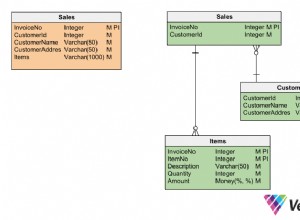
PostgreSQL के लिए, मुझे लगता है कि आप lag विंडो फ़ंक्शन
पंक्तियों की तुलना करने के लिए; यह सेल्फ़-जॉइन और फ़िल्टर की तुलना में कहीं अधिक कुशल होगा। यह MySQL के साथ काम नहीं करेगा, क्योंकि यह अभी भी मानक SQL:2003 विंडो फ़ंक्शंस का समर्थन नहीं करता है; नीचे देखें।
केवल दो निम्नतम खोजने के लिए आप dense_rank . का उपयोग कर सकते हैं टिकट पर विंडो फ़ंक्शन , फिर केवल उन पंक्तियों को वापस करने के लिए परिणामों को फ़िल्टर करें जहां dense_rank() =2 , यानी दूसरी-से-निम्नतम टाइमस्टैम्प वाली पंक्ति, जहां lag() सबसे कम टाइमस्टैम्प वाली पंक्ति तैयार करेगा।
देखें यह SQLFiddle जो नमूना डीडीएल और आउटपुट दिखाता है।
SELECT ticketid, extract(epoch from tdiff) FROM (
SELECT
ticketid,
ticketdate - lag(ticketdate) OVER (PARTITION BY ticketid ORDER BY ticketdate) AS tdiff,
dense_rank() OVER (PARTITION BY ticketid ORDER BY ticketdate) AS rank
FROM Table1
ORDER BY ticketid) x
WHERE rank = 2;
मैंने टिकट दिनांक का उपयोग किया है दिनांक कॉलम के नाम के रूप में क्योंकि तारीख कॉलम के लिए एक भयानक नाम है (यह एक डेटा प्रकार का नाम है) और इसका कभी भी उपयोग नहीं किया जाना चाहिए; इसे काम करने के लिए कई स्थितियों में दोहरा उद्धृत करना पड़ता है।
पोर्टेबल दृष्टिकोण शायद स्वयं-जुड़ने वाले अन्य लोगों ने पोस्ट किया है। उपरोक्त विंडो फ़ंक्शन दृष्टिकोण शायद ओरेकल पर भी काम करता है, लेकिन ऐसा लगता है कि MySQL में नहीं है। जहां तक मुझे पता चला है कि यह SQL:2003 विंडो फ़ंक्शंस का समर्थन नहीं करता है।
स्कीमा परिभाषा MySQL के साथ काम करेगी यदि आप SET sql_mode ='ANSI' और टाइमस्टैम्प का उपयोग करें समय क्षेत्र के साथ टाइमस्टैम्प . के बजाय . ऐसा लगता है कि खिड़की के कार्य नहीं होंगे; MySQL OVER पर चोक हो जाता है खंड। देखें यह SQLFiddle
।