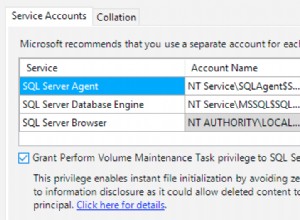
रिकॉर्ड को एक अलग तालिका में "स्वचालित रूप से" सम्मिलित करने के लिए आपको ट्रिगर्स की आवश्यकता होगी।
उपयोगकर्ता गोपनीयता में एक अलग क्वेरी के साथ रिकॉर्ड सम्मिलित करना इसे लागू करने का सबसे सामान्य तरीका होगा।
यदि यह एक-से-एक संबंध है, तो इसे एक ही तालिका में रखने से अधिक सरल प्रश्नों की अनुमति मिलती है (कोई शामिल होने की आवश्यकता नहीं है)।
निर्णय, निर्णय ...
एक-से-(शून्य से एक) संबंध के साथ, विचार करने के लिए और भी कारक हैं।
यदि उपयोगकर्ता गोपनीयता तालिका बड़ी है, तो स्थान बचाने के लिए इसे एक अलग तालिका में रखना समझदारी हो सकती है। यह अधिक सामान्यीकृत भी होगा।
यदि आप अक्सर कुछ पूछ रहे थे जैसे "मुझे वे सभी उपयोगकर्ता दें जिनके पास गोपनीयता डेटा नहीं है", तो इसे एक अलग तालिका में रखना समझ में आता है। चूंकि अनुक्रमणिका में NULL मान (डिफ़ॉल्ट रूप से) शामिल नहीं होते हैं, इसलिए एक अलग तालिका में जॉइन करना तेज़ होगा। बेशक, "कोई गोपनीयता सेटिंग नहीं" का प्रतिनिधित्व करने के लिए एनयूएलएल के अलावा किसी अन्य मूल्य का उपयोग करना है, लेकिन कम कार्डिनैलिटी भी प्रदर्शन को नकारात्मक रूप से प्रभावित करती है। इस मामले के लिए अलग टेबल सबसे अच्छा होगा।
साथ ही, यदि गोपनीयता डेटा को बार-बार अपडेट किया गया था, लेकिन उपयोगकर्ता डेटा नहीं, तो अलग-अलग तालिकाएं उपयोगकर्ता तालिका पर पंक्ति लॉक को रोक देंगी, और छोटी तालिकाओं पर अपडेट तेज़ होते हैं, जिससे प्रदर्शन में सुधार हो सकता है।
यदि आपको अक्सर UserData के बिना UserPrivacy डेटा की आवश्यकता होती है, या इसके विपरीत, तो आप उन्हें अलग करना चाह सकते हैं।
फिर भी, यह समयपूर्व अनुकूलन हो सकता है। यदि वे आपके मॉडल से बेहतर मेल खाते हैं, तो आप उन्हें अलग करना चाह सकते हैं। प्रदर्शन, आकार और पठनीयता के मुद्दों की तुलना में इसे एक ही तालिका में रखने की सादगी पर विचार करें।
यदि संबंध एक-से-(शून्य से अनेक) था, तो आप स्पष्ट रूप से एक अलग तालिका चाहते हैं, लेकिन एक-से-(शून्य से एक) के लिए, यह वैकल्पिक है।
आखिरकार...
जब तक कोई कारण हो, उन्हें अलग करने से न डरें।