावनी संदेश प्रकट होता है। एक अत्यधिक अनुदान इस चेतावनी का कारण बना है।
अत्यधिक अनुदान तब होता है जब क्वेरी के लिए आरक्षित की तुलना में कम मेमोरी का उपयोग किया जाता है। अधिक जानकारी के लिए, यह Microsoft दस्तावेज़ देखें।
चित्र 8 तालिका में एक दृश्य के INNER JOIN के रूप में उपयोग की जाने वाली क्वेरी को दिखाता है। आप व्यू के बजाय बेस टेबल में शामिल होकर चेतावनी को हटा सकते हैं।
अब जब आपके पास निष्पादन योजनाओं को पढ़ने का एक बुनियादी विचार है, तो यह कैसे परिभाषित किया जाए कि आपकी क्वेरी धीमी हो जाती है?
5 कॉमन प्लान ऑपरेटर दुष्टों को जानें
आपकी क्वेरी के निष्पादन में देरी एक अपराध की तरह है। आपको इन बदमाशों का पीछा करने और उन्हें गिरफ्तार करने की जरूरत है।
<एच4>1. क्लस्टर्ड या नॉन-क्लस्टर इंडेक्स स्कैनपहला दुष्ट जिसके बारे में हर कोई सीखता है वह है संकुलित या गैर-संकुल अनुक्रमणिका स्कैन . SQL क्वेरी ऑप्टिमाइज़ेशन में इसका सामान्य ज्ञान है कि स्कैन खराब हैं और अच्छे हैं। हमने चित्र 4 में एक देखा है। अनुपलब्ध अनुक्रमणिका के कारण, संकुल अनुक्रमणिका स्कैन 5 पंक्तियाँ प्राप्त करने के लिए 31,465 पढ़ता है।
हालांकि, हमेशा ऐसा नहीं होता है। चित्र 9 में एक ही तालिका पर 2 प्रश्नों पर विचार करें। एक में खोज होगी और दूसरे के पास स्कैन होगा।
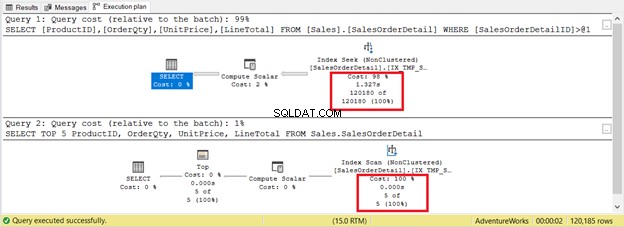
यदि आप केवल रिकॉर्ड की संख्या के आधार पर मानदंड को आधार बनाते हैं, तो इंडेक्स स्कैन केवल 5 रिकॉर्ड बनाम 120,180 के साथ जीतता है। अनुक्रमणिका खोज को निष्पादित होने में अधिक समय लगेगा।
यहाँ एक और उदाहरण है जहाँ या तो स्कैन करना या तलाश करना लगभग मायने नहीं रखता। वे एक ही टेबल से वही 6 रिकॉर्ड लौटाते हैं। तार्किक पठन समान हैं और दोनों ही मामलों में बीता हुआ समय शून्य है। तालिका केवल 6 रिकॉर्ड के साथ बहुत छोटी है। वास्तविक निष्पादन योजना शामिल करें और नीचे दिए गए कथनों को चलाएँ।
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
फिर, बाद में तुलना के लिए निष्पादन योजना को सहेजें। निष्पादन योजना पर राइट-क्लिक करें> निष्पादन योजना को इस रूप में सहेजें ।
अब, नीचे दी गई क्वेरी चलाएँ।
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
इसके बाद, निष्पादन योजना पर राइट-क्लिक करें और शोप्लान की तुलना करें . चुनें . फिर, आपके द्वारा पहले सहेजी गई फ़ाइल का चयन करें। आपके पास नीचे चित्र 10 के समान आउटपुट होना चाहिए।
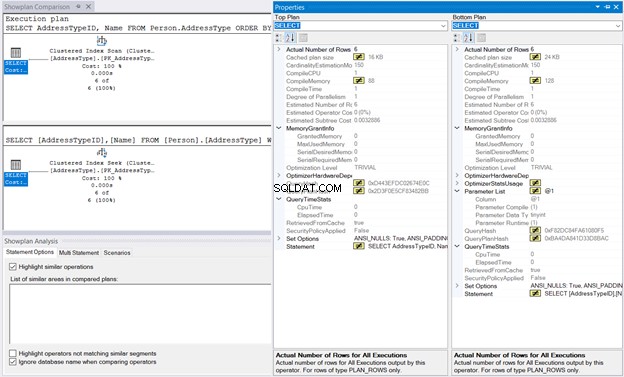
मेमोरीग्रांट और QueryTimeStats समान हैं। 128KB संकलन स्मृति संकुल अनुक्रमणिका खोज . में उपयोग किया गया संकुल अनुक्रमणिका स्कैन . के 88KB की तुलना में लगभग नगण्य है। तुलना करने के लिए इन आंकड़ों के बिना, निष्पादन समान महसूस होगा।
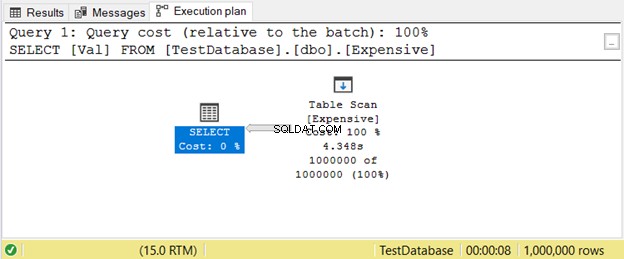
<एच4>2. टेबल स्कैन से बचनाऐसा तब होता है जब आपके पास कोई index. इंडेक्स का उपयोग करके मूल्यों की तलाश करने के बजाय, SQL सर्वर पंक्तियों को एक-एक करके तब तक स्कैन करेगा जब तक कि आपकी क्वेरी में आपको जो चाहिए वह प्राप्त न हो जाए। यह बड़ी टेबल पर बहुत पिछड़ जाएगा। उपयुक्त अनुक्रमणिका जोड़ना आसान समाधान है।
यहां टेबल स्कैन के साथ निष्पादन योजना का एक उदाहरण दिया गया है चित्र 11 में ऑपरेटर।
 <एच4>3. क्रमबद्ध प्रदर्शन प्रबंधित करना
<एच4>3. क्रमबद्ध प्रदर्शन प्रबंधित करना जैसा कि नाम से ही आता है, यह पंक्तियों के क्रम को बदल देता है। यह एक महंगा ऑपरेशन हो सकता है।
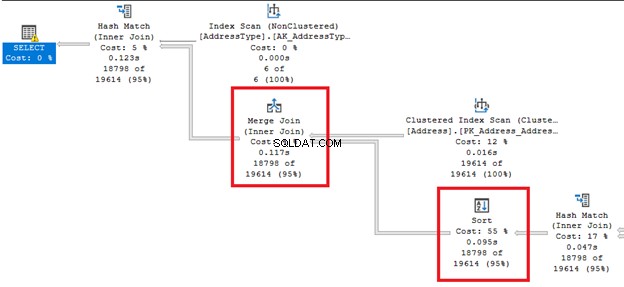
क्रमबद्ध करें . के दाएं और बाएं से उन मोटी तीर रेखाओं को देखें ऑपरेटर। चूंकि क्वेरी अनुकूलक ने मर्ज जॉइन . करने का निर्णय लिया है , एक क्रमित करें आवश्यक है। यह भी ध्यान दें कि सभी ऑपरेटरों (55%) की तुलना में इसकी सबसे अधिक प्रतिशत लागत है।
यदि SQL सर्वर को पंक्तियों को कई बार क्रमित करने की आवश्यकता होती है, तो क्रमबद्ध करना अधिक परेशानी भरा हो सकता है। यदि आपकी तालिका क्वेरी आवश्यकता के आधार पर पूर्व-क्रमबद्ध है तो आप इस ऑपरेटर से बच सकते हैं। या आप किसी एक क्वेरी को कई में विभाजित कर सकते हैं।
<एच4>4. मुख्य लुकअप हटाएंपहले चित्र 4 में, SQL सर्वर ने एक और अनुक्रमणिका जोड़ने की अनुशंसा की थी। मैंने यह किया, लेकिन इसने मुझे वह नहीं दिया जो मैं चाहता था। इसके बजाय, इसने मुझे एक इंडेक्स सीक . दिया कुंजी लुकअप . के साथ युग्मित नई अनुक्रमणिका में ऑपरेटर।
इसलिए, नई अनुक्रमणिका ने एक अतिरिक्त चरण जोड़ा।
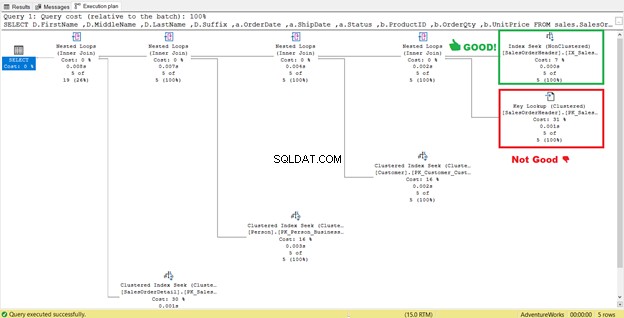
यह क्या करता है कुंजी लुकअप ऑपरेटर करते हैं?
क्वेरी प्रोसेसर ने चित्र 13 में हरे रंग में बॉक्स किए गए एक नए गैर-संकुल अनुक्रमणिका का उपयोग किया। चूंकि हमारी क्वेरी के लिए ऐसे स्तंभों की आवश्यकता होती है जो नई अनुक्रमणिका में नहीं हैं, इसलिए उसे कुंजी लुकअप की सहायता से उन डेटा को प्राप्त करने की आवश्यकता होती है। संकुल सूचकांक से हम इसके बारे में कैसे जानते हैं? अपने माउस को कुंजी लुकअप . पर मँडराते हुए इसके कुछ गुणों को प्रकट करता है और हमारी बात को सिद्ध करता है।
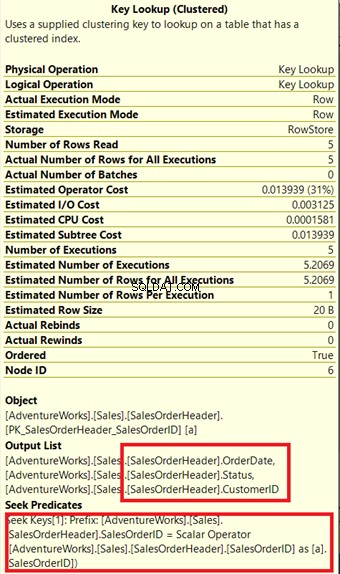
चित्र 14 में, आउटपुट सूची पर ध्यान दें। हमें PK_SalesOrderHeader_SalesOrderID का उपयोग करके 3 कॉलम पुनर्प्राप्त करने की आवश्यकता है संकुल सूचकांक। इसे हटाने के लिए, आपको इन कॉलमों को नई अनुक्रमणिका में शामिल करना होगा। इन कॉलमों को शामिल करने के बाद नई योजना यहां दी गई है।
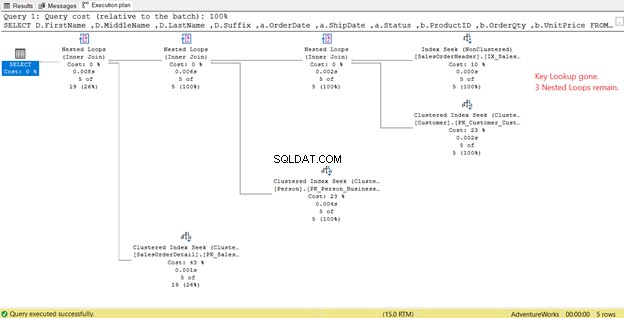
चित्र 14 में, हमने 4 नेस्टेड लूप्स saw देखे . चौथे की जरूरत है जोड़ा कुंजी लुकअप . के लिए . लेकिन नई अनुक्रमणिका में शामिल कॉलम के रूप में 3 कॉलम जोड़ने के बाद, केवल 3 नेस्टेड लूप्स बने रहें, और कुंजी लुकअप हटा दी है। हमें किसी अतिरिक्त कदम की आवश्यकता नहीं है।
5. SQL सर्वर निष्पादन योजना में समानांतरवाद
अब तक, आपने धारावाहिक निष्पादन में निष्पादन योजनाएँ देखीं। लेकिन यहाँ वह योजना है जो समानांतर निष्पादन का लाभ उठाती है। इसका मतलब है कि क्वेरी को चलाने के लिए क्वेरी ऑप्टिमाइज़र द्वारा 1 से अधिक प्रोसेसर का उपयोग किया जाता है। जब हम समानांतर निष्पादन का उपयोग करते हैं, तो हम समानांतरता देखते हैं योजना में ऑपरेटरों, और अन्य परिवर्तन भी।
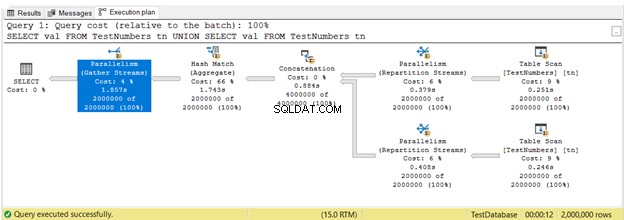
चित्र 16 में, 3 समानांतरता ऑपरेटरों का इस्तेमाल किया। यह भी ध्यान दें कि टेबल स्कैन ऑपरेटर आइकन थोड़ा अलग है। ऐसा तब होता है जब समानांतर निष्पादन का उपयोग किया जाता है।
समानांतरवाद स्वाभाविक रूप से बुरा नहीं है। यह अधिक प्रोसेसर कोर का उपयोग करके प्रश्नों की गति को बढ़ाता है। हालाँकि, यह अधिक CPU संसाधनों का उपयोग करता है। जब आपके बहुत से प्रश्न समांतरता का उपयोग करते हैं, तो यह सर्वर को धीमा कर देता है। आप अपने SQL सर्वर में समांतरता सेटिंग के लिए लागत सीमा की जांच करना चाह सकते हैं।
5. SQL क्वेरी अनुकूलन के लिए सर्वोत्तम अभ्यास
अब तक, हमने SQL क्वेरी ऑप्टिमाइज़ेशन को उन तरीकों से निपटाया है जो उन समस्याओं का पता लगाते हैं जिन्हें खोजना मुश्किल है। लेकिन इसे कोड में स्पॉट करने के तरीके हैं। यहाँ SQL में कुछ कोड की महक दी गई है।
चयन का उपयोग करना *
जल्दी में? तब टाइप करना * कॉलम नाम निर्दिष्ट करने से आसान हो सकता है। हालाँकि, एक पकड़ है। जिन कॉलमों की आपको आवश्यकता नहीं है, वे आपकी क्वेरी से पीछे रह जाएंगे।
सबूत है। चित्र 15 के लिए मैंने जो नमूना प्रश्न इस्तेमाल किया वह यह है:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
हमने इसे पहले ही ऑप्टिमाइज़ कर दिया है। लेकिन चलिए इसे SELECT **
. में बदलते हैंUSE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
यह छोटा है, ठीक है, लेकिन नीचे निष्पादन योजना देखें:
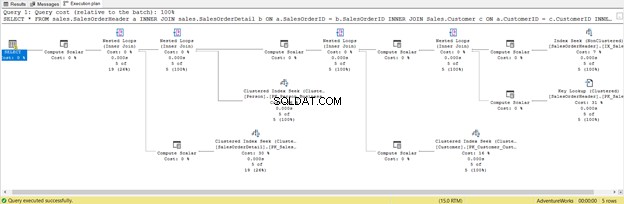
यह उन सभी स्तंभों को शामिल करने का परिणाम है, जिनकी आपको आवश्यकता नहीं है। यह कुंजी लुकअप returned लौटा और ढेर सारे गणना स्केलर . संक्षेप में, इस क्वेरी का भार बहुत अधिक है और परिणामस्वरूप यह पिछड़ जाएगा। चयन ऑपरेटर में भी चेतावनी पर ध्यान दें। यह पहले नहीं था। क्या बेकार है!
WHERE क्लॉज या जॉइन में कार्य करता है
एक अन्य कोड गंध WHERE क्लॉज में एक फ़ंक्शन कर रही है। समान परिणाम सेट वाले निम्नलिखित 2 चयन कथनों पर विचार करें। अंतर WHERE क्लॉज में है।
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
पहला चयन जुलाई 2011 के भीतर जहाज की तारीखों को इंगित करने के लिए वर्ष और माह दिनांक कार्यों का उपयोग करता है। दूसरा चयन कथन दिनांक अक्षर के साथ ऑपरेटर के बीच का उपयोग करता है।
पहले SELECT स्टेटमेंट में चित्र 4 के समान एक निष्पादन योजना होगी, लेकिन सूचकांक की सिफारिश के बिना। दूसरे में चित्र 15 के समान बेहतर निष्पादन योजना होगी।
जो बेहतर अनुकूलित है वह स्पष्ट है।
वाइल्डकार्ड का उपयोग
वाइल्डकार्ड हमारे SQL क्वेरी अनुकूलन को कितना प्रभावित कर सकते हैं? आइए एक उदाहरण लेते हैं।
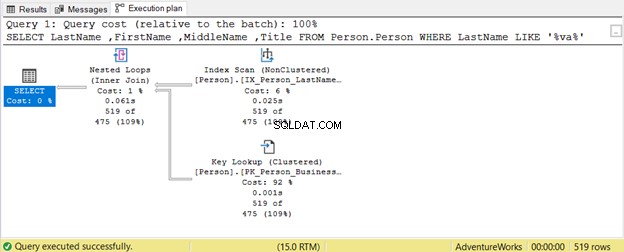
क्वेरी अंतिम नाम . के भीतर एक स्ट्रिंग की उपस्थिति देखने का प्रयास करती है किसी भी स्थिति में। इसलिए, अंतिम नाम LIKE '%va%' . यह बड़ी तालिकाओं पर अक्षम है क्योंकि उस स्ट्रिंग की उपस्थिति के लिए पंक्तियों का एक-एक करके निरीक्षण किया जाएगा। इसीलिए एक इंडेक्स स्कैन प्रयोग किया जाता है। चूंकि किसी भी अनुक्रमणिका में शीर्षक . शामिल नहीं है कॉलम, एक कुंजी लुकअप का भी उपयोग किया जाता है।
इसे डिज़ाइन द्वारा ठीक किया जा सकता है।
क्या कॉलिंग ऐप को इसकी आवश्यकता है? या यह LIKE 'va%' का उपयोग करने के लिए पर्याप्त होगा?
LIKE 'va%' एक इंडेक्स सीक . का उपयोग करता है क्योंकि तालिका में अंतिम नाम . पर एक अनुक्रमणिका है , प्रथम नाम , और मध्य नाम ।
क्या आप रिकॉर्ड पढ़ने को कम करने के लिए WHERE क्लॉज में और फ़िल्टर भी जोड़ सकते हैं?
इन प्रश्नों के आपके उत्तर इस प्रश्न को ठीक करने में आपकी सहायता करेंगे।
अंतर्निहित रूपांतरण
SQL सर्वर मूल्यों की तुलना करते समय डेटा प्रकारों को समेटने के लिए पर्दे के पीछे अंतर्निहित रूपांतरण करता है। उदाहरण के लिए, बिना कोट्स के एक स्ट्रिंग कॉलम में एक नंबर असाइन करना सुविधाजनक है। लेकिन एक पकड़ है। जब आप WHERE क्लॉज में किसी फ़ंक्शन का उपयोग करते हैं तो प्रभाव समान होता है।
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner NVARCHAR(15) है लेकिन एक संख्या के बराबर है। यह अंतर्निहित रूपांतरण के कारण सफलतापूर्वक चलेगा। लेकिन नीचे चित्र 19 में निष्पादन योजना पर ध्यान दें।
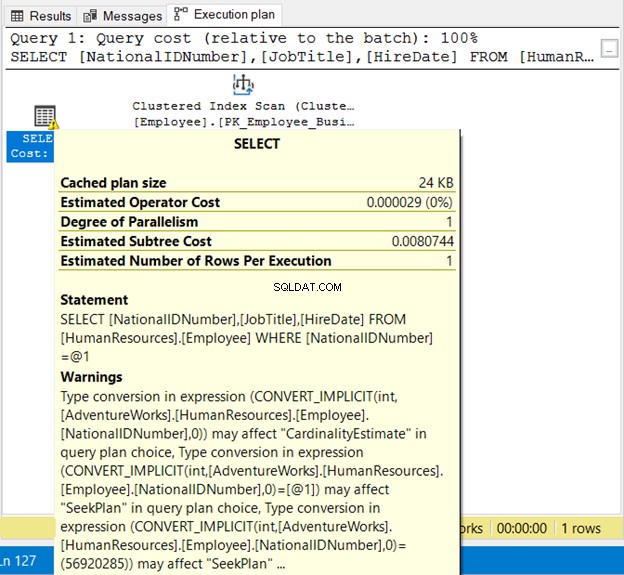
हम यहां 2 बुरी चीजें देखते हैं। सबसे पहले, चेतावनी। फिर, इंडेक्स स्कैन . इंडेक्स स्कैन अंतर्निहित रूपांतरण के कारण हुआ। इस प्रकार, स्ट्रिंग को उद्धरणों में संलग्न करना सुनिश्चित करें या स्तंभ के समान डेटा प्रकार के साथ शाब्दिक मानों का परीक्षण करें।
SQL क्वेरी ऑप्टिमाइज़ेशन टेकअवे
इतना ही। क्या SQL क्वेरी ऑप्टिमाइज़ेशन की मूल बातें आपको अपने प्रश्नों के लिए थोड़ा तैयार महसूस कराती हैं? आइए एक संक्षिप्त विवरण लें।
- यदि आप अपने प्रश्नों को अनुकूलित करना चाहते हैं, तो एक अच्छे डेटाबेस डिज़ाइन के साथ शुरुआत करें।
- यदि डेटाबेस पहले से ही उत्पादन में है, तो SQL सर्वर मानक रिपोर्ट का उपयोग करके समस्याग्रस्त प्रश्नों का पता लगाएं।
- सांख्यिकी आईओ से तार्किक पठन के साथ धीमी क्वेरी का प्रभाव कितना बड़ा है जानें।
- निष्पादन योजनाओं के साथ अपनी धीमी क्वेरी की कहानी को गहराई से जानें।
- 4 कोड की गंध देखें जो आपके प्रश्नों को धीमा कर देती हैं।
धीमी क्वेरी को तेजी से चलाने के लिए अन्य SQL क्वेरी अनुकूलन युक्तियाँ हैं। जैसा कि मैंने शुरुआत में कहा था, यह एक बड़ा विषय है। तो, हमें कमेंट सेक्शन में बताएं कि हमने और क्या मिस किया।
और अगर आपको यह पोस्ट पसंद आए तो इसे अपने पसंदीदा सोशल मीडिया प्लेटफॉर्म पर शेयर करें।
पिछले लेखों से अधिक SQL क्वेरी अनुकूलन
यदि आपको अधिक उदाहरणों की आवश्यकता है, तो SQL सर्वर में क्वेरी अनुकूलन तकनीकों से संबंधित कुछ उपयोगी पोस्ट यहां दी गई हैं।
- क्या सबक्वेरी प्रदर्शन के लिए खराब हैं? एसक्यूएल सर्वर में सबक्वेरी का उपयोग कैसे करें पर आसान गाइड देखें ।
- पदानुक्रम आईडी बनाम पैरेंट/चाइल्ड डिज़ाइन का उपयोग करना - जो तेज़ है? पर जाएँ आसान उदाहरणों के माध्यम से SQL सर्वर पदानुक्रम आईडी का उपयोग कैसे करें ।
- क्या ग्राफ़ डेटाबेस क्वेरी रीयल-टाइम अनुशंसा प्रणाली में अपने रिलेशनल समकक्षों से बेहतर प्रदर्शन कर सकते हैं? देखें SQL सर्वर ग्राफ़ डेटाबेस सुविधाओं का उपयोग कैसे करें ।
- कौन सा तेज़ है:COALESCE या ISNULL? एसक्यूएल COALESCE फ़ंक्शन पर 5 ज्वलंत प्रश्नों के शीर्ष उत्तर में खोजें ।
- दृश्य से चुनें बनाम आधार तालिका से चुनें - कौन सा तेज़ चलेगा? अधिक तेज़ SQL दृश्य लिखने के लिए शीर्ष 3 युक्तियाँ जो आपको जानना आवश्यक हैं, पर जाएँ ।
- CTE बनाम अस्थायी तालिकाएँ बनाम उपश्रेणियाँ। जानें कि कौन जीतेगा एक ही स्थान में SQL CTE के बारे में आपको जो कुछ जानने की आवश्यकता है ।
- WHERE क्लॉज में SQL सबस्ट्रिंग का उपयोग करना - एक प्रदर्शन ट्रैप? SQL SUBSTRING() फ़ंक्शन का उपयोग करके प्रो की तरह स्ट्रिंग्स को पार्स कैसे करें? में उदाहरणों के साथ देखें कि क्या यह सच है?
- एसक्यूएल यूनियन ऑल यूनियन से तेज है। जानिए क्यों एसक्यूएल यूनियन चीट शीट में 10 आसान और उपयोगी टिप्स के साथ ।