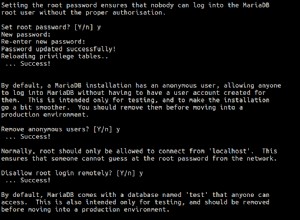
इसे समझाना थोड़ा मुश्किल है।
इंडेक्स का उपयोग करने वाली क्वेरी इसका उपयोग कर रही है क्योंकि इंडेक्स एक "कवरिंग" इंडेक्स है। यानी इंडेक्स के सभी कॉलम क्वेरी में हैं। वास्तव में प्रभावी ढंग से उपयोग किए जा रहे इंडेक्स का एकमात्र हिस्सा latitude . की स्थिति है ।
आम तौर पर एक कवरिंग इंडेक्स में केवल . होगा क्वेरी में उल्लिखित कॉलम। हालांकि, प्राथमिक कुंजी का उपयोग रिकॉर्ड्स को संदर्भित करने के लिए किया जाता है, इसलिए मैं अनुमान लगा रहा हूं कि users.Id मेज पर प्राथमिक कुंजी है। और अनुक्रमणिका को latitude . के मान्य मानों के लिए स्कैन किया जा रहा है ।
क्वेरी जो अनुक्रमणिका का उपयोग नहीं कर रही है वह दो कारणों से इसका उपयोग नहीं कर रही है। सबसे पहले, स्तंभों पर स्थितियां असमानताएं हैं। एक इंडेक्स सीक केवल समानता की स्थिति और एक असमानता का उपयोग कर सकता है। इसका मतलब है कि अनुक्रमणिका का उपयोग केवल latitude . के लिए किया जा सकता है इसकी सबसे प्रभावी विधि में। दूसरा, क्वेरी में अतिरिक्त कॉलम के लिए वैसे भी डेटा पेज पर जाने की आवश्यकता होती है।
दूसरे शब्दों में, अनुकूलक वास्तव में कह रहा है:"सूचकांक के माध्यम से स्कैन करने और फिर डेटा पृष्ठों को स्कैन करने के लिए सूचकांक में जाने से क्यों परेशान हैं? इसके बजाय, मैं केवल डेटा पृष्ठों को स्कैन कर सकता हूं और सब कुछ एक ही बार में प्राप्त कर सकता हूं।"
आपका अगला प्रश्न निस्संदेह है:"लेकिन मैं अपनी क्वेरी को तेज़ कैसे करूँ?" मेरा सुझाव स्थानिक अनुक्रमणिका ।